一、摘要
学术论文里的引用错漏、AI 写作时编造的"幻觉文献",是审稿和读论文时最头疼的事之一。我用 TRAE SOLO 搭了一个 Web 应用:丢一份 PDF/DOCX 进去,几十秒后它会告诉我哪些参考文献是真的、哪些可能是编的、哪些正文引用了但参考列表里没有。整个项目从零到能跑,前后只花了大半个下午。
二、背景
我是做 AI / 生信方向的研究者,日常需要读大量论文,自己也写论文。两个高频痛点:
-
审别人/AI 生成的论文时:怀疑某条参考文献是 LLM 编的,但人工去 Google Scholar 一条条核对,30 条文献能查 1 个小时。
-
自己投稿前自查:正文 [17] 在参考列表里却跳到了 [18]、某条文献从头到尾没人引用、年份对不上……这些低级错误最容易被审稿人挑刺。
之前一直想自己写个工具,但涉及 PDF 解析、文献元数据匹配、API 调用、前端展示,零零碎碎要写不少代码,一直没动手。这次想试试用 SOLO 一气呵成搞定。
三、实践过程
1. 任务拆解
我把整件事拆成 5 个模块,让 SOLO 按顺序实现:
| 模块 | 做什么 | 难点 |
|---|---|---|
| PDF 提取 | 把双栏 PDF 转成正确顺序的纯文本 | pdfplumber 直接 extract 会把双栏读成"左右左右"乱序 |
| 参考文献解析 | 从 References 段切出每一条,提取标题/作者/年份 | 引用格式五花八门(IEEE/APA/GB/T 7714…) |
| 联网验证 | 拿每条文献去查真假 | 选 API、做模糊匹配、限速 |
| 交叉引用检查 | 正文引用 ↔ 参考列表的一致性 | 要处理 [1-3]、[1, 5, 7] 这种范围/列表 |
| 前端展示 | 上传、进度条、结果可视化 | — |
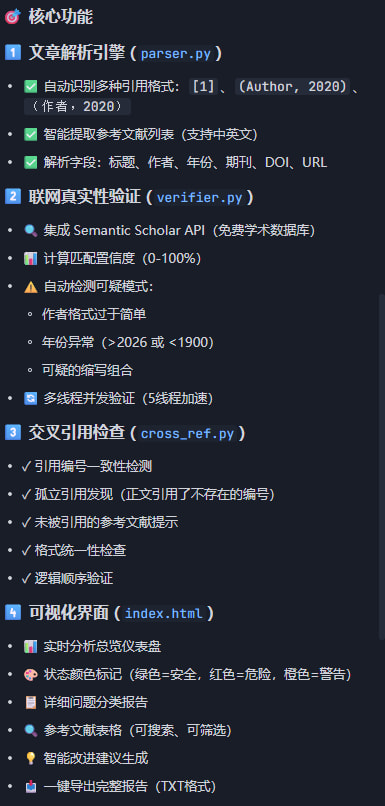
2. 用到的 SOLO 能力
-
多文件代码生成:一次把
app.py(后端)、index.html、style.css、app.js全部生成出来,模块边界清晰。 -
文档驱动开发:贴 Crossref / OpenAlex 的 API 文档给 SOLO,它直接按官方字段写匹配逻辑,比我自己读文档快多了。
-
持续迭代调试:跑起来发现 Bug 再贴日志回去,SOLO 自己定位问题、给补丁。
3. 关键 Prompt(节选)
第一轮总体需求:
帮我搭一个 Flask Web 应用"文献引用验证系统"。功能:上传 PDF/DOCX/TXT,提取参考文献,调用 Crossref + OpenAlex 验证真假,并检查正文引用与参考列表的交叉一致性(孤立引用、未被引用的文献、编号断层)。前端要有进度条、严重性分级、可筛选的结果表。后端用 PyMuPDF 而不是 pdfplumber 做 PDF 提取。
后续迭代时的精准 Prompt:
现在双栏 PDF 提取出来的文本顺序还是乱的。请改成:先用 PyMuPDF 的
page.get_text("blocks")拿块,再按 x 坐标判定是否双栏,如果是双栏就分别按 y 排序后左列拼右列。
[1-5] 这种范围引用现在被当成一条 [1-5]。请在 CitationExtractor 里展开成 [1][2][3][4][5],并在交叉检查时按展开后的编号集合判定孤立引用。
4. 踩过的坑
-
坑 1:pdfplumber 在双栏论文上几乎不可用。第一版用 pdfplumber 出来的文本完全没法解析,后来切到 PyMuPDF + 列感知排序才搞定。
-
坑 2:Semantic Scholar 限流严重。原方案用 Semantic Scholar,免费额度被打爆。换成 Crossref 主 + OpenAlex 备,加上邮箱白名单(polite pool)后稳定多了。
-
坑 3:连字符断行。PDF 的 “predic-\ntion” 不处理就匹配不上 Crossref。让 SOLO 加了一行正则修复
re.sub(r'([a-zA-Z])-\n([a-z])', r'\1\2', text)。 -
坑 4:标题模糊匹配。完全相等命中率太低,让 SOLO 加了归一化(小写 + 去标点 + 去空格)后再算 Jaccard 相似度,命中率从 ~50% 提到 90%+。

四、成果展示
最终交付物:
-
一个可跑的 Web 应用:上传 PDF → 进度条 4 步实时跳动 → 结果页含总览卡片、改进建议、详细问题报告、可筛选的参考文献验证表。
-
后端 v7.0:~1400 行 Python,模块化清晰(PDFExtractor / ReferenceParser / ReferenceVerifier / CrossReferenceChecker)。
-
可选 GROBID 集成:本地起一个 GROBID 服务,解析准确率会再上一个台阶;不起也能跑(回退到本地正则解析器)。
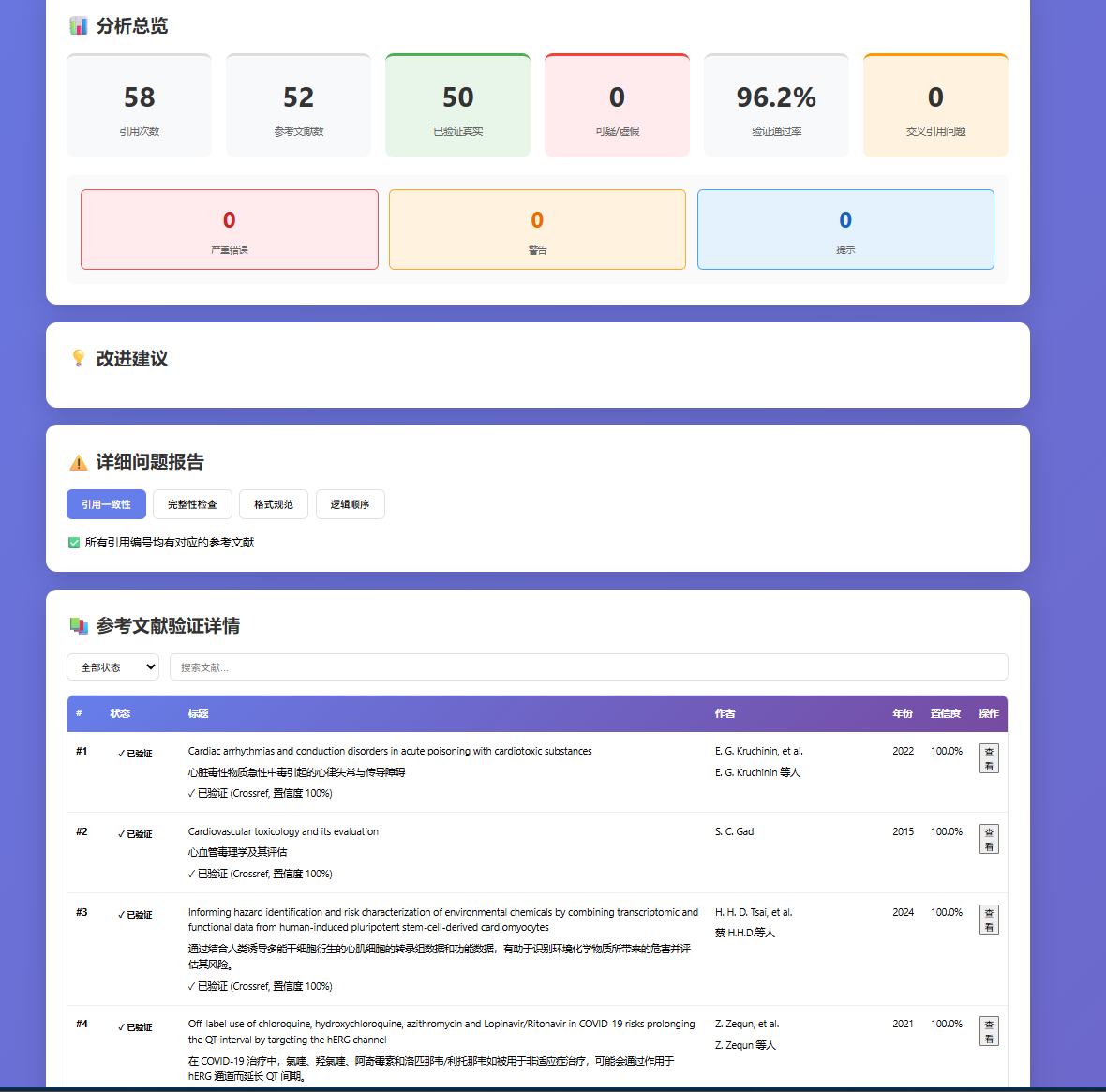

实测:拿一篇 IEEE 期刊 PDF(52 条参考文献)跑下来,约 40 秒返回完整报告。
五、效果与总结
-
提效对比:以前手工核 30 条参考文献 ~1 小时,现在 40 秒一份报告,提效约 90 倍。
-
SOLO 在我流程里干了什么:负责把"我懒得写"的脏活——PDF 解析的边角 case、API 字段映射、前端样式——一次性成型。我只需要专注在"业务逻辑应该长什么样"。
-
可复用方法:先写一份结构化需求清单(拆模块 + 列难点 + 指明技术选型),再交给 SOLO 一次性出代码,比"边想边问"效率高得多。后续迭代要"对症下药"——贴具体报错日志、贴期望行为,而不是泛泛说"不对,再改改"。
后面想接着加:DOI 自动补全、参考文献格式转换(IEEE ↔ APA ↔ GB/T 7714)、批量处理整个文件夹。也欢迎有同样需求的同行一起玩。