1. 摘要
我用 TRAE SOLO 从零搭建了 Collectly——一个 AI 驱动的个人知识管理工具,整合抖音、小红书、公众号、B站、知乎、CSDN 六大平台收藏内容,通过大模型实现智能摘要、标签分类、知识点提炼和语义检索。原本需要数周的全栈开发工作,在 SOLO 的加持下大幅提效,最终实现了一个可直接落地使用的完整 Web 应用。
2. 背景
我是一名 AI 领域的开发者,日常关注大模型、Agent、RAG、多模态等方向。每天在这六大平台上浏览大量内容,收藏了很多有价值的文章和视频,但"收藏即沉没"——想回头看的时候根本找不到。
之前想过自己做一个知识管理工具,但因为涉及后端(Python FastAPI)、前端(React + TypeScript)、多个外部 API 集成(TikHub、DashScope)、数据库设计等,全栈工作量太大,一直没启动。这次看到 SOLO 挑战赛,决定用 SOLO 来突破这个瓶颈。
3. 实践过程
3.1 任务拆解
我把整个项目拆成几个关键模块,逐个用 SOLO 推进:
- 项目架构设计 —— 确定技术栈:Python FastAPI 后端 + React TypeScript 前端 + Chroma + SQLite 数据库
- 平台内容解析 —— 集成 TikHub API,实现对六大平台链接的内容抓取
- AI 内容处理 —— 接入阿里云 DashScope,实现摘要生成、标签分类、知识点提炼
- 检索系统 —— 关键词检索 + 向量语义检索双模式
- 前端界面 —— React 响应式 H5,PC 和手机浏览器通用
- 部署方案 —— 支持本地部署+内网穿透 / 云服务器公网部署
3.2 SOLO 能力使用
- 代码生成:核心业务逻辑的 Python 和 TypeScript 代码基本都由 SOLO 生成,包括 FastAPI 路由、前端组件、数据库 schema 等
- Bug 修复:遇到前端解析状态同步问题、API 响应格式不匹配等问题时,直接用 SOLO 定位并修复
- 重构优化:多次用 SOLO 对代码进行重构,保持代码整洁
3.3 踩过的坑
- 平台接口适配:不同平台的返回格式差异很大,需要针对性处理,SOLO 在这个环节帮我快速生成了各平台的解析器
- 前端状态管理:链接解析完成后输入框仍显示"正在解析",后来通过 SOLO 引入
hasParsed状态标记解决 - 向量检索集成:ChromaDB 的本地持久化配置花了一些时间调试
4. 成果展示
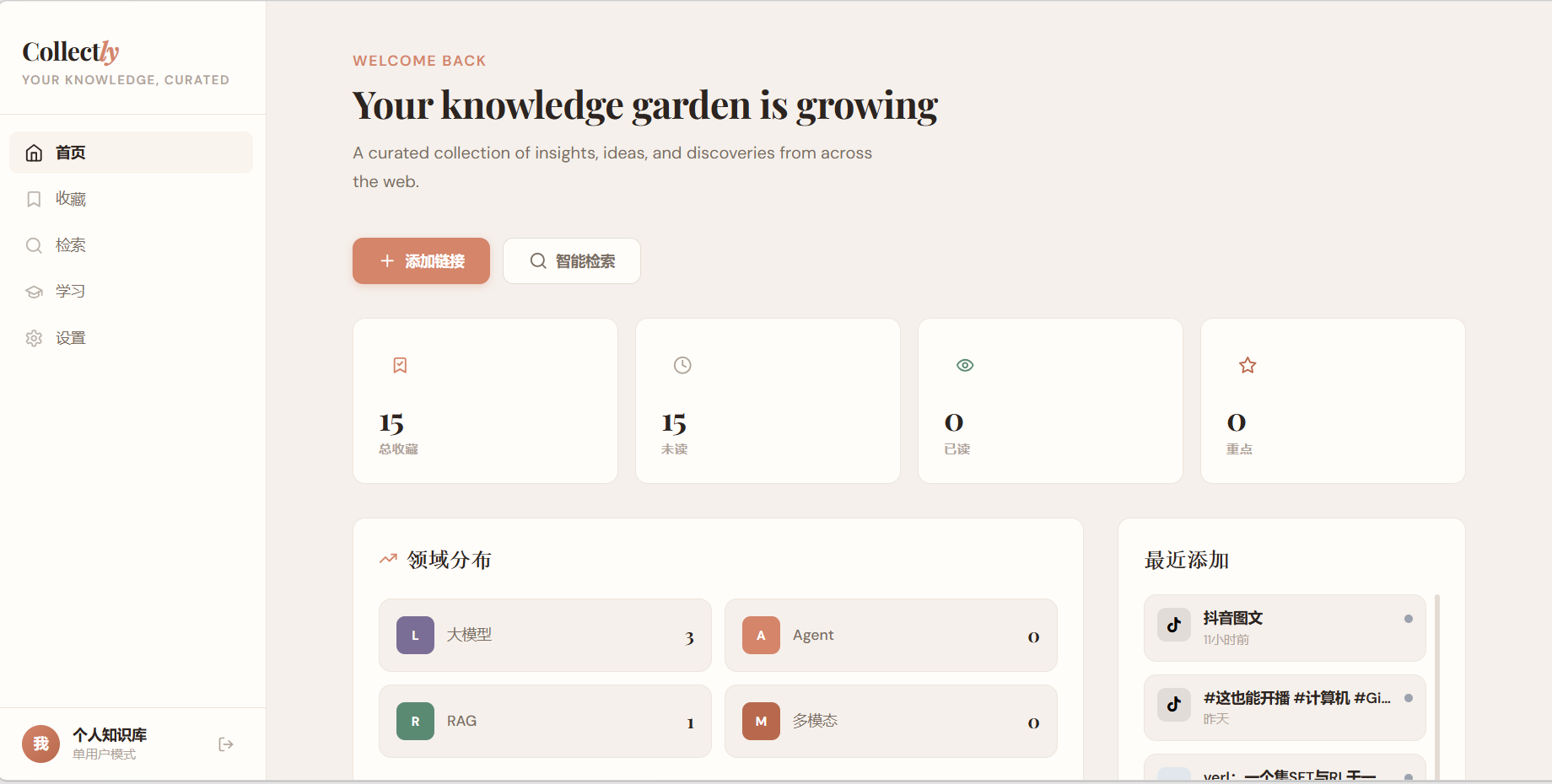
最终产出了一个功能完整的 Web 应用:
核心功能:
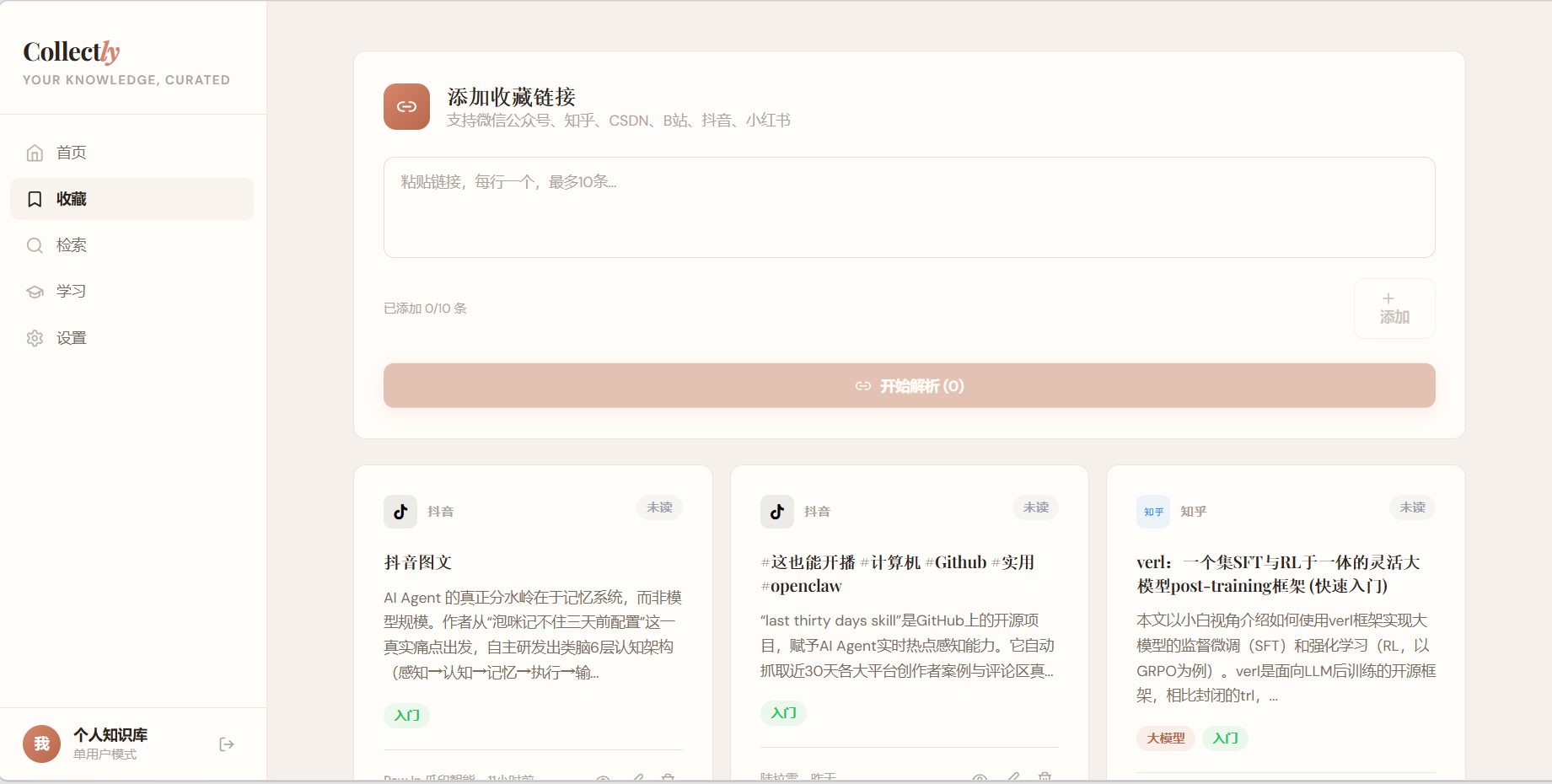
- 支持抖音、小红书、公众号、B站、知乎、CSDN 六大平台链接解析
- AI 自动生成摘要、标签、知识点
- 支持 抖音视频语音转文字(ASR)
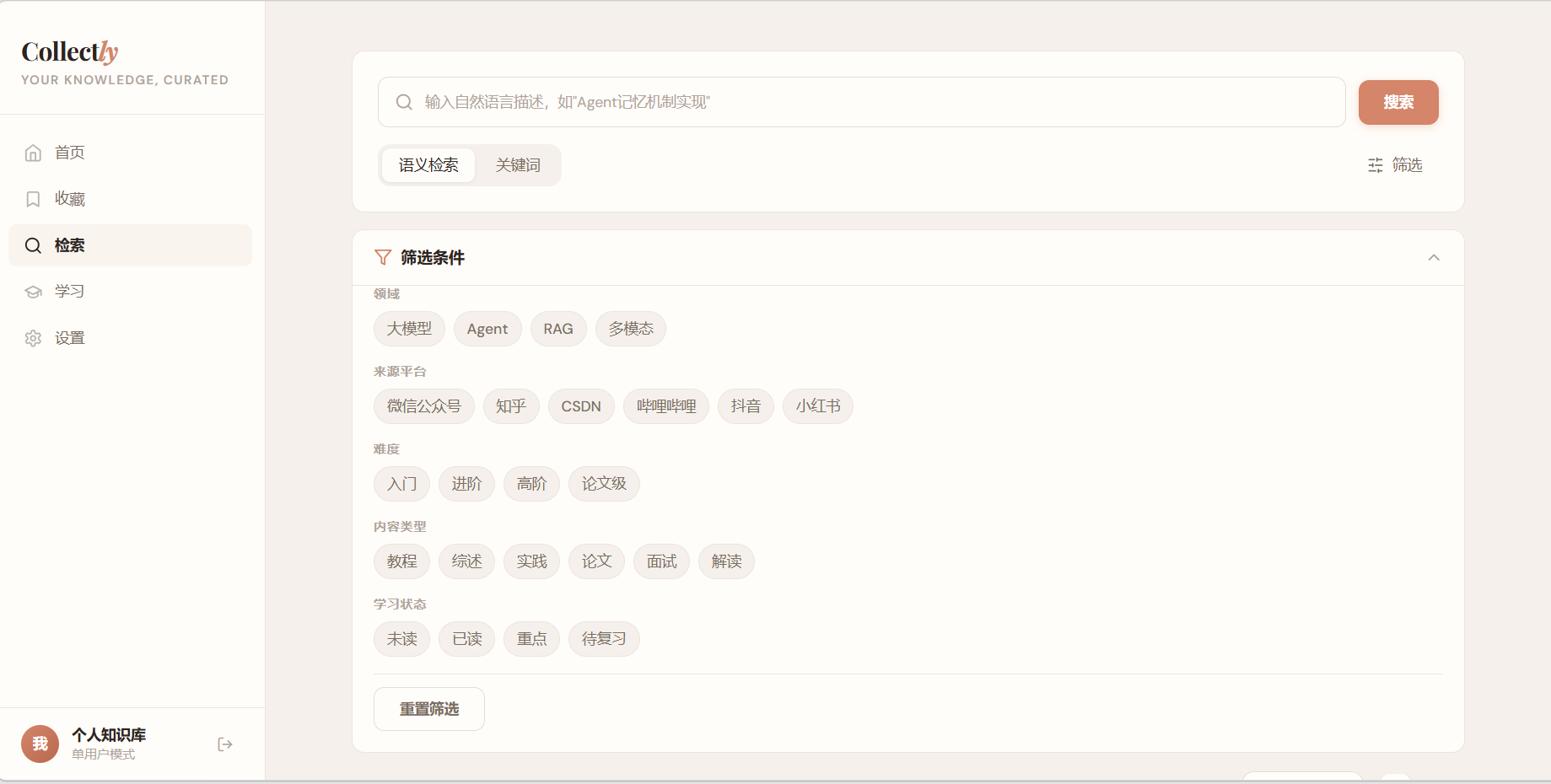
- 关键词 + 语义向量双模式检索
- 多维度筛选(平台、标签、学习状态、时间范围)
- 学习状态管理(待学习/学习中/已掌握)
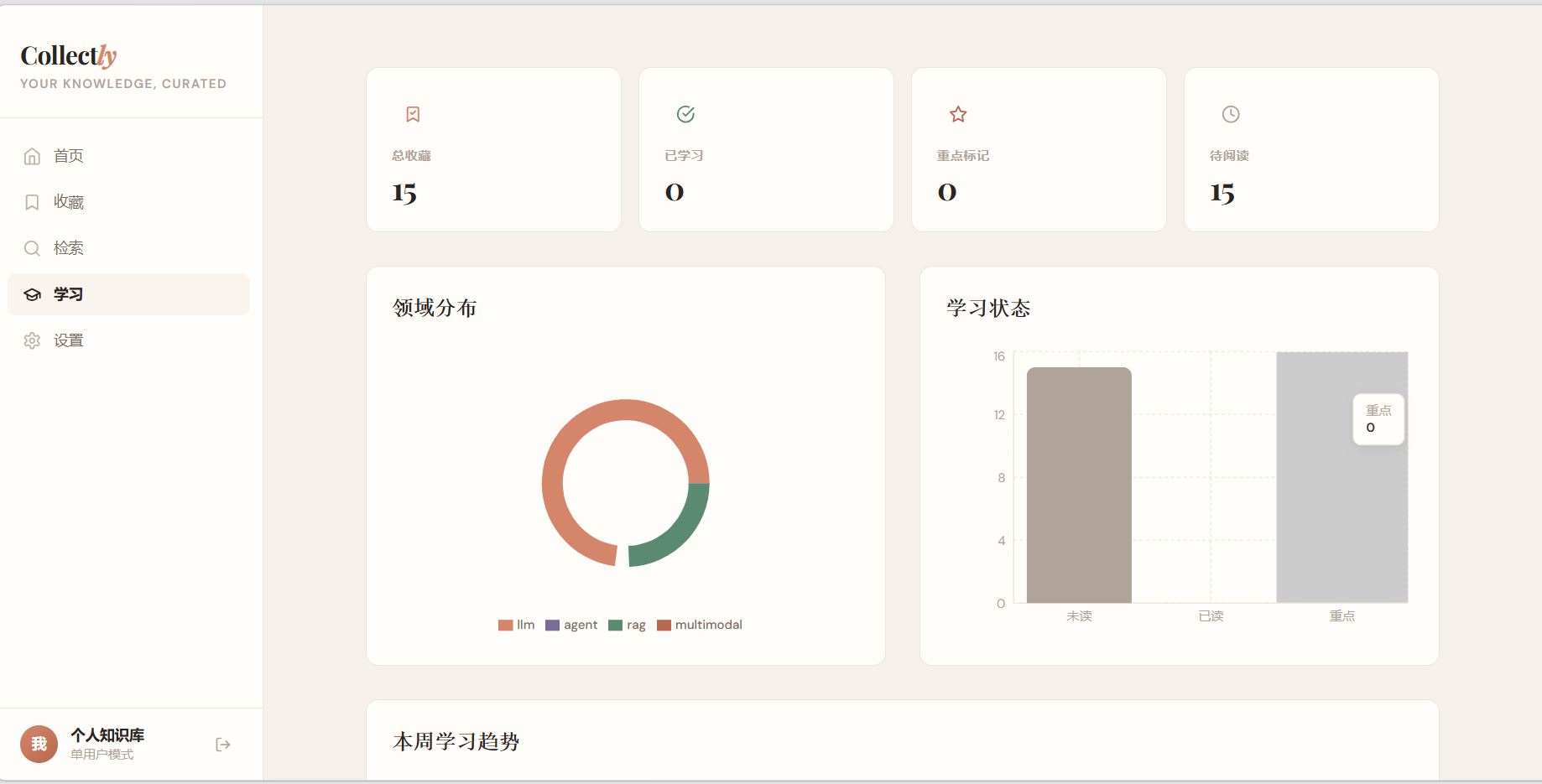
- 学习统计仪表盘
- 响应式 H5,PC 和手机浏览器通用

代码仓库:
5. 效果与总结
提效成果:
- 原本预估需要 3-4 周的全栈开发,在 SOLO 的协助下核心功能约 1 周完成
- 代码生成效率极高,特别是重复性高的解析器代码、前端组件模板等
- Bug 修复速度大幅提升,遇到问题直接描述给 SOLO,几轮对话就能解决
SOLO 在流程中的角色:
- 架构师:帮我梳理技术方案和模块划分
- 主力编码:70%+ 的代码由 SOLO 生成
- 调试助手:快速定位和修复 bug
- 文档生成:API 文档、配置文件说明等
可复用的方法:
- 先让 SOLO 出方案再写代码 —— 先讨论清楚架构和技术选型,再动手实现,减少返工
- 模块化推进 —— 每个功能模块独立推进,避免上下文过长
- 善用截图沟通 —— 遇到 UI 问题直接截图给 SOLO,比文字描述高效得多
总结: SOLO 不是替代开发者,而是把开发者从繁琐的编码中解放出来,让你把更多精力放在产品设计和核心逻辑上。这次实践中,我最大的感受是"有想法就敢动手"——以前会因为全栈技术栈太多而犹豫,现在有了 SOLO,技术门槛不再是阻碍。