【Code With SOLO】从零搭建带语义缓存的 RAG 知识库问答系统,让 PDF 教材秒变 AI 助教
1. 摘要
基于 LangChain + Vue 3 + PostgreSQL/pgvector + Redis,搭建了一套完整的 RAG(检索增强生成)知识库问答系统。支持 PDF 自动切片入库、混合检索(关键词 + 向量 RRF 融合)、多轮对话查询改写、语义缓存命中秒回、SSE 流式打字机输出。将 400+ 页安全工程教材转化为可交互的 AI 助教,相同问题二次提问毫秒级响应。
2. 背景
我是一名备考安全工程师的考生,手边有一本 400 多页的《安全生产管理》PDF 教材。平时复习时经常需要反复查找某个概念的定义、公式或事故等级划分标准,手动翻书+检索效率极低。同时也想深入实践一下 RAG 技术栈,于是决定用 SOLO 从零搭建一个私有的、带缓存加速的 PDF 智能问答系统,把教材"盘活"。
3. 实践过程
任务拆解
整个项目拆成四个阶段:
- 数据处理层:PDF 提取 → 按标题分片 → pgvector 向量入库
- RAG 引擎层:混合检索 + 查询改写 + 语义缓存 + LLM 生成
- API 服务层:Express 路由 + SSE 流式接口 + 会话管理
- 前端展示层:Vue 3 三栏布局(会话历史 / 聊天区 / 检索详情)
使用 SOLO 的关键能力
- 全栈代码生成与重构:从终端脚本到 Express API 再到 Vue 组件,SOLO 协助完成了多轮大规模重构
- Debug 与根因分析:遇到流式输出不更新、缓存不命中等 bug 时,SOLO 能快速定位到响应式代理、缓存 key 不一致等深层问题
- 架构决策辅助:在
invokevsstream、缓存策略、检索算法等关键选型上给出建议
关键技术实现
混合检索(关键词 + 向量 RRF)
// 提取关键词做字面匹配 + pgvector 相似度检索,再用 RRF 融合排序
const keywordRanked = ... // 基于 extractKeywords + includes 匹配
const vectorRanked = await vectorStore.similaritySearchWithScore(question, topK * 3);
// RRF 融合: score = Σ 1/(60 + rank)
语义缓存
用 Redis 缓存"问题向量 → 答案",二次提问时先做向量相似度比对(阈值 0.92),命中直接返回,跳过检索和 LLM 调用。
查询改写 + 改写缓存
多轮对话时,用 LLM 将当前问题结合历史改写成独立问题,避免"这个是什么意思"这类指代不清的查询。改写结果也做了 Redis 缓存(1 小时),避免重复调用 LLM。
SSE 流式输出
前端用 fetch + ReadableStream 接收 SSE,实现打字机效果;后端 model.stream() 逐 token 推送,同时穿插 status / retrieval / delta / done 事件。
踩过的坑
| 坑 | 现象 | 根因 | 修复 |
|---|---|---|---|
| 流式回答忽略长 context | AI 说"无法找到相关内容" | model.stream() 对长 system prompt 处理有异常 |
后端默认改用 model.invoke(),前端仍通过 SSE 模拟流式推送 |
| 检索面板不实时更新 | 要刷新页面才显示 | Vue 3 直接修改普通对象不触发响应式 | 改为通过 messages.value[index] 代理对象修改 |
| 缓存永远不命中 | 同样问题第二次仍走 LLM | 缓存存的是原始问题向量,查的是改写后问题向量 | 查缓存前置到查询改写之前,统一用原始问题做 key |
| 缓存命中无检索详情 | 右侧面板空白 | 语义缓存只存了 answer,没存 retrievalInfo | 扩展缓存结构,读写都带检索详情 |
4. 成果展示
技术栈
- 前端:Vue 3 + Vite + Pinia + Element Plus + KaTeX
- 后端:Express + LangChain + pgvector
- 数据:PostgreSQL(向量存储)+ Redis(语义缓存 + 会话存储 + 改写缓存)
- 模型:通过
model-config.js灵活配置(兼容 OpenAI / 智谱 / Ollama 等)
核心功能
 PDF 自动切片:按章节标题分片,支持公式上下文补全
PDF 自动切片:按章节标题分片,支持公式上下文补全 混合检索:关键词 + 向量双路召回,RRF 融合排序
混合检索:关键词 + 向量双路召回,RRF 融合排序 三级缓存:语义问答缓存(24h)+ 查询改写缓存(1h)+ 文档缓存
三级缓存:语义问答缓存(24h)+ 查询改写缓存(1h)+ 文档缓存 多轮对话:自动查询改写,保持上下文连贯
多轮对话:自动查询改写,保持上下文连贯 流式输出:SSE 逐字推送,阶段状态提示(理解问题 → 检索资料 → 生成回答)
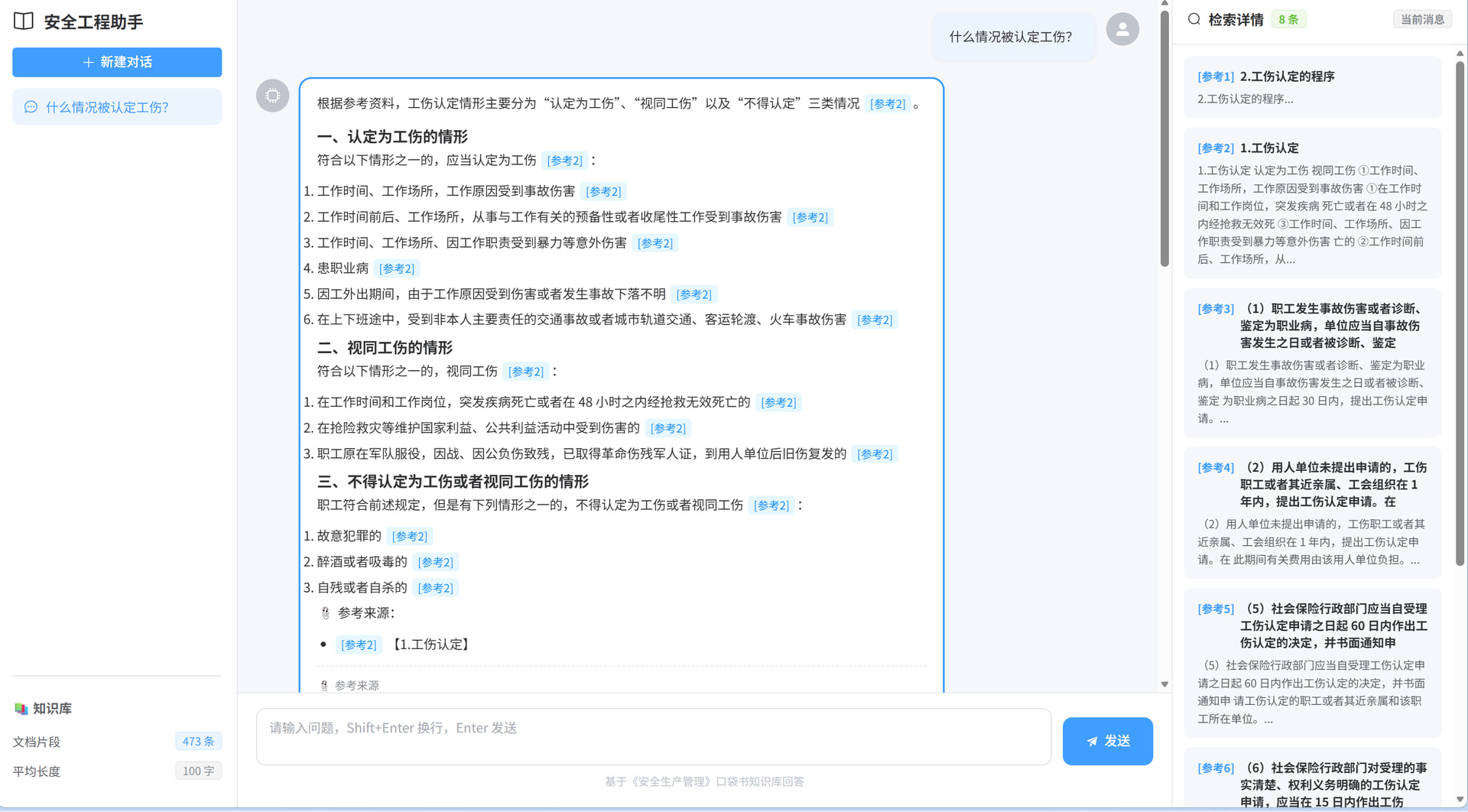
流式输出:SSE 逐字推送,阶段状态提示(理解问题 → 检索资料 → 生成回答) 溯源展示:回答中的
溯源展示:回答中的 [参考1]可点击跳转,右侧检索面板实时显示召回片段
项目结构
RAG/
├── server/
│ ├── index.js # Express 入口
│ ├── routes/
│ │ └── chat.js # SSE 聊天接口
│ ├── services/
│ │ └── ragService.js # RAG 引擎核心
│ └── utils/
│ ├── db.js # pgvector 封装
│ ├── cache.js # Redis 缓存
│ ├── pdf.js # PDF 解析
│ └── splitter.js # 按标题分片
├── web/
│ ├── src/
│ │ ├── views/ChatView.vue
│ │ ├── components/
│ │ │ ├── ChatMessage.vue
│ │ │ ├── ChatInput.vue
│ │ │ ├── RetrievalPanel.vue
│ │ │ └── Sidebar.vue
│ │ ├── stores/chatStore.js
│ │ └── api/index.js
├── .env # 模型配置
└── model-config.js # LLM / Embedding 初始化
演示效果(文字描述)
- 用户输入:
千人死亡率怎么算? - 右侧显示:检索到 5 条参考资料,包含公式定义和例题
- AI 流式输出:
千人死亡率的计算公式为:$$千人死亡率 = \frac{死亡人数}{从业人员数} \times 10^3$$ [参考1]... - 再次输入同样问题 →
[缓存命中]瞬间返回,右侧同步显示之前的检索来源
5. 效果与总结
提效数据
| 场景 | 原来 | 现在 |
|---|---|---|
| 查找教材中某个概念 | 翻书 2~5 分钟 | 提问 3 秒出结果 |
| 相同问题重复问 | 重复消耗 LLM Token | 缓存命中毫秒级响应 |
| 多轮追问(如"那这个和 A 有什么区别") | 需要手动补充上下文 | 自动改写为独立问题,检索更准确 |
SOLO 在流程中做了什么
- 0→1 搭建:从空白目录到可运行的全栈项目,SOLO 协助完成了 90% 以上的代码编写
- 架构设计:在"流式 vs 非流式""缓存策略"等关键决策上提供方案对比
- Debug 效率:遇到 Vue 响应式、缓存 key 不一致等隐蔽 bug 时,能快速定位根因而不是表面修修补补
- 代码重构:多次大规模重构(终端脚本 → API 化 → Vue 三栏)都能保持逻辑一致性
可复用的方法
- RAG 项目模板化:这套"PDF 切片 → 向量入库 → 混合检索 → 语义缓存 → 流式输出"的流水线,可以快速复用到其他专业文档(法规、论文、手册)
- 缓存前置策略:缓存检查放在最外层(查询改写之前),避免任何不必要的 LLM 调用
- SSE 分段事件:
status/retrieval/delta/done四种事件分离,前后端职责清晰
本项目使用 TRAE SOLO 辅助开发完成。