【Code With SOLO】用 TRAE SOLO 从零搭建一个 DDD 架构的个人电子书管理全栈 Web 应用
1. 摘要
使用 TRAE SOLO 从零搭建了一个基于 DDD(领域驱动设计)+ 事件驱动架构的个人电子书管理全栈 Web 应用「个人书仓」,实现了涵盖图书管理、在线阅读、元数据刮削、设备同步、存储管理、权限控制等 18 个业务域的完整系统。SOLO 在整个开发过程中承担了架构设计、代码生成、重构决策、代码审计与问题修复等核心角色,将原本需要数月完成的全栈项目压缩到高效交付。
2. 背景
我是一名阅读爱好者,个人拥有大量电子书资源,对电子书的整理、刮削与阅读有需求。市面上的电子书管理工具(如 Calibre、Talebook)虽然功能强大,但太丑 ![]() 且阅读体验差,尤其移动端适配更差(作为颜值党,好看是第一优先)。于是萌发了制作一个面向个人场景的 Web 应用,通过nas进行部署,能集中管理电子书、支持在线阅读、自动抓取书籍元数据、跨设备同步阅读进度,同时具备完善的权限与存储管理能力,最最关键的是要好看。
且阅读体验差,尤其移动端适配更差(作为颜值党,好看是第一优先)。于是萌发了制作一个面向个人场景的 Web 应用,通过nas进行部署,能集中管理电子书、支持在线阅读、自动抓取书籍元数据、跨设备同步阅读进度,同时具备完善的权限与存储管理能力,最最关键的是要好看。
传统开发方式下,这样一个包含 18 个业务域的全栈系统,从架构设计到功能实现,对编程相关从业人员而言至少需要 3-4 个月,而对于毫无编程能力的我却是无期。而借助 TRAE SOLO 的 AI 编程能力,我能够快速完成从架构规划到代码落地的全流程,大幅缩短开发周期。
3. 实践过程
3.1 任务拆解
整个项目按领域驱动设计思想,将系统拆解为三大域层、17 个业务域:
| 域层 | 包含域 | 核心职责 |
|---|---|---|
| 核心业务域 | 图书域、搜索域、书架域、阅读域 | 图书 CRUD、全文检索、书架组织、在线阅读 |
| 支撑业务域 | 元数据域、插件域、协议域、同步域 | 多源刮削、插件扩展、WebDAV/OPDS、设备同步 |
| 基础设施域 | 身份域、权限域、存储域、调度域、通知域、日志域、备份域、统计域、配置域、架构守护域 | 认证鉴权、RBAC、存储管理、任务调度、消息通知、审计日志、备份恢复、数据分析、系统配置 |
3.2 SOLO 能力使用
在整个开发过程中,我深度使用了 TRAE SOLO 的以下能力:
1. 架构设计与规划
通过 SOLO 进行系统架构的顶层设计,包括:
- 基于 DDD 原则划分子系统边界和域间交互关系
- 设计事件总线(EventBus)解耦域间依赖,实现发布/订阅模式
- 制定三层架构规范(API → Service → Model),并生成架构守护脚本
关键 Prompt 示例:
请基于 DDD 原则为个人电子书管理系统设计子系统划分方案,明确各域的边界、核心功能模块、主要职责及相互间的交互关系,采用事件驱动架构解耦各域之间的依赖关系
2. 全栈代码生成
SOLO 帮助生成了前后端大量核心代码:
- 后端(FastAPI + SQLAlchemy):API 路由、Service 业务逻辑、数据模型、Pydantic Schema、异步任务、事件处理器等
- 前端(Vue 3 + TypeScript + NaiveUI):页面组件、Composable 逻辑、API 调用层、路由配置、类型定义等
- 数据库迁移:Alembic 迁移脚本、数据表结构设计
关键 Prompt 示例:
请为图书管理子系统实现后端三层架构代码,包括 API 层路由定义、Service 层业务逻辑、Model 层数据模型,以及对应的 Pydantic Schema
3. 架构重构与解耦
在开发过程中,发现子系统间存在双向依赖问题,通过 SOLO 进行了系统性的架构重构:
- 引入事件总线(MemoryEventBus / RedisStreamEventBus)解耦域间通信
- 将刮削功能从图书管理中独立为元数据域
- 明确阅读进度存储的职责边界(阅读域触发事件,书架域订阅存储)
- 建立架构守护脚本,自动检测 API 层违规直接数据库操作
关键 Prompt 示例:
图书管理子系统与搜索服务子系统存在双向依赖,违反依赖倒置原则。请设计事件总线方案解耦,并实现 MemoryEventBus 适配 SQLite 单实例部署
4. 代码审计与问题修复
SOLO 在代码审计方面发挥了巨大作用,完成了多轮系统性审计:
- 对每个子系统进行代码审计,生成审计报告并标注 P0/P1/P2/P3 级别问题
- 自动修复前后端类型定义不一致、API 响应结构不匹配等问题
- 检测并修复 SQL 注入风险、输入校验缺失等安全问题
- 确保前端 camelCase 与后端 snake_case 的字段映射一致性
关键 Prompt 示例:
代码审计任务:阅读服务子系统
根据《阅读服务子系统.md》文档的定位与设计要求,对阅读服务子系统的后端和前端源代码执行全面审计。审计需严格对照文档中的功能模块、数据流程、接口定义及性能指标。
审计范围
- 后端代码:backend/app/api/reader.py, backend/app/api/reading.py, >backend/app/services/reader_service.py, backend/app/services/reading_event_publisher.py, backend/app/models/reading.py 及相关路由/服务文件。
- 前端代码:frontend/src/views/reader/ 目录下所有文件,frontend/src/service/api/reader.ts 及相关组件。
- 参考文档:《阅读服务子系统.md》(v3.1.0)。
审计步骤与标准
1. 架构与依赖关系审计
- 验证代码中的模块划分、类依赖关系是否与文档1.3节架构图及1.4节依赖关系表一致。
- 检查是否通过事件总线发布/订阅指定事件,通信方式是否正确(同步/事件)。
- 确认事件发布器实现是否与文档5.1节定义的事件类型、数据结构一致。
2. 核心功能模块实现完整性
- 逐项对照文档第2章功能规格表,验证每个功能点是否有对应实现代码。
- 包括但不限于:EPUB/PDF阅读渲染、书签CRUD、阅读设置、进度更新触发、字体管理、目录提取、阅读会话。
- 检查进度更新流程是否符合文档2.5.3节流程图。
3. 代码质量评估
- 命名规范:后端Python遵循PEP 8(snake_case),前端TypeScript/Vue遵循社区惯例(camelCase),接口响应字段符合camelCase(文档4.4节)。
- 代码格式:缩进、行长、空行等一致性。
- 模块化程度:关注功能分离,路由、服务、模型是否分层清晰。
- 注释完整性:类、方法、复杂逻辑是否有必要注释,与文档描述是否匹配。
- 错误处理:检查异常捕获是否全面,是否使用文档7.1节定义的READ-XXXX错误码,错误响应格式是否统一。
4. 数据模型一致性审计
- 对照文档第3章各表结构,检查SQLAlchemy模型或数据库迁移文件中字段名、类型、约束、默认值是否一致。
- 验证外键关系、索引是否符合设计。
5. 接口规格一致性审计
- 对比文档4.1节接口总览表,检查后端实际注册的路由是否完整,方法、路径、认证要求是否匹配。
- 验证请求参数模型(Pydantic schemas)是否符合文档中的字段定义(如progress更新请求的camelCase字段)。
- 验证响应结构是否包含code、message、success、data等字段,成功/错误状态码是否正确。
6. 前后端联动审计与对比报告
- 后端设计接口清单:整理文档10.6节及4.1节中的所有接口,形成基准表。
- 后端已实现接口:通过代码扫描或动态测试确定实际暴露的端点,评估完成度。
- 前端功能对照:分析前端页面组件和API调用,确认已实现的用户界面和功能。
- 未实现/差异:标记前端或后端缺失的功能,分析原因(如未开发、架构调整)。
- 数据交互一致性:抓取或模拟前后端通信,比较请求/响应体字段名、类型、格式。特别检查camelCase转换、分页格式、错误码返回。
- 性能指标达标:根据文档2.1.3节、2.2.2节等性能要求,测试EPUB/PDF加载速度、内存占用、进度更新防抖等是否达标。
输出要求
在项目开发文件夹下生成
阅读服务子系统审计报告.md,报告结构应包括:
- 审计概述(范围、方法、文档版本)
- 吻合度总评分及关键发现摘要
- 逐项审计详情:
- 架构与依赖关系
- 功能模块实现
- 代码质量(附评分与实例)
- 数据模型
- 接口一致性
- 前后端对比报告(含表格):
- 后端接口清单与实现对比表
- 前端功能模块与实现状态
- 前后端不一致案例列表(字段名、类型、格式差异及代码位置)
- 接口调用错误/异常处理问题
- 性能测试结果
- 改进建议与优先级(按高/中/低)
- 附录(测试用例、截图、代码引用索引)
所有问题需关联具体代码文件和行号(如可能),并提供截图或测试日志佐证。
5. 文档生成与维护
SOLO 帮助生成了完整的项目文档体系:
- 17 个子系统的详细功能文档
- 系统接口设计规范
- 三层架构规范文档
- API 契约自动化方案
- 重构日志与回滚策略
3.3 关键操作过程
阶段一:项目初始化与基础架构搭建
- 基于 SoybeanJS 管理后台模板初始化前端项目(Vue 3 + Vite + TypeScript + NaiveUI)
- 搭建 FastAPI 后端项目骨架,配置 SQLAlchemy + Alembic 数据库迁移
- 设计并实现 JWT 认证体系、RBAC 权限模型
阶段二:核心业务域开发
- 实现图书管理全流程:上传、元数据编辑、分类标签、批量操作、重复检测
- 集成 EPUB/PDF 在线阅读器,支持书签、笔记、高亮、目录导航
- 实现 Whoosh + jieba 全文搜索引擎,支持拼音搜索和高级筛选
- 开发豆瓣元数据刮削功能,自动获取书籍封面、简介、评分
阶段三:架构重构(DDD + 事件驱动)
- 引入事件总线系统,解耦图书域与搜索域的双向依赖
- 将刮削功能独立为元数据域,明确域边界
- 重构阅读进度存储机制,阅读域发布事件、书架域订阅存储
- 建立架构守护脚本(check_api_db_operations.py),CI 自动检测违规
阶段四:支撑与基础设施域开发
- 实现 WebDAV/OPDS 协议服务,支持第三方阅读器接入
- 开发设备同步系统,支持阅读进度和笔记的跨设备同步与冲突解决
- 实现存储管理子系统:多位置存储、去重清理、完整性校验、配额管理
- 开发任务调度系统:Cron 表达式编辑、甘特图展示、告警配置
- 实现备份恢复、通知中心、日志审计、统计分析等基础设施域
阶段五:质量保障与优化
- 多轮代码审计与问题修复(存储、备份、协议、同步、调度等子系统)
- 前后端 API 类型对齐与规范化修复
- 国际化(i18n)完善
- Pre-commit 钩子配置,确保代码质量
3.4 踩过的坑
坑 1:不要自己做前端设计,去github上找开源前端模板
本人毫无设计能力,因此将前端设计完全交给大模型生成,制作出来后的效果一言难尽 ![]() 。
。
解决方案:后面github上寻找并选择了一款“清新优雅的中后台模版”SoybeanAdmin,整个项目前端都基于该模板进行开发。在SoybeanAdmin模板官方文档中提取模板设计规范,交给solo制作前端设计规范skill,后续全部通过skill自动检查所有生成的前端代码是否符合规范。
坑 2:文档设计要详细化
最开始就只有一份“开发文档.md”,企图通过一份设计文档完成整个项目。但随着开发的进行,solo制作出来的内容越来越偏离我的设计期望,并且大多数时候根本不知道是哪里出现了问题,于是后面全部删除重来。
解决方案:这次要求solo基于“开发文档.md”按功能划分拆分出17个子系统功能文档以及子系统功能划分指南文档,提取“开发文档.md”内接口等设计规范,形成一份权威且统一的接口设计规范用于指导开发。所有文档提取完成后让solo进行交叉比对并优化,进行多轮迭代完善。
子系统功能划分文档目录
文档版本: v4.15.0
创建日期: 2026-04-20
更新日期: 2026-05-02
文档状态: 正式发布
所属域: 系统架构总览
- 文档概述
- 1.1 文档目的
- 1.2 适用读者
- 1.3 术语定义
- 1.4 文档索引
- 系统整体架构
- 2.1 架构设计原则
- 2.2 系统分层架构图
- 2.3 事件总线设计
- 2.4 域分类总览
- 核心业务域
- 3.1 图书域
- 3.2 搜索域
- 3.3 书架域
- 3.4 阅读域
- 支撑业务域
- 4.1 元数据域
- 4.2 插件域
- 4.3 协议域
- 4.4 同步域
- 基础设施域
- 5.1 身份域
- 5.2 权限域
- 5.3 存储域
- 5.4 调度域
- 5.5 通知域
- 5.6 日志域
- 5.7 备份域
- 5.8 统计域
- 5.9 配置域
- 5.10 架构守护域
- 域间交互关系
- 6.1 交互关系总览图
- 6.2 依赖关系矩阵
- 6.3 关键交互流程
- 数据流向说明
- 7.1 数据流向总览
- 7.2 核心数据实体流向
- 7.3 数据存储分布
- 接口设计规范
- 8.1 接口命名规范
- 8.2 统一响应格式
- 8.3 错误码规范
- 8.4 认证机制
- 附录
- 9.1 域功能清单汇总
- 9.2 技术栈汇总
- 9.3 版本历史
坑 3:前后端字段命名不一致
后端 Pydantic 模型使用 snake_case,前端 TypeScript 期望 camelCase。初期未统一 alias_generator 配置,导致大量字段映射错误。
解决方案:在后端 Pydantic 模型中统一配置 alias_generator=to_camel,前端通过 OpenAPI 自动生成类型定义,确保前后端类型完全一致。
坑 4:API 层直接操作数据库
开发初期部分 API 路由直接执行数据库操作,违反三层架构规范,导致业务逻辑散落在 API 层,难以维护和测试。
解决方案:建立架构守护脚本 check_api_db_operations.py,在 CI 和 Pre-commit 中自动检测违规操作,并系统性将所有 DB 操作下沉到 Service 层。
坑 5:SQLite 并发写入锁问题
SQLite 在并发写入时会出现 “database is locked” 错误,影响多任务同时执行的稳定性。
解决方案:实现 SQLiteWriter 串行化写入队列,所有写操作通过队列顺序执行,避免锁冲突。同时提供 PostgreSQL 升级路径。
坑 6:子系统间双向依赖
图书管理子系统与搜索服务子系统存在双向依赖:图书服务需要调用搜索服务更新索引,搜索服务又依赖图书数据,形成循环引用。
解决方案:引入事件总线(EventBus),图书域发布 BookCreated/BookUpdated/BookDeleted 事件,搜索域订阅这些事件异步更新索引,彻底解耦。
4. 成果展示
4.1 系统架构总览
┌─────────────────────────────────────────────────────────────┐
│ 表现层 (Vue 3 + TypeScript) │
│ 登录注册 │ 图书管理 │ 阅读中心 │ 个人中心 │ 管理后台 │ ... │
└──────────────────────────┬──────────────────────────────────┘
│ HTTP/REST API (JSON)
┌──────────────────────────▼──────────────────────────────────┐
│ API网关层 (FastAPI) │
│ 统一认证 │ 权限校验 │ 限流熔断 │ 请求日志 │
└──────────────────────────┬──────────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────────┐
│ 事件总线层 (EventBus) │
│ 事件发布 │ 事件订阅 │ 事件路由 │ 事件持久化 │
└──────────────────────────┬──────────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────────┐
│ 业务层 (18个业务域) │
│ 核心域: 图书 │ 搜索 │ 书架 │ 阅读 │
│ 支撑域: 元数据 │ 插件 │ 协议 │ 同步 │
│ 基础域: 身份 │ 权限 │ 存储 │ 调度 │ 通知 │ 日志 │ 备份 │ ... │
└──────────────────────────┬──────────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────────┐
│ 数据层 │
│ SQLite/PostgreSQL │ Redis │ 文件存储 │ 事件存储 │
└─────────────────────────────────────────────────────────────┘
4.2 技术栈
| 层级 | 技术选型 |
|---|---|
| 前端框架 | Vue 3.5 + TypeScript 5.9 + Vite 7 |
| UI 组件库 | NaiveUI 2.43 + Pro-NaiveUI |
| 状态管理 | Pinia 3.0 |
| 样式方案 | UnoCSS + SCSS |
| 图表可视化 | ECharts 6 + VChart 2 |
| EPUB 阅读 | @intity/epub-js |
| PDF 阅读 | pdfjs-dist 5 |
| 后端框架 | FastAPI 0.109 + Uvicorn |
| ORM | SQLAlchemy 2.0 (Async) |
| 数据库 | SQLite(默认)/ PostgreSQL(可选升级) |
| 缓存 | Redis(可选升级) |
| 全文搜索 | Whoosh + jieba + pypinyin |
| 异步任务 | Celery + APScheduler |
| 电子书处理 | ebooklib + PyMuPDF + pdfplumber |
| 认证安全 | JWT + bcrypt + cryptography |
| 代码质量 | ESLint + Black + Flake8 + MyPy |
4.3 核心功能截图说明—由于正在进行三层架构(API层、Service层、Model层)重构,导致部分页面显示异常,就没有截图展示了。
登录与注册:支持用户登录与注册。

图书管理:支持图书上传、元数据编辑、分类标签、批量操作、重复检测,列表与卡片双视图切换。
主题设置:支持主题自定义配置,布局视图切换。

在线阅读器:EPUB/PDF 双格式支持,具备目录导航、书签管理、笔记高亮、阅读设置(字体/主题/间距)、阅读进度追踪。
元数据刮削:自动从豆瓣获取书籍封面、简介、评分、ISBN 等元数据,支持多源聚合与智能匹配。
存储管理:多位置存储、去重清理、完整性校验、配额管理、容量预测、健康仪表盘。
任务调度:Cron 表达式编辑器、甘特图执行时间线、告警配置与历史记录。
统计分析:个人阅读时长/偏好/分类分布分析,管理员用户活跃热力图/存储趋势/图书增长趋势。
系统管理:RBAC 权限管理、用户管理、日志审计、备份恢复、插件管理、系统配置。
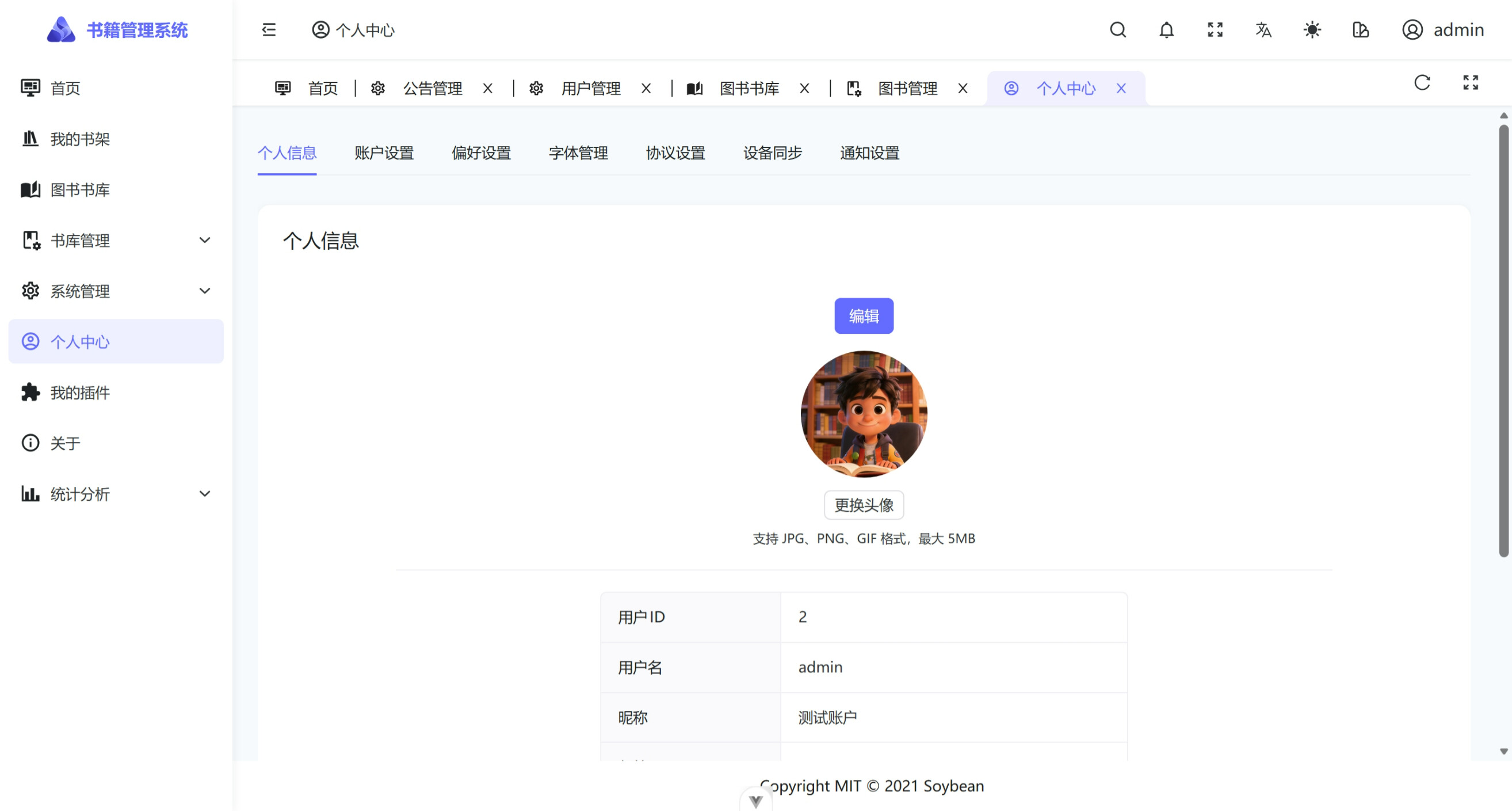
个人中心:个人信息编辑、账户设置、偏好设置、字体管理、协议设置(WebDAV、OPDS)、多设备同步、通知设置。
4.4 项目规模
| 指标 | 数量 |
|---|---|
| 业务域 | 17 个 |
| 后端 API 端点 | 100+ |
| 前端页面/组件 | 150+ |
| 数据库模型 | 25+ |
| 事件类型 | 20+ |
| 子系统文档 | 20+ |
5. 效果与总结
5.1 提效效果
| 维度 | 传统开发 | SOLO 辅助开发 | 提效比例 |
|---|---|---|---|
| 架构设计 | 1-2 周 | 1-2 天 | ~80% |
| 单个子系统开发 | 3-5 天 | 0.5-1 天 | ~75% |
| 代码审计与修复 | 2-3 天/轮 | 2-4 小时/轮 | ~85% |
| 文档编写 | 1-2 天/份 | 1-2 小时/份 | ~85% |
| 全项目交付 | 3-4 个月 | 高效交付 | ~70% |
5.2 SOLO 在流程中的角色
- 架构师:帮助设计 DDD 域划分、事件驱动架构、三层架构规范
- 全栈开发者:生成前后端核心业务代码,包括 API、Service、Model、组件、Composable
- 审计员:系统性代码审计,发现类型不一致、架构违规、安全隐患等问题
- 修复工程师:根据审计报告自动修复 P0/P1 级别问题
- 文档工程师:生成和维护子系统文档、接口规范、重构日志
5.3 可复用的方法
1. DDD + 事件驱动架构模式
对于中大型全栈项目,先按 DDD 原则划分业务域,再通过事件总线解耦域间依赖,是保证系统可维护性的有效方法。MemoryEventBus 适配单实例部署,RedisStreamEventBus 适配分布式场景,可平滑迁移。
2. 三层架构 + 架构守护
API → Service → Model 的严格分层,配合自动化架构守护脚本(检测 API 层违规 DB 操作),从机制上保证代码质量,避免架构腐化。
3. 前后端类型契约自动化
通过 OpenAPI 自动生成前端 TypeScript 类型定义,后端 Pydantic 模型统一 alias_generator=to_camel,从源头消除前后端类型不一致问题。
4. 多轮审计迭代
先完成功能开发,再进行系统性代码审计(P0→P1→P2→P3 逐级修复),比边写边查更高效,也更容易保证全局一致性。
5. SQLite 优先策略
个人项目优先使用 SQLite,零运维成本。通过 SQLiteWriter 串行化写入解决并发问题,同时保留 PostgreSQL 升级路径,兼顾简洁与可扩展性。
5.4 对 AI 工作方式的思考
-
AI 是加速器而非替代品:SOLO 极大加速了代码编写和问题修复,但架构决策、业务逻辑设计仍需开发者主导。最好的模式是"人定方向,AI 执行落地"。
-
Prompt 精度决定输出质量:越具体的需求描述(包含架构约束、命名规范、错误码规范等),SOLO 生成的代码质量越高。项目规则文件(project_rules.md)是保持一致性的关键。
-
迭代审计比一次完美更实际:先让 SOLO 快速生成功能代码,再通过多轮审计逐步完善,比要求一次生成完美代码更高效。
-
架构守护需要自动化:AI 生成的代码可能违反架构规范,必须配合自动化检查脚本(Pre-commit + CI),才能在开发过程中持续保证代码质量。
-
文档与代码同步演进:借助 SOLO 的文档生成能力,每次功能更新同步更新子系统文档,避免文档与代码脱节,这是传统开发中常被忽视的环节。
5.5 后续
现在处于开发后期的修复与优化阶段,开发完成后就会争取上架各个nas的官方商店供大家使用。
本项目全程使用 TRAE SOLO 完成,从架构设计到代码实现、从重构决策到审计修复,SOLO 始终是最高效的开发伙伴。