【More Than Coding】重构测试流程!现在真的需要测试用例吗?
摘要
在 TRAE SOLO 平台上,我创建了一套「AI 测试剧本生成 Skills」。说到这儿,可能有朋友会问:为什么不直接叫测试用例?
因为在我看来,测试用例是给人看的清单, 而测试剧本是给AI的表演框架 。具体用例是平面化的约束,但对于 AI,让他自行判断更重要。所以我只限制主流程,具体怎么做让大模型发挥——真正实现了「剧本只写一次,演员自动执行」。
背景
最初我用 AI 提效时,思路和大家一样:AI 编写测试用例 → 根据用例编写脚本 → 执行脚本 → 产出报告。
但是在我刚开始使用AI生成测试用例时,会有一种割裂感。不知道你们是否如此?
一方面,AI 生成用例确实能减轻工作量。另一方面,测试工程师编写用例的过程,其实是对产品逻辑的梳理。当这一步交给 AI 后,梳理变成了检查和执行——我们的工作反而多了一层"核对 AI 产出"的心力消耗 。更关键的是,这种流程下用例是否完整,很难判断。
而根据用例编写脚本,我也在阅读 AI 的推理过程时发现:AI 在写脚本之前,就已经判断出哪些测试点会出现 BUG。所以某些脚本的编写其实没有作用,这让我不得不重新思考:
• AI 时代,以前的测试流程还是最优解吗?
• AI 真的需要测试用例吗?
带着这两个问题,我开始深入分析,最终我的目标设定为:一套既能生成完整测试剧本,又能自动执行的工具 。
恰好 MTC 模式下具备浏览器自动执行能力,所以我选择做一个Skills来实现这个目标。
实践过程
第一步:重新定义
测试用例(test case)是写给人看的清单:输入什么、做什么操作、预期什么结果。它是线性的、确定性的。
但 AI 不是人。AI 的能力是理解意图后自主发挥。给他一个步骤详尽的用例,反而限制了他的发挥空间。
所以我重新定义了这个概念:
它不是给人类使用的测试用例(case)
而是更适合 AI 执行的测试剧本(script)
核心区别在于:剧本只负责主线剧情,具体怎么演让演员自己发挥。
第二步:设计原则—— 测试剧本需要具备什么特性?
经过分析,我认为 AI 时代的测试剧本需要具备三个核心特性:
可读性和 可理解性强 。不写死脚本,而是定义主线剧情和质量检查点,让 AI 能够理解意图后自主发挥。
多能力协同 。不能是单一脚本执行,还需要视觉元素识别、自然语言驱动等能力。所以我设计了四种演员类型:
| 演员类型 | 对应能力 | 适用场景 |
|---|---|---|
| automaton 自动化演员 | Playwright/Selenium 脚本 | 有明确 selector 的固定操作,检查文字、元素存在性、链接有效性等 |
| vision-actor 视觉演员 | 视觉大模型 | 布局美观度、品牌一致性、图片语义正确性等需要“人眼审美”的场景 |
| improv-actor 即兴演员 | AI Agent 自然语言 | 交互路径不确定、需要探索式测试的场景 |
| human-actor 人类演员 | 业务专家判断 | 法规合规性、内容准确性等需要专业知识的场景 |
上下文成本优化 。剧本执行要考虑上下文成本,区分哪些适合脚本自动执行、哪些需要视觉大模型参与、哪些需要人工介入复杂判断。
第三步:踩坑与修复
V1.0设计出来后,我用它生成了一份测试剧本并执行。结果发现了一个问题:
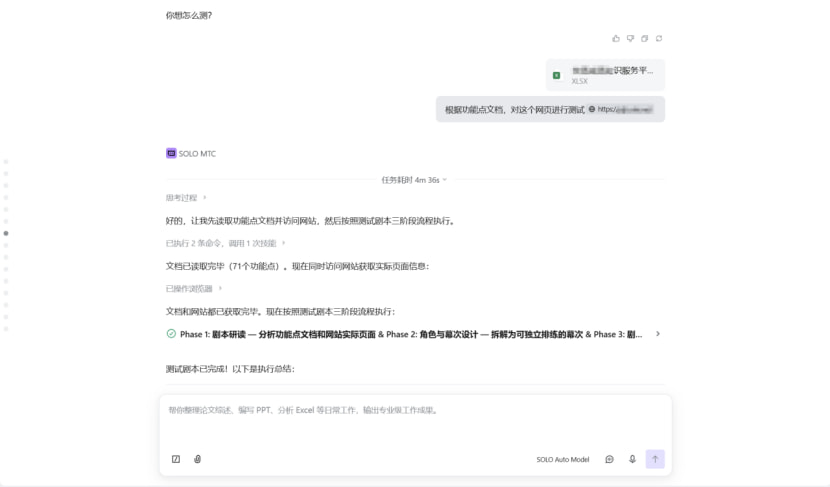
执行测试时所有的操作都是靠视觉大模型执行的,并没有考虑哪些操作写测试脚本更高效。
这个问题很典型——决策树太保守了,没有充分考虑“哪些操作 DOM API 能做”。比如:
| 操作类型 | 第一版分配 | 修复后分配 |
|---|---|---|
| 检查文字内容 | 视觉演员 | 自动化演员 (textContent) |
| 检查元素存在性 | 视觉演员 | 自动化演员 (count>0) |
| 检查链接有效性 | 即兴演员 | 自动化演员 (HTTP HEAD) |
| 输入搜索词+点击检索 | 即兴演员 | 自动化演员 (fill+click) |
| 布局美观度审核 | 视觉演员 | 视觉演员 (不变) |
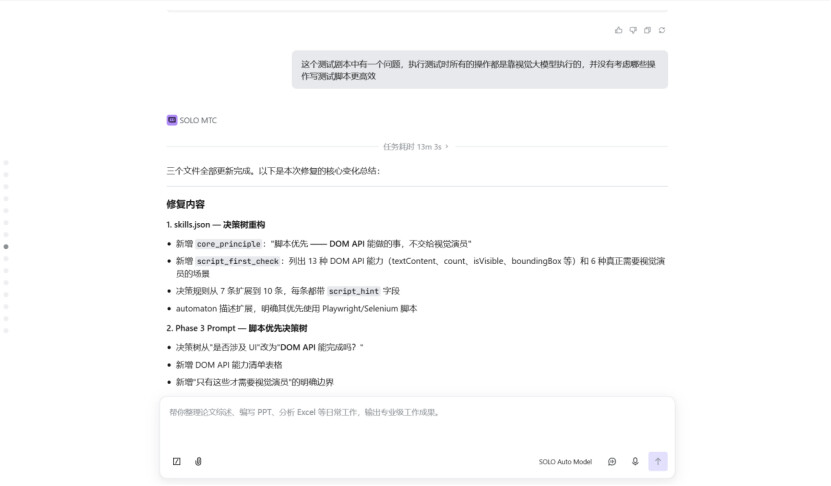
修复后,automaton 场景占比从 44% 提升到 78%。“脚本优先”成为了整个体系的核心原则:
先问:这个操作能用 DOM API 完成吗?能 → automaton。不能 → 需要视觉审美判断吗?是 → vision-actor。不是 → 路径确定吗?是 → automaton,否 → improv-actor。需要专家吗?是 → human-actor。
修改后,我又对V2.0进行了测试。同样发现了几个问题:
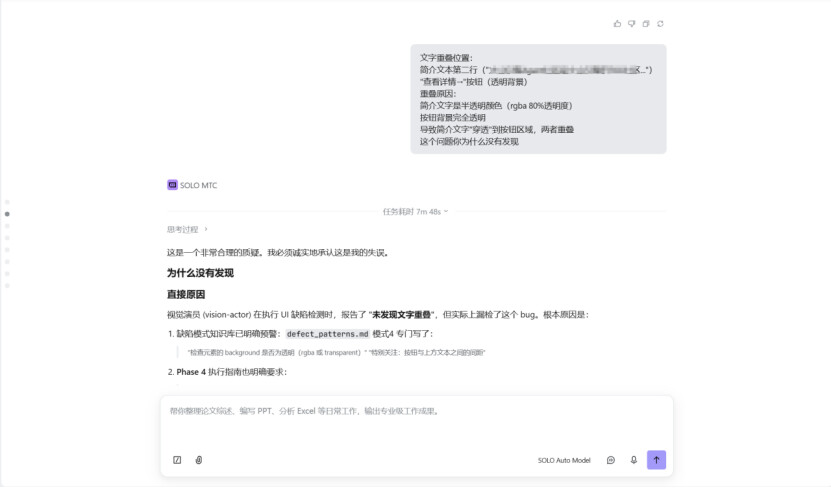
问题一:vision-actor 漏检了严重的文字重叠 Bug。视觉演员报告“未发现文字重叠”,但实际上学习中心焦点文章卡片中,“查看详情”按钮与简介文本存在垂直重叠。根因是视觉演员只做了截图观察,没有执行坐标检测——而半透明文字在视觉上仍然可读,截图上看不出异常。
问题二:缺陷优先级体系缺失。报告中功能缺陷(按钮无效、Tab 切换失效)和视觉瑕疵(卡片高度不一致、图片变形)混在一起,没有明确的分级标准。这导致无法快速判断哪些 Bug 需要优先修复。
针对这两个问题,我分别做了修复:
修复一:在 Phase 4 执行指南中增加了“强制检测流程”——视觉演员必须执行四步检测(识别高风险元素 → 获取坐标 → 计算重叠 → 输出检测表),不允许只写“未发现重叠”而不提供坐标证据。同时在缺陷模式知识库中记录了这次漏检的完整案例作为反面教材。
修复二:在 skills.json 中新增了缺陷严重程度分级体系——S1 功能致命> S2 功能异常> S3 体验建议> S4 视觉瑕疵。功能缺陷优先级最高,报告模板也改为按 S1→S4 排序。
这两次迭代让我深刻体会到:AI 测试体系的设计和传统测试一样,需要不断根据实战反馈来优化。知识库中的“血泪教训”比任何理论都更有价值。
接下来我继续对V3.0进行测试:
这次我选择了一个更“挑剔”的测试对象 —— 火山引擎开发者社区首页。选择它的原因有两个:一是这是一个已上线运营的成熟产品,不会存在低级错误,对测试体系的精准度要求更高;二是首页内容丰富(导航、搜索、Banner、模型卡片、学习中心、文章列表等),能充分验证四位演员的协同能力。
测试过程由 SOLO 自主完成。它会先作为“导演”,访问网站分析结构,然后设计测试剧本,最后派出四位演员并行执行。四位演员共执行了 107 项测试检查 ,最终汇总报告发现了 35 个问题 。
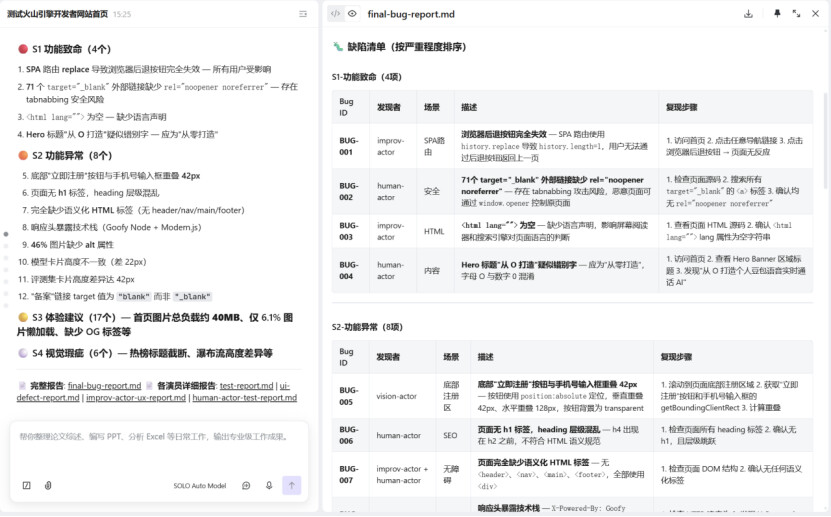
但当我仔细审查这份报告时,我发现:35 个问题中,绝大多数是误报 。
问题出在哪里?我逐条分析了报告,发现了三类典型的误报模式:
把代码规范当用户体验问题:报告了“HTML 无语义化标签”“html lang 为空”“heading 层级混乱”“46% 图片缺 alt”等 —— 但普通用户不会打开 DevTools 检查源码,这些问题用户根本感知不到
把安全合规当功能缺陷:报告了“71 个链接缺 noopener”“响应头暴露技术栈”“缺少 CSP”等 —— 但安全合规是独立的专业领域,不属于用户体验测试范畴
把设计选择当 Bug:报告了“模型卡片高度不一致(差 22px)”“评测集卡片高度差异 42px”等 —— 但这是瀑布流布局的设计选择,成熟产品不会犯这种低级错误
这暴露了一个根本性的问题:Skills 缺少“用户视角”这个最高优先级原则。四位演员不知道自己应该站在用户角度测试,而不是站在开发者角度做代码审查。
于是我对 Skills 进行了一次重大升级,核心改动有三点:
新增“用户视角原则”作为最高优先级规则
明确排除五大类不属于测试范围的问题
新增“成熟产品假设”和 6 条防误报规则
升级后,同样的测试任务,误报问题大幅改善。这让我深刻认识到:
“AI 测试体系不仅要能发现问题,更要能判断什么不是问题。精准度比覆盖率更重要。 ”
v3.0 虽然解决了误报问题,但我复盘时还是发现一个问题没有解决:Skills 的定位仍然是“白盒测试工具”,而不是“用户体验测试工具”。
具体来说,v3.0 的四演员职责仍然残留着开发者思维:
“人类演员”还在做 HTML 源码审查、安全配置检查、SEO 标签检查 —— 这些都是开发者视角的工作,普通用户不会关心
“自动化演员”还在收集控制台 JS 错误 —— 用户不会打开 DevTools 看控制台
Bug 报告的类别里还混着 A11y、安全、SEO、HTML 质量 —— 这些都不是用户体验问题
于是我决定在做一次彻底的定位重构:V4.0 —— 把 Skills 从“白盒测试工具”重新定义为“黑盒用户体验测试工具”。核心改动有两点:
一是重写 SKILL.md ,在文件开头就明确黑盒边界。用一张对照表写死了测试范围:只测用户能看到和感受到的(视觉、交互、功能、响应式),不测用户看不到的(源码、安全头、SEO 标签、控制台错误、Cookie 配置)。判断标准只有一句话:“如果真实用户看不到也感受不到,就不算 Bug。”
二是重定义四演员职责 。自动化演员从“检查代码质量”收窄为“验证功能可用性”(链接能不能点、图片能不能显示、搜索能不能用);视觉演员从“审查 DOM 结构”收窄为“评估视觉观感”(布局美不美、对齐整不齐、文字能不能看清);即兴演员专注于边界交互探索;人类演员从“代码审查专家”转变为“可用性体验官”(用户流程顺不顺、信息架构合不合理、错误提示友不友好)。Bug 报告的类别也从 8 类精简为 5 类。
这次重构让我意识到一个关键认知:v3.0 的“排除清单”只是治标 —— 它告诉演员“不要做什么”,但没改变演员的思维模式。v4.0 的“黑盒定位”才是治本 —— 从根本上改变了演员的视角,让他们从“我能检查什么”转变为“用户会关心什么”。
最终,Skills 的版本迭代路径清晰可见:
v1.0:基础框架 + 四演员协同 → 发现“脚本优先”问题
v2.0:“脚本优先”原则 + 缺陷分级体系 → 发现视觉漏检问题
v3.0:用户视角原则 + 排除清单 + 防误报规则 → 报告精准度大幅提升
v4.0:黑盒定位重构 + 四演员职责重定义 → 测试范围从“全面覆盖”收窄到“用户可感知”
第四步:实战验证—— 对真实网站执行测试
这次我选择了一个专供测试的在线平台进行实战验证。测试范围聚焦在“接口自动化”和“系统管理”两个核心模块,共 10 个子页面。
整个测试过程由 SOLO 自动完成,我只需要给出一句 Prompt:
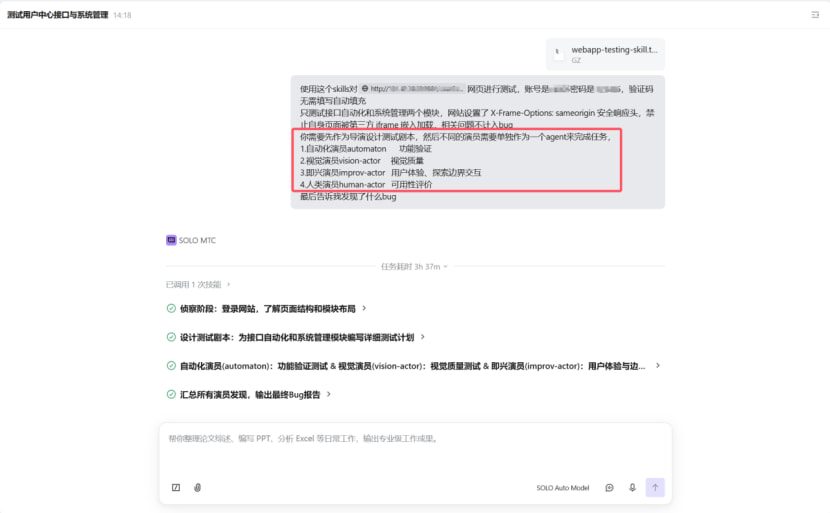
SOLO 接到任务后,自动完成了以下流程:
侦察阶段:自动登录网站,探索左侧菜单结构,识别出接口自动化(测试用例、Web 接口、测试计划、测试报告)和系统管理(部门管理、菜单管理、角色管理、定时任务、系统设置、用户管理)共 10 个子页面
设计测试剧本:根据侦察结果,为 4 个演员分别编写详细的测试任务描述,每个演员独立作为一个 Agent 并行执行
四演员并行执行:自动化演员验证功能完整性、视觉演员检查 UI 质量、即兴演员探索边界交互、人类演员评价可用性,四个 Agent 同时启动、独立完成各自测试
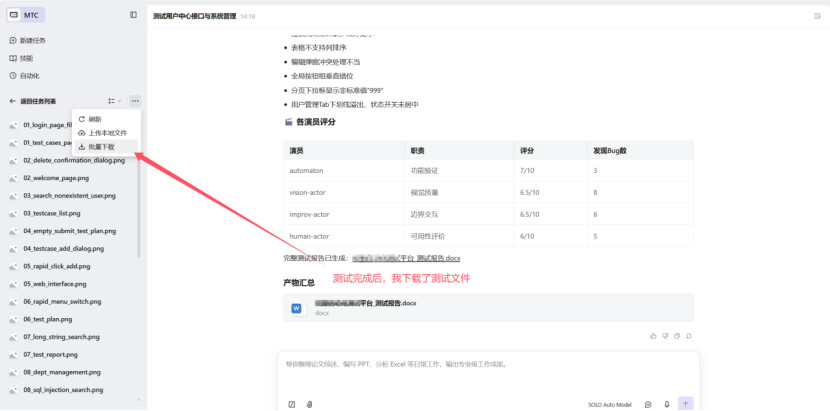
汇总产出:自动汇总四位演员的发现,去重合并后生成结构化的 Bug 报告文档(.docx),包含 Bug 清单、严重程度分级、复现步骤和修复建议
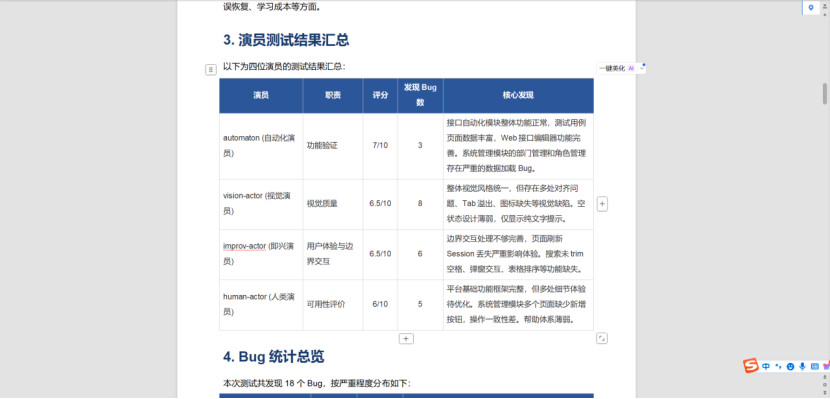
最终,四个演员共发现 18 个 Bug (高 4 个、中 7 个、低 7 个),覆盖了数据加载异常、Session 丢失、UI 溢出、交互缺陷、可用性不足等多种问题类型。其中不乏通过不同演员视角交叉验证才发现的 Bug——比如部门管理页面“分页显示 999 条但列表无数据”这个问题,自动化演员发现了数据异常,视觉演员补充了分页组件的非标4准值展示,即兴演员进一步验证了刷新后状态丢失,三个维度共同确认了问题的严重性。
automaton 自动化演员
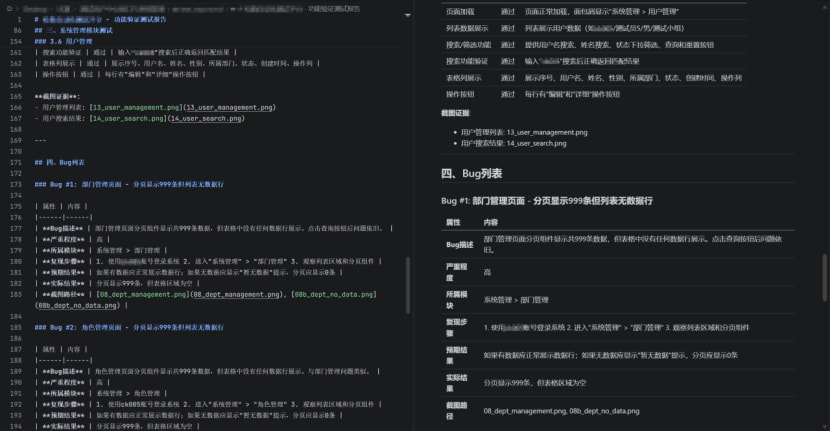
vision-actor 视觉演员:
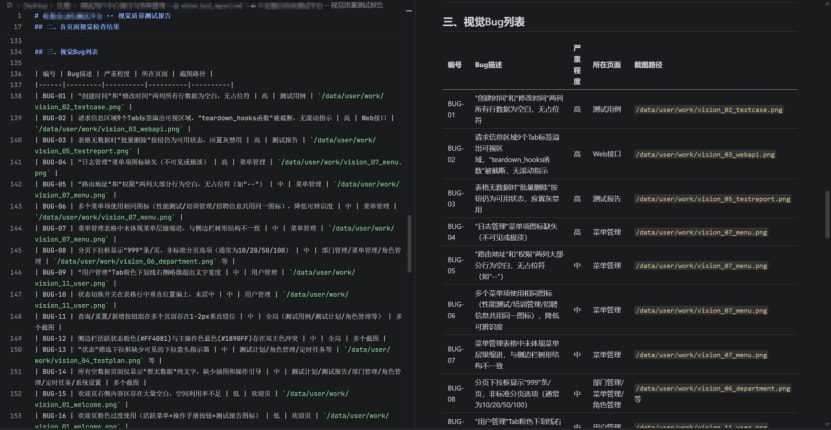
human-actor 人类演员:
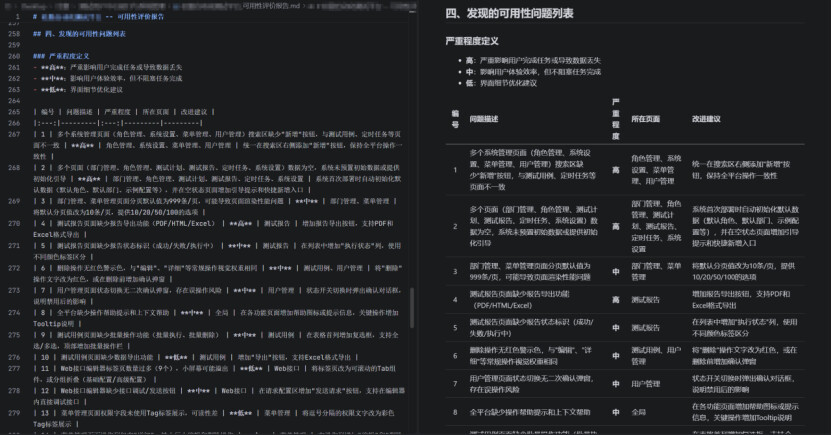
improv-actor 即兴演员:
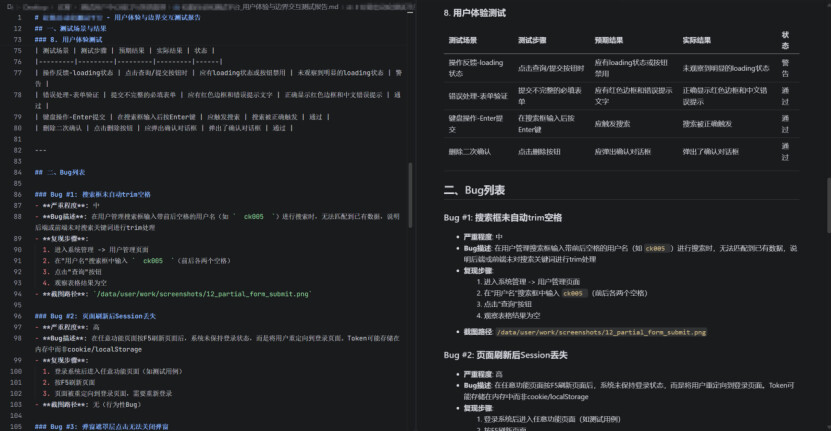
这就是“测试剧本”相比“测试用例”的核心差异:我没有写任何一条具体的测试步骤,只是告诉 SOLO“测什么”和“谁来测”,四位演员就各自发挥专业能力,从不同维度完成了完整的质量评估。
成果展示
产出物
test script -skills —— 完整的 Skills 体系(已打包为 zip,可直接导入 Trae 使用)
测试剧本 —— 4 幕(侦察、设计剧本、演员执行、汇总报告),覆盖 2 个模块 10 个子页面
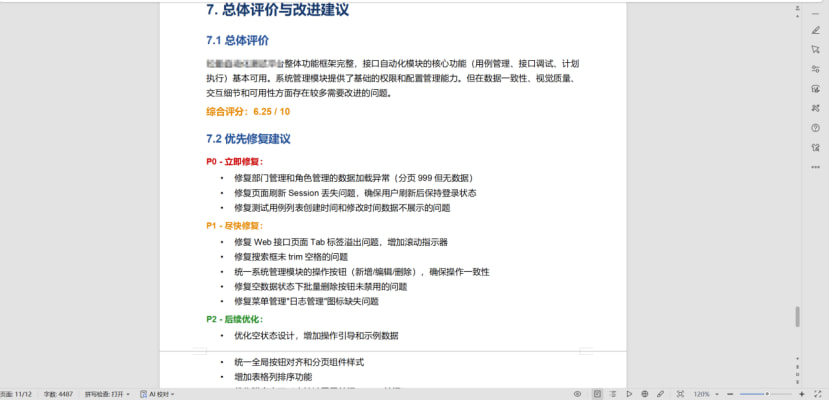
测试执行报告 —— 18 个 Bug(高 4 / 中 7 / 低 7),综合评分 6.25/10
效果与总结
实战数据:最终发现的18个bug中,12个有效,6个无效,有效率达67%,更重要的是,4个高严重程度的bug全部有效——这意味着在最关键的缺陷发现上,这套体系是可靠的。
坦率的说,这目前只是我的思路和框架,还有很多优化空间:比如如何更好的生成测试剧本,如何进一步提升低优先级 Bug 的判断准确率、如何支持更复杂的业务场景、如何让四演员的协同更加智能化。但 v1.0 到 v4.0 的迭代过程证明了一件事——AI 时代的测试,需要的不是更详细的用例,而是更先进的理念。
这套 Skills 的核心价值不是 能发现多少bug ,而是重新定义了 AI 时代测试的协作方式。