项目名称:DocForge - AI文档模板仿写系统
开源仓库:GitHub - doc-forge(已开源,欢迎 Star)
技术栈:Python + Flask + Ollama + pdfplumber + ReportLab + PaddleOCR + Tailwind CSS
开发周期:使用 TRAE SOLO 从零搭建
协议:MIT(欢迎 Star / Fork / PR)
 摘要
摘要
日常工作中经常需要撰写各种项目工程资料、会议记录等文档,而这些文档通常都有固定的格式和流程。每次写新文档时,都要翻出以前的旧资料对照格式,逐字逐句地模仿——这个过程既耗时又容易出错。
DocForge 就是为了解决这个问题而生的。它的核心思路很简单:
上传以前的PDF参考资料 → AI自动匹配最相似的模板 → 读取模板全文 → 仿照写作风格生成新文档 → 一键输出PDF
你只需要提供一个标题和核心信息,AI会自动找到模板库中最相似的文档,读取它的完整内容,分析其写作风格、段落结构和专业术语,然后按照相同的风格生成一份全新的文档。格式和流程与模板一致,内容根据你的需求自由发挥。
 为什么做这个?
为什么做这个?
工作中最痛苦的场景之一:
“这个项目验收报告你参照上次的格式写一份。”
然后你就开始翻旧文件、对格式、抄结构、改内容……一份报告写下来大半天没了。
更痛苦的是,不同类型的文档(工程资料、会议纪要、方案报告)格式各不相同,你手头可能有很多以前的资料,但每次都要人工去找最合适的那份来参考。
DocForge 把这个过程自动化了:
- 把你以前的所有PDF资料上传到模板库(一次性操作)
- 需要写新文档时,输入标题和需求
- 系统自动匹配最相似的模板
- AI读取模板全文,仿照其风格生成新内容
- 你只需要检查修改,然后导出PDF
系统架构
整个系统采用前后端分离架构,Python Flask 后端 + 单页面前端:
技术栈一览
| 层 | 选型 | 说明 |
|---|---|---|
| 后端框架 | Python + Flask | 轻量级API服务 |
| 前端界面 | HTML + Tailwind CSS + JS | 响应式单页应用 |
| PDF解析 | pdfplumber + PyMuPDF | 提取文本、表格、结构 |
| PDF生成 | ReportLab | 中文字体支持,格式控制灵活 |
| AI模型 | Ollama(本地大模型) | 无需API Key,数据不出本地 |
| 手写体OCR | PaddleOCR | 百度开源,中文手写体识别 |
| 模板匹配 | 关键词相似度 + 多维度评分 | 类型、关键词、标题三维匹配 |
核心模块
doc_generator/
├── app.py # Flask后端(API接口层)
├── index.html # Web前端界面
├── ai_writer.py # AI内容仿写引擎(核心)
├── pdf_parser.py # PDF解析与结构提取
├── ocr_engine.py # 手写体OCR识别
├── template_manager.py # 模板存储与管理
├── template_matcher.py # 模板智能匹配引擎
├── pdf_generator.py # PDF文档生成
├── requirements.txt # Python依赖
└── start.bat # 一键启动脚本
 核心功能详解
核心功能详解
1. PDF智能解析
上传PDF后,系统自动提取:
- 文档结构:标题层级(第一章、1.1、(一)等中文编号自动识别)
- 表格数据:表头、行数据完整提取
- 文档类型:自动区分"项目工程资料"和"会议记录"
- 关键词:提取专业术语用于后续匹配
2. AI智能仿写(核心功能)
这是整个系统最关键的部分。AI仿写的流程:
用户输入需求 → 匹配相似度最高的模板 → 读取模板全文内容
→ AI分析写作风格和结构 → 仿照模板风格生成新内容 → 输出结构化数据
关键设计决策:AI读取的是模板的完整原文,而不仅仅是格式骨架。
这意味着AI能够:
- 分析模板的专业术语和用词习惯
- 理解段落的逻辑结构和论述方式
- 保持与模板一致的章节组织
- 根据新需求生成内容完整、格式规范的专业文档
AI引擎支持两种模式:
- 一键仿写:自动匹配最佳模板 + 全文生成 + 填充编辑器
- 逐章生成:选择模板后,AI逐个章节读取原文并仿写
3. 模板智能匹配
基于多维度评分的匹配算法:
| 维度 | 权重 | 说明 |
|---|---|---|
| 文档类型匹配 | 30% | 工程资料 vs 会议记录 |
| 关键词重叠度 | 40% | 需求关键词与模板关键词的交集 |
| 标题相似度 | 20% | 标题词 overlap |
| 标签匹配 | 10% | 自定义标签 |
匹配结果按分数排序,展示前5个候选模板及相似度百分比。
4. 手写体OCR识别
会议记录中经常有手写批注、签名等内容。系统集成了 PaddleOCR:
- 支持中文手写体识别
- 自动区分印刷体和手写体(基于置信度判断)
- OCR结果缓存机制,避免重复识别
- 识别结果自动合并到模板结构中
5. PDF文档生成
使用 ReportLab 生成PDF,特点:
- 完整中文字体支持(宋体、黑体、微软雅黑等)
- 多级标题样式(自动匹配模板的标题层级)
- 表格生成(自动适配列宽)
- 会议记录专用格式(信息表格 + 签名区)
- 元信息自动填充(单位、日期、编制人等)
 技术实现细节
技术实现细节
AI仿写引擎设计
AI仿写引擎(ai_writer.py)是整个系统的核心,设计要点:
1. Prompt工程
系统提示词根据文档类型动态构建:
- 项目工程资料:强调技术描述准确性、工程流程规范性
- 会议记录:强调信息完整性、决议事项明确性
用户提示词包含完整的模板原文(截断至8000字符以适应上下文窗口),要求AI输出结构化JSON。
2. 容错解析
AI输出可能不是标准JSON,系统实现了三级降级:
- 第一级:直接JSON解析
- 第二级:正则提取JSON块(处理markdown代码块包裹)
- 第三级:按标题模式分割文本(兜底方案)
3. 本地模型优先
使用Ollama运行本地大模型,优势:
- 数据不出本地,安全可控
- 无API调用成本
- 支持任意开源模型(Qwen、DeepSeek、Llama等)
PDF解析策略
中文文档的标题识别是难点,系统通过正则匹配多种中文编号模式:
heading_patterns = [
(r'^第[一二三四五六七八九十百]+[章节部分篇]', 1), # 第一章
(r'^[一二三四五六七八九十]+[、.]', 2), # 一、
(r'^\d+[、..]\s*', 2), # 1、
(r'^\d+\.\d+', 3), # 1.1
(r'^\d+\.\d+\.\d+', 4), # 1.1.1
(r'^[((][一二三四五六七八九十]+[))]', 2), # (一)
(r'^[((]\d+[))]', 3), # (1)
]
 成果展示
成果展示
开源仓库
![]() 欢迎 Star / Fork / PR
欢迎 Star / Fork / PR
系统截图
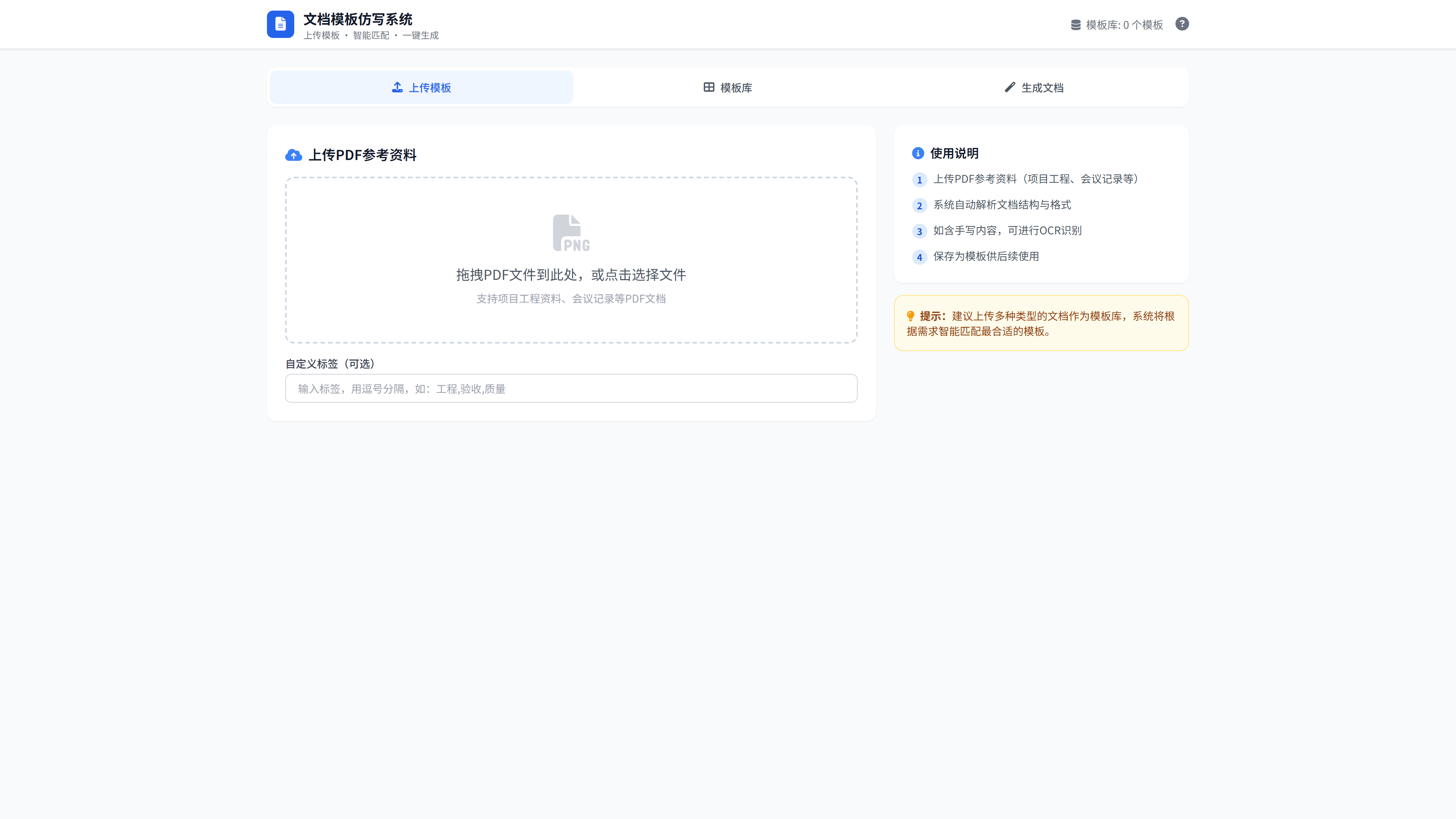
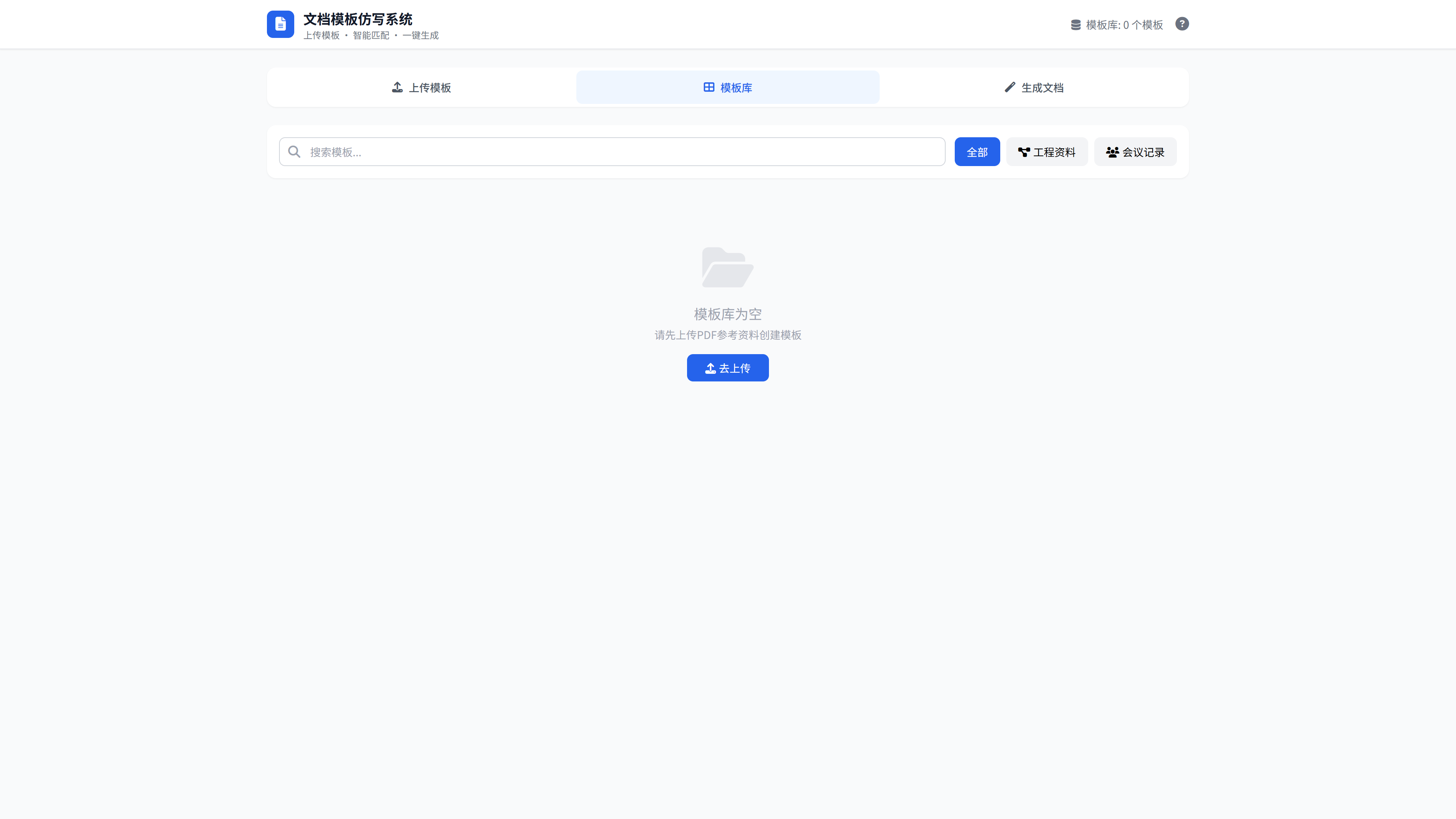

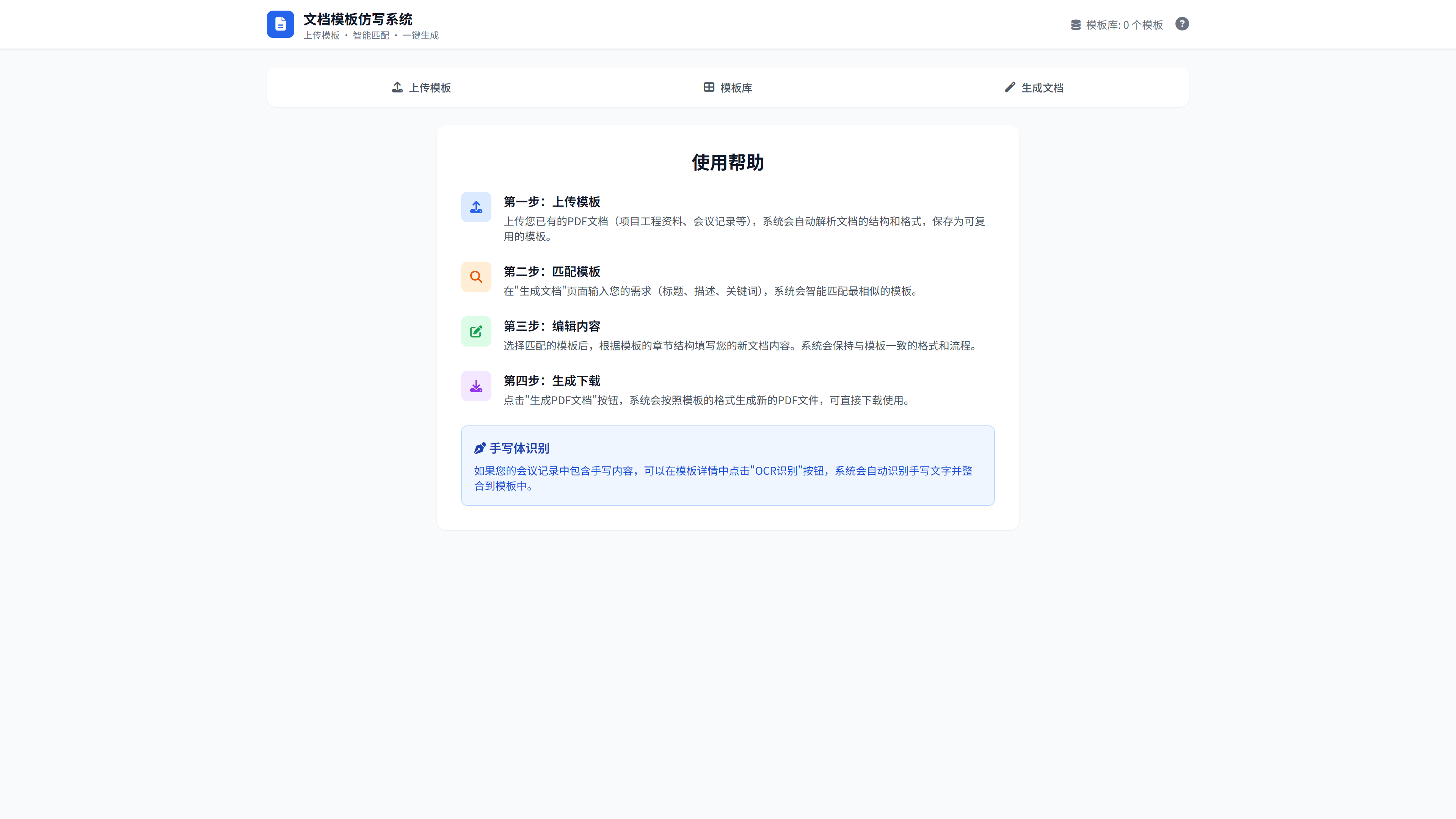
快速开始
# 1. 克隆仓库
git clone https://github.com/YOUR_USERNAME/doc-forge.git
cd doc-forge
# 2. 安装依赖
pip install -r requirements.txt
# 3. 安装Ollama并下载模型(AI仿写功能需要)
ollama pull qwen2.5:7b
# 4. 启动
python app.py
# 5. 打开 http://localhost:5000
 总结与反思
总结与反思
SOLO在开发中的帮助
这个项目从零到完成,SOLO在以下几个环节发挥了关键作用:
- 架构设计:从需求到技术选型,SOLO帮我快速确定了Python+Flask的技术栈和模块划分
- PDF处理:pdfplumber和ReportLab的API我不熟悉,SOLO直接给出了可用的代码
- AI集成:Ollama API的调用、Prompt工程、JSON容错解析,这些都需要反复调试
- 前端界面:Tailwind CSS的响应式布局,SOLO生成的代码质量很高
后续计划
- 支持更多文档格式(Word、Excel导入)
- 增加模板协作编辑功能
- 支持更多AI模型(OpenAI API、通义千问等)
- 添加文档版本对比功能
- 部署为在线服务
 致谢
致谢
- TRAE SOLO:从需求到上线,全程AI辅助开发
- Ollama:让本地运行大模型变得简单
- PaddleOCR:优秀的手写体识别引擎
- ReportLab / pdfplumber:强大的PDF处理库
如果这个项目对你有帮助,欢迎 Star ![]() ,也欢迎提 Issue 和 PR。
,也欢迎提 Issue 和 PR。
让AI帮你写文档,而不是让你帮AI写Prompt。