1.摘要
用 TRAE SOLO 搭建了一套储能行业智能简报自动生成系统,覆盖产业链价格、国内外大储、工商业储能、氢能共 5 大板块 16个子章节,自动完成数据采集分析、行业情报检索、内容撰写与排版,一键输出结构化周报。原本需要 3-4小时人工搜集整理的周报,现在约 30 分钟即可完成,且数据更全面、结构更规范。
2. 背景
我是一名能源行业的相关人员,负责公司的行业情报周报编制。每周需要:获取原材料/电芯价格数据并做趋势分析;跟踪储能招中标数据并计算统计指标;检索国内外政策、友商动态、竞品信息;最终汇总为一份包含数据表格、趋势图表、情报分析的完整周报。整个过程涉及 Excel数据处理、多渠道信息检索、结构化写作。手工操作耗时长、易遗漏,且格式不统一。
3. 实践过程
任务拆解
我将周报生成拆分为三层架构:
┌─────────────────────────────────────────┐
│ 前端 (Vue 3 + Element Plus) │ 配置面板 / 进度展示 / 报告渲染 / 导出
├─────────────────────────────────────────┤
│ 后端 (Express + PostgreSQL) │ 任务调度 / 进度轮询 / 数据持久化 / 文档转换
├─────────────────────────────────────────┤
│ AI 生成服务 (Node.js + Agent) │ 16 章节并行生成 / 数据分析 / 深度检索 / 汇总合成
└─────────────────────────────────────────┘
核心思路:每个章节独立生成,最后统一汇总。16 个章节分两类处理:
- 数据分析类(价格、招中标):Agent 调用 data-analysis 技能,读取 Excel 数据源,执行 Python 脚本做统计分析并生成趋势图
- 情报检索类(政策、友商、竞品):Agent 调用 deep-research 技能,按指定来源做网络搜索并结构化输出
使用的 SOLO 能力
- Agent 编排能力:通过 npx openclaw agent --local 调用 Agent,将每个章节的 Prompt 写入临时文件,让 Agent
自主调用技能完成子任务 - data-analysis 技能:Agent 自动编写 Python 脚本读取 Excel,执行 SQL 查询、统计计算、生成 matplotlib 趋势图
- deep-research 技能:Agent
按照指定的信息源清单(政府网站、行业媒体、公司官网)进行结构化搜索,输出带来源标注的情报摘要 - 会话管理:每次 Agent 调用分配独立 session,通过 JSONL 转录文件提取搜索结果,确保过程可追溯
关键实现
Prompt 模板设计(questions.mjs):为 16 个章节各定制一套 Prompt,包含:
- 输出格式要求(表格模板、Markdown 规范)
- 数据源路径(Excel 文件、工作表名)
- 时间范围(自动计算本周起止日期)
- 分析维度(环比变化、行业解读、重点标注)
异步任务调度(server.mjs):
POST /api/generate-report → 返回 taskId
GET /api/status/:taskId → 轮询进度(0-100%)
GET /api/result/:taskId → 获取 Markdown 结果
POST /api/cancel/:taskId → 取消生成
16 个章节按 80% 权重计算进度,汇总合成占 20%。
汇总合成:所有章节完成后,将 16 份结果用 XML 标签包裹,注入汇总 Prompt,由 Agent 统一润色、去重、生成概要和目录。
踩过的坑
- Agent 输出截断:单个章节内容过长时 Agent 会截断输出,解决方案是分段生成 + 容错读取(优先读 clean 版 .md,fallback到 debug 版)
- Excel 数据格式不一致:行业数据库和内部数据库的列名、日期格式不统一,需要在 Prompt 中明确指定工作表名和字段映射
- 搜索结果噪音:deep-research 返回的结果可能包含无关信息,通过在 Prompt 中限定信息源域名、要求标注来源 URL 来过滤
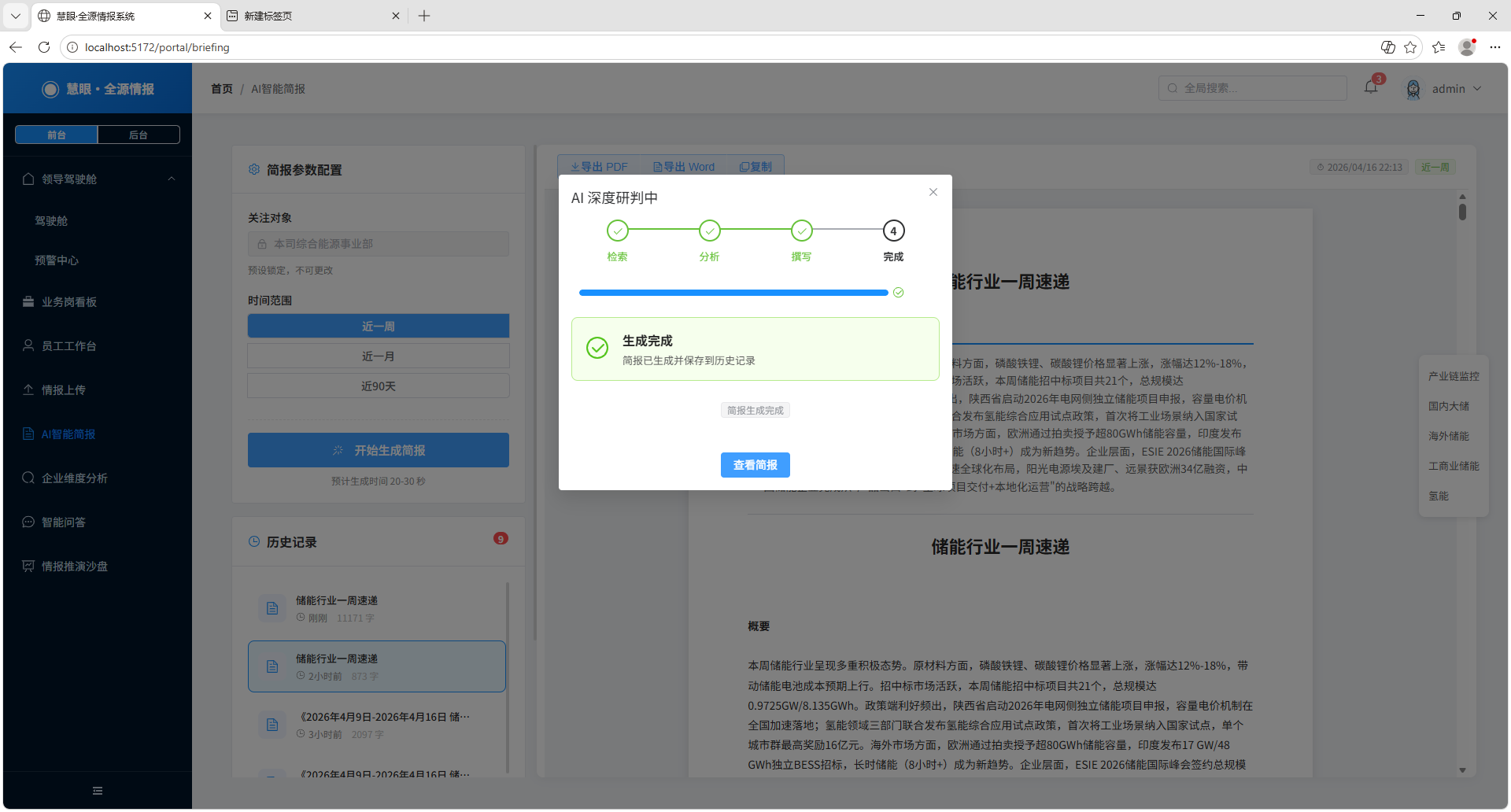
4. 成果展示
系统架构图:
用户点击"生成简报"
│
▼
前端配置面板(选择时间范围)
│
▼
后端异步任务调度
│
├── 章节1.1 原材料价格 → Agent → data-analysis → Python读取Excel → 趋势图
├── 章节1.2 电芯价格 → Agent → data-analysis → Python读取Excel → 趋势图
├── 章节2.1 招中标 → Agent → data-analysis → Python读取Excel → 统计表
├── 章节2.2 友商动态 → Agent → deep-research → 网络搜索 → 结构化摘要
├── 章节2.3 政策分析 → Agent → deep-research → 网络搜索 → 结构化摘要
├── … (共16个章节)
│
▼
汇总合成 → Agent 统一润色排版
│
▼
输出: summary-result.md → 转换为 Word/PDF
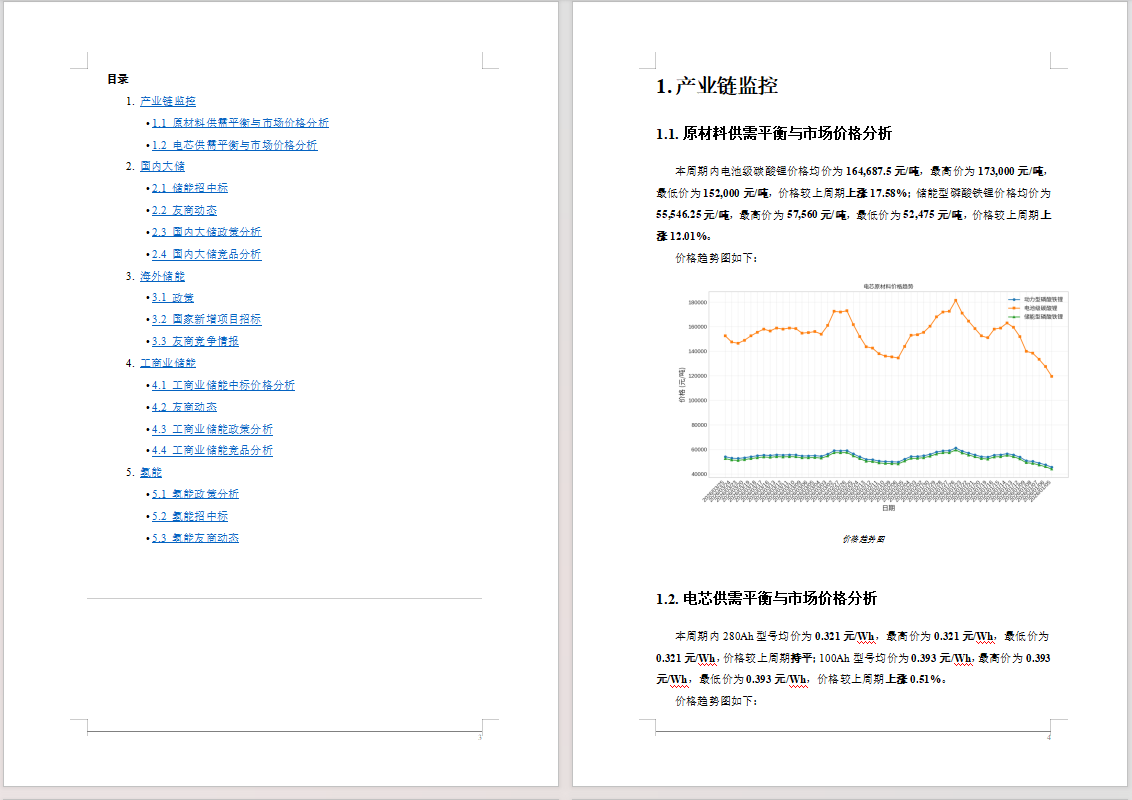
报告覆盖完整目录结构:
- 1 产业链监控(原材料价格 + 电芯价格 + 趋势图)
- 2 国内大储(招中标统计表 + 友商动态 + 政策 + 竞品)
- 3 海外储能(政策 + 项目招标 + 竞争情报)
- 4 工商业储能(中标价格 + EPC/系统价格趋势图 + 友商 + 政策 + 竞品)
- 5 氢能(政策 + 招中标 + 友商动态)
示例 - 价格分析输出:
▎ 动力型磷酸铁锂均价 53435元/吨,较上周期下跌3.72%;电池级碳酸锂均价 149600元/吨,较上周期下跌5.38%
示例 - 招中标统计输出:
┌──────────┬──────────┬───────────────┬─────────────────┐
│ 项目分类 │ 项目个数 │ 储能容量(GWh) │ 中标均价(元/Wh) │
├──────────┼──────────┼───────────────┼─────────────────┤
│ EPC │ 6 │ 2.3960 │ 1.1735 │
├──────────┼──────────┼───────────────┼─────────────────┤
│ PC │ 1 │ 0.6400 │ 0.5578 │
├──────────┼──────────┼───────────────┼─────────────────┤
│ 总计 │ 7 │ 3.0360 │ 1.0855 │
└──────────┴──────────┴───────────────┴─────────────────┘
示例 - 竞品分析输出:
▎ 本周共收集工商业储能新品及重大动态
▎ 12项,核心技术趋势呈现三大特点:500Ah+大容量电芯规模化量产提速、钠离子电池迎来产业化拐点、AIDC储能成为新爆点。
前端界面:Vue 3 + Element Plus 构建了完整的简报管理界面,包括配置面板、生成进度对话框(4步进度条)、Markdown
报告渲染(A4 纸面效果)、锚点导航、PDF/Word 导出。
5. 效果与总结
┌────────────┬──────────────────────────┬────────────────────────────────┐
│ 维度 │ 人工方式 │ AI Agent 方式 │
├────────────┼──────────────────────────┼────────────────────────────────┤
│ 耗时 │ 3-4 小时 │ 约 30 分钟 │
├────────────┼──────────────────────────┼────────────────────────────────┤
│ 数据覆盖 │ 依赖个人搜索能力,易遗漏 │ 按预设信息源系统检索,覆盖全面 │
├────────────┼──────────────────────────┼────────────────────────────────┤
│ 格式一致性 │ 每期格式有波动 │ 固定模板输出,结构统一 │
├────────────┼──────────────────────────┼────────────────────────────────┤
│ 趋势图表 │ 手工制图 │ Python 自动生成 │
├────────────┼──────────────────────────┼────────────────────────────────┤
│ 可追溯性 │ 来源难记录 │ 每条信息带来源 URL │
└────────────┴──────────────────────────┴────────────────────────────────┘
TRAE SOLO 在这个项目里的作用
TRAE SOLO 在整个项目里承担了三个角色。
- 代码搭建助手
从最初的单脚本生成器,到后来的三层架构全栈系统,SOLO 帮我快速搭建了:
- AI 生成引擎:Node.js HTTP 服务器(纯原生 http 模块,无框架),手搓路由、异步任务队列、进度追踪、取消机制
- 后端业务层:Express + PostgreSQL,跨服务异步轮询、数据库事务、Markdown→Word→PDF 文档转换管线
- 前端应用:Vue 3 + Element Plus,配置面板、实时进度对话框、A4 纸面 Markdown 渲染器、锚点导航、多格式导出
每一层的基础结构 SOLO 都能根据我的需求描述直接生成,我只需关注业务逻辑。
- 复杂逻辑搭档
这个项目里有大量不是复制粘贴能完成的逻辑,SOLO 都能根据需求生成可运行代码并持续修正:
- 16 章节 Agent 编排:每个章节独立生成 Prompt、调用 OpenClaw Agent、提取搜索结果、容错读取(clean 版 fallback 到 debug版),整个流水线的进度计算(章节 80% + 汇总 20%)和取消传播
- 跨服务异步协调:前端 3 秒轮询后端 → 后端 5 秒轮询生成服务 → 生成服务跑 16 个 Agent
子进程,三层各有独立任务追踪,后端还要防竞态(轮询到 COMPLETED 后先切 RUNNING
"正在保存结果…"再写数据库,防止前端看到 COMPLETED 但数据还没落库) - 领域级 Prompt 工程:questions.mjs 近 1900 行,16 套模板里嵌入了 SQL 查询、公司官网、行业分类体系、输出格式强制约束——这些不是通用代码,是储能行业知识的代码化
- 自定义 Markdown 渲染器:不用第三方库,手写正则解析器 + 领域锚点映射(按章节标题关键词匹配 HTMLid),支持中英混排字数统计
- Agent 输出清洗:从 JSONL 会话文件中解析三种不同格式的内容(string / text blocks / tool results),过滤 ANSI转义码和插件消息,提取结构化搜索结果
- 跨语言文档管线:Node.js 拼接命令行参数 → Python md_to_docx 转换 → Python docx2pdf 按需生成,每层都要处理跨语言 IPC
- 产品迭代伙伴
这个项目不是一次生成出来的,而是一轮一轮迭代出来的:
v1.0:单脚本 MVP
- 一个 generate-weekly-report.mjs,硬编码 16 章节,命令行运行,输出一堆 Markdown 文件
- 能跑但没法用:没有进度提示、没有结果展示、出错只能看日志
v2.0:HTTP 服务 + 异步任务
- 加了 server.mjs,手搓路由和内存任务队列
- 前端可以调 API 触发生成、轮询进度、拿结果
- 16 章节串行执行,跑完要 30-60 分钟,中间挂了就全白费
v2.1:容错与可观测性
- 每个章节双文件输出(clean + debug)
- Agent 失败自动重试(3 次指数退避,取消任务不重试)
- 搜索结果归档为 JSON,可追溯每条信息的来源 URL
v3.0:全栈 Web 应用
- 接入 huiyan-system,Vue 3 前端 + Express 后端 + PostgreSQL
- 简报配置面板、生成进度弹窗(4 步进度条)、A4 纸面报告渲染
- 历史记录管理(IndexedDB 客户端 + PostgreSQL 服务端双存储)
- PDF/Word 一键导出
v3.5:稳定性与体验打磨
- 三层异步轮询的竞态防护(后端先切状态再写库)
- 前端优雅降级(后端挂了 fallback 到 mock 数据)
- 文档转换按需生成(PDF 只在用户点击时才转)
- 取消任务级联终止(前端取消 → 后端取消 → Agent 进程 kill)
SOLO 最大的价值是:当项目已经变复杂后——1900 行 Prompt 模板、16 个 Agent子进程编排、三层异步轮询、跨语言文档管线——它仍然能理解上下文,继续帮我加功能、改bug、调逻辑,而不是只能处理从零开始的小代码片段。
可复用方法:
- 章节拆分 + 独立生成 + 汇总合成的三层架构,适用于任何多模块长文档的自动生成场景
- Prompt 模板化:将行业知识(信息源、分析维度、输出格式)固化在 Prompt 中,而非硬编码在代码里,便于迭代优化
- 异步任务 + 进度轮询:长时间 AI 生成任务的标准处理模式,前端体验友好