很多人看到 DeepSeek-V4 论文的第一反应是:“哦,又是一个参数更大的模型,又支持了更长的上下文。”
如果你也是这么想的,那可能完全偏离了这篇论文的真正价值。
在当下的 AI 圈,喊出一句“我们支持 1M(一百万)Token”并不难。但作为一个真正在生产环境踩过坑的架构师,你应该很清楚:长上下文从来都不是一个“能不能看见”的问题,而是一个“算不算得起、存不存得下”的残酷工程问题。
当上下文真的拉长到 100 万时,注意力计算的开销会呈指数级爆炸,KV Cache(键值缓存)会像无底洞一样吞噬你昂贵的 GPU 显存。
今天,我们就抛开枯燥的数学公式,用架构设计的视角来扒一扒:DeepSeek-V4 到底凭什么能把 1M Context 做到既强、又稳,还特么用得起?
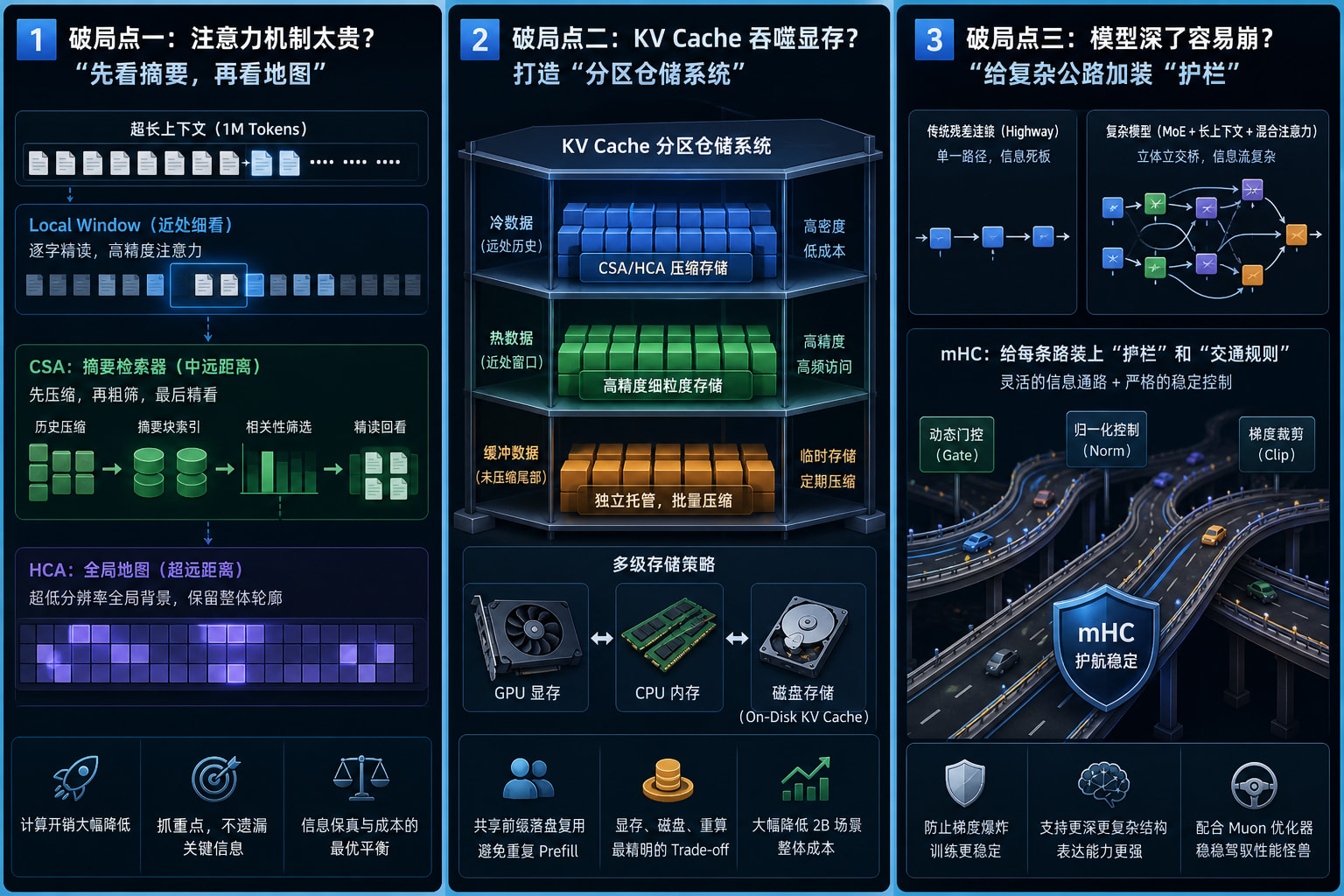
 破局点一:注意力机制太贵?那就“先看摘要,再看地图”
破局点一:注意力机制太贵?那就“先看摘要,再看地图”
在传统的注意力机制(Attention)里,模型每生成一个词,都要回头把历史记录里的所有词都“深情对视”一遍。
几千个 Token 还可以勉强接受,但如果是 100 万个 Token 呢?这就像你为了写年终总结,每次动笔前都要把公司过去十年的所有邮件逐字通读一遍——成本不仅夸张,而且毫无必要。
DeepSeek-V4 给出的架构解法是混合注意力机制(Hybrid Attention),核心引入了两个杀手锏:CSA(Compressed Sequence Attention)和 HCA(Half-Compressed Attention)。
我们该怎么理解这两个东西?
1. CSA:超长历史的“摘要检索器”
你可以把 CSA 粗暴地理解为:先压缩,再粗筛,最后精看。
它先把几十万字的历史记录压缩成一个个“摘要块”。当模型需要回顾历史时,先去翻这些摘要,判断哪些块和当前任务最相关,然后再去重点读取那极少部分的细节。
CSA 让模型在超长历史面前,学会了“抓重点”,而不是无差别全看。
2. HCA:超低分辨率的“全局背景图”
如果说 CSA 是重点检索器,那 HCA 就是一张超低分辨率、但极其便宜的全局地图。
对于那些非常久远、但可能决定了整体语境的历史,HCA 采用更激进的压缩方式,只保留一个“整体轮廓”。
我知道这时候肯定有同学要说了:“这不就是加个本地缓存和降采样吗?”
没错,但 DeepSeek-V4 的高明之处在于它顺应了人类处理长材料的直觉:
-
近处的内容:用本地窗口(Local Window)逐字细看。
-
中远距离内容:用 CSA 看摘要,挑重点回看。
-
超远距离背景:用 HCA 保留一个便宜的整体印象。
架构设计的本质,就是不断在信息保真度与计算成本之间寻找最优雅的平衡点。
 破局点二:KV Cache 吞噬显存?打造“分区仓储系统”
破局点二:KV Cache 吞噬显存?打造“分区仓储系统”
到了 1M Context 的极限场景,最可怕的资源账本其实是 KV Cache。
大白话来说,KV Cache 就是模型做题时长期保留的“草稿本”。上下文越长,草稿本越厚,不仅占空间,每次翻阅还极其消耗内存带宽(Memory Bandwidth)。
很多开源模型对 KV Cache 的处理非常粗暴:按时间顺序,一锅端地往显存里塞。
但 DeepSeek-V4 把 KV Cache 变成了一个精密的“分区仓储系统”。因为有了前面的混合注意力机制,V4 的缓存也不再是单一格式:
·远处历史(冷数据):存的是被 CSA/HCA 压缩后的高密度状态。
·近处窗口(热数据):存的是高精度的细粒度状态。
·未压缩尾部(缓冲数据):单独托管,等攒够了再打包压缩。
甚至,论文里还专门提到了 磁盘缓存(On-Disk KV Cache Storage)。
很多技术洁癖可能会皱眉头:“落盘?那得多慢啊!”
但在真实的 2B 办公场景中,如果有 100 个用户都在对着同一份 50 万字的财报提问,这份财报的超长前缀如果每次都重新 Prefill(预填充),那点算力成本会让你连底裤都亏掉。
这时候,把共享的超长前缀直接落盘,后续复用,反而省掉了更昂贵的重复计算开销。
这就叫工程智慧:不是一味追求“所有东西都在显存里极限快”,而是在显存、磁盘、重算之间做最精明的 Trade-off。
 破局点三:模型深了容易崩?给复杂公路加装“护栏”
破局点三:模型深了容易崩?给复杂公路加装“护栏”
解决了算力和显存,我们还要面对一个幽灵:训练稳定性。
DeepSeek-V4 包含了 MoE(混合专家)、超长上下文、混合注意力等一堆极其复杂的结构。这就导致模型内部的信息流转不再是一条直直的高速公路,而是一个立体的巨型立交桥。
传统的残差连接(Residual Connection)虽然稳,但在这种复杂结构下显得过于死板。如果你把信息通路全放开,让梯度随便流,训练没几天模型就会梯度爆炸,直接“散架”。
V4 给出的方案叫 mHC(Modified Highway Connection)。
用人话说:mHC 就是在允许模型内部拥有更多、更灵活的信息岔路口的同时,给每一条路都装上了极其严格的“交通规则”和“护栏”。
它既保证了深层复杂网络拥有强大的表达能力,又死死摁住了梯度的稳定性。配合底层专门定制的 Muon 优化器(你可以把它看作是复杂大模型的专属方向盘),V4 成功把这台结构极其复杂的“性能怪兽”稳稳地训了出来。
 终极演进:从“会答题”到“会干活”的 Agent 系统
终极演进:从“会答题”到“会干活”的 Agent 系统
你可能会问,费了这么大劲把 1M Context 做好,到底有什么用?
如果只是为了让模型在 Benchmark(跑分榜单)上多拿几分,那完全是高射炮打蚊子。DeepSeek-V4 的野心,是把模型从“一问一答的聊天机器人”,变成“持续工作的工程系统”。
我们拆解两个极度吃上下文的真实场景:
场景 1:Agentic Search(自主搜索)
普通的 RAG(检索增强)是“你喂给它搜索结果,它总结”。
但 V4 瞄准的是自主搜索:模型自己判断怎么搜,搜一次不够再搜,对比多个网页,甚至中途纠错。这个持续数十轮的操作轨迹,天然需要巨大且稳定的长上下文支撑。
场景 2:代码 Agent(软件工程流)
普通模型写代码是“做一道 LeetCode 题”。
但 V4 要做的是:读懂你几十个文件的老项目,分析依赖,修改代码,看测试报错,然后再自我修正。这已经不是文本生成了,而是带环境反馈的持续软件工程流。
在后训练(Post-Training)阶段,V4 使用了 OPD(Online Preference Dropout) 算法。它不再是简单地让模型“背老师的标准答案”,而是让模型在自己真实走出来的错误轨迹中学会“纠偏”。
总结
DeepSeek-V4 这篇论文,绝不是简单地宣告“我们的窗口更长了”。
它其实是一份极具野心的系统级架构说明书。从底层的 mHC 稳住复杂结构,到中层的 CSA/HCA 砍掉算力成本,再到上层精密的 KV Cache 资源账本,最后收口于 Agentic Search 和代码 Agent 的工作流。
它告诉我们一个血淋淋的现实:没有底层算力和缓存的系统级重构,一切长文本和 Agent 都是纸上谈兵。
正如那句架构名言所说:
“所有脱离了成本和稳定性的架构设计,都是耍流氓。”
DeepSeek-V4,毫无疑问是把这句话践行到了极致。