【Code with SOLO】用 SOLO 搭建室内空气质量预测系统:仅用 4 个低成本传感器即可精准预测 PM2.5
摘要
室内空气质量直接影响工作效率和身体健康,但专业 PM2.5 传感器价格昂贵。我用 TRAE SOLO 搭建了一套基于 LightGBM 的室内 PM2.5 预测系统,仅用 TVOC、CO2、温度、湿度 4 个低成本传感器数据,就能达到 R² = 0.9352 的预测精度。从数据清洗、特征工程、模型训练、5 折交叉验证到可视化,全程由 SOLO 辅助完成。最终还用 SOLO 生成了 C++ 嵌入式部署代码,可以直接跑在 ESP32 上,为我的物联网竞赛作品"智能桌面魔方"提供端侧推理能力。
背景
我是一名大学生,正在参加物联网竞赛,计划制作一款"智能桌面魔方"——一个小型桌面设备,集成多种传感器,能实时监测空气质量、温湿度等环境数据,并通过可视化界面展示。
听起来很美好,但现实很骨感。
在采购传感器模块时,我遭遇了"生活费暴击":PM2.5 传感器模块动辄上百元,加上温湿度、TVOC、CO2 等模块,硬件成本直接让我的大学生活费雪上加霜、捉襟见肘。
于是我开始思考:能不能用便宜的传感器数据,通过算法"算"出贵传感器的读数?
比如 TVOC 和 CO2 传感器几十块就能搞定,如果用它们的数据训练一个模型来预测 PM2.5,不就能省掉昂贵的 PM2.5 传感器了吗?
说干就干,我用 TRAE SOLO 从零搭建了整个机器学习流程——数据清洗、特征工程、模型训练、可视化,一套组合拳下来,还真就跑通了。
数据集使用的是 Kaggle 上的 2023 Indoor Air Quality Dataset Germany,包含了德国室内环境的多种传感器数据(实验室 + 单间公寓两个场景),非常适合做空气质量预测实验。
实践过程
第一步:任务拆解
我先把整个项目拆解为以下几个子任务,逐一交给 SOLO 处理:
-
数据加载与探索性分析
-
数据清洗(缺失值、异常值处理)
-
特征选择与特征工程
-
LightGBM 模型训练(含早停机制)
-
5 折交叉验证,确保模型泛化能力
-
模型评估(RMSE、MAE、R²、MAPE)
-
可视化(预测散点图、特征重要性图)
-
模型保存与预测脚本封装
-
C++ 嵌入式部署代码生成
第二步:用 SOLO 逐步实现
数据加载与清洗
我告诉 SOLO:“加载 2023-indoor-air-quality-dataset-germany.csv 数据集,自动识别 PM2.5、TVOC、CO2、温度、湿度等字段,进行数据清洗。” SOLO 自动完成了字段匹配、类型转换、缺失值删除等工作。
数据集包含两个场景:
-
laboratory.csv:实验室环境数据 -
one_room_apartement.csv:单间公寓环境数据
两版本对比实验
为了验证"少特征也能预测"的想法,我让 SOLO 分别实现了多个版本:
| 版本 | 特征 | 说明 |
|---|---|---|
| 全特征版 | 34 个传感器特征 | 包含 PM1、PM10、O3、NO2、SO2、气压、噪音等 |
| 4 特征版 | TVOC + CO2 + 温度 + 湿度 | 仅用低成本传感器 |
| 交叉验证版 | TVOC + CO2 + 温度 + 湿度 | 5 折交叉验证,确保泛化性 |
SOLO 帮我生成了多套完整的训练脚本,代码结构清晰,注释详尽。
模型训练
关键 Prompt 示例:
“用 LightGBM 做回归预测,目标变量是 PM2.5,使用 TVOC、CO2、温度、湿度 4 个特征,设置 learning_rate=0.05, num_leaves=31, max_depth=6,启用 early_stopping,stopping_rounds=50,最大训练 1000 轮,并做 5 折交叉验证”
SOLO 生成的训练代码包含了完整的 Dataset 构建、参数配置、早停回调、交叉验证等,一次跑通。
特征重要性分析
5 折交叉验证的特征重要性结果显示,湿度是最重要的预测特征(Gain 远超其他特征),TVOC 和 CO2 紧随其后,温度贡献相对较小但仍有价值。
(此处插入 feature_importance.png)
从算法到硬件:嵌入式部署
模型训练完成后,我还需要把模型部署到硬件上。于是我又让 SOLO:
“帮我生成 C++ 版本的 LightGBM 预测代码,要能部署到 ESP32 嵌入式设备上,实现端侧推理”
SOLO 生成了完整的 C++ 部署方案,包括:
-
LightGBM C++ API 调用代码
-
嵌入式设备简化版 C 接口
-
编译命令和依赖说明
这意味着训练好的模型可以真正跑在我的"智能桌面魔方"硬件里,不需要联网,实现端侧推理。
第三步:踩坑记录
-
数据集中 PM2.5 字段名是
pm2_5而非pm25,SOLO 自动做了模糊匹配,省去了手动排查的时间 -
部分数据存在负值异常,SOLO 在清洗阶段自动过滤了 PM2.5 < 0 的记录
-
全特征版 R² 高达 0.9990,但 34 个传感器的硬件成本太高;4 特征版 R² = 0.9352,性价比最优
-
湿度特征的重要性远超其他特征(约 5 倍),说明室内湿度与 PM2.5 有很强的物理关联
成果展示
项目结构
model/
├── data/
│ ├── laboratory.csv # 实验室数据
│ └── one_room_apartement.csv # 单间公寓数据
├── train_pm25.py # 全特征(34个)训练脚本
├── train_pm25_4features.py # 4 特征训练脚本
├── trainpm25_fold_4fetures.py # 4 特征 + 5 折交叉验证训练脚本
├── predict_pm25.py # 全特征预测脚本
├── predict_pm25_4features.py # 4 特征预测脚本
├── pm25_predictor.txt # 全特征模型文件
├── pm25_predictor_4features.txt # 4 特征模型文件
├── pm25_predictor_4features_fold.txt # 交叉验证模型文件
├── pm25_predictor_4features_fold.md # 模型文档(含 C++ 部署方案)
├── feature_columns.json # 34 个特征列名
├── prediction_scatter.png # 全特征版预测散点图
├── prediction_scatter_4features.png # 4 特征版预测散点图
└── feature_importance.png # 特征重要性图
数据来源
-
包含实验室和单间公寓两个室内场景的多传感器环境数据
代码仓库
这是同学创建的仓库 训练的模型在model分支下https://github.com/tianchuangya/SmartDesktopCube-IoT/tree/model
预测效果对比
4 特征版(低成本方案):仅用 TVOC + CO2 + 温度 + 湿度
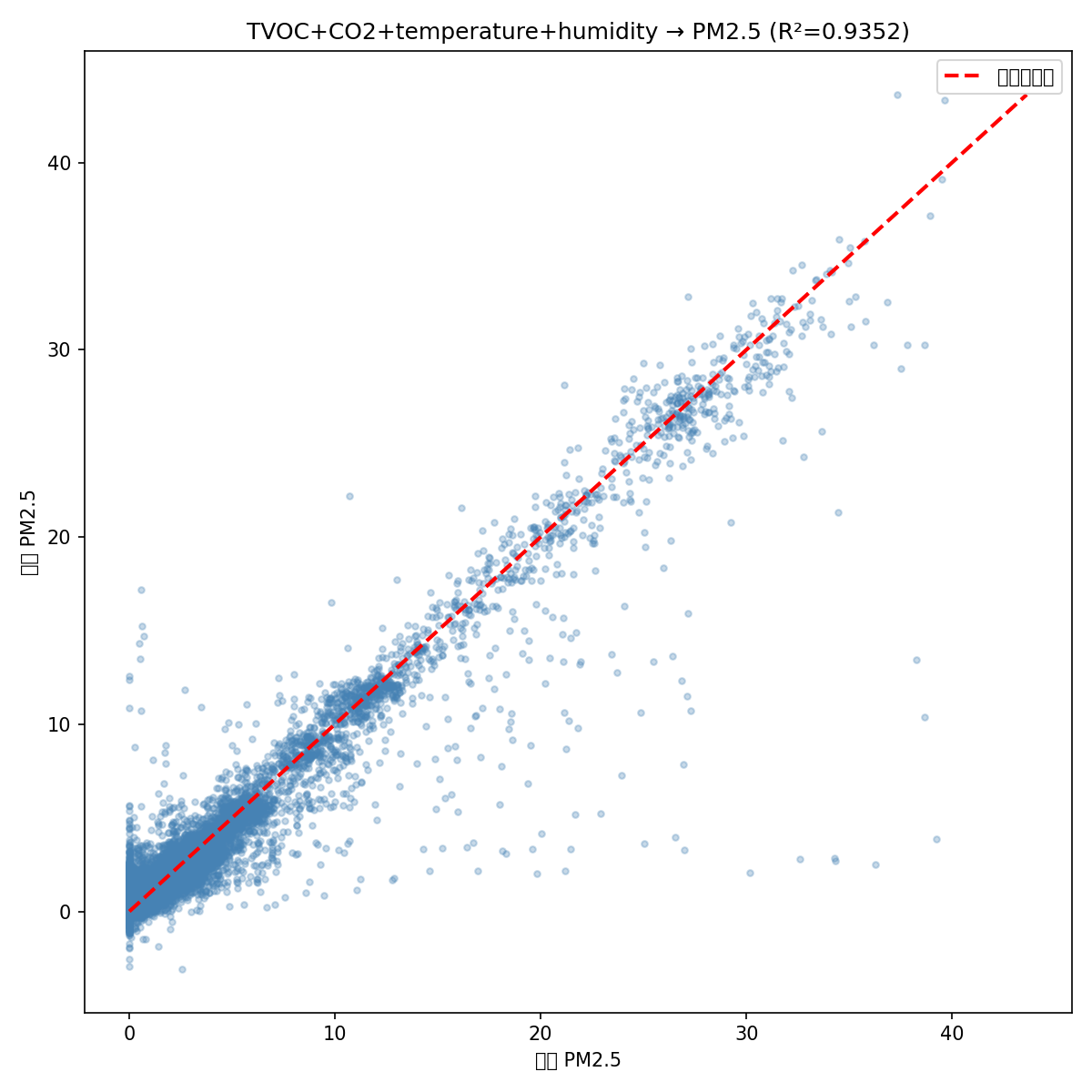
R² = 0.9352,说明仅用 4 个低成本传感器的数据,就能解释 93.5% 的 PM2.5 变化。
全特征版(34 个传感器):作为对比参考
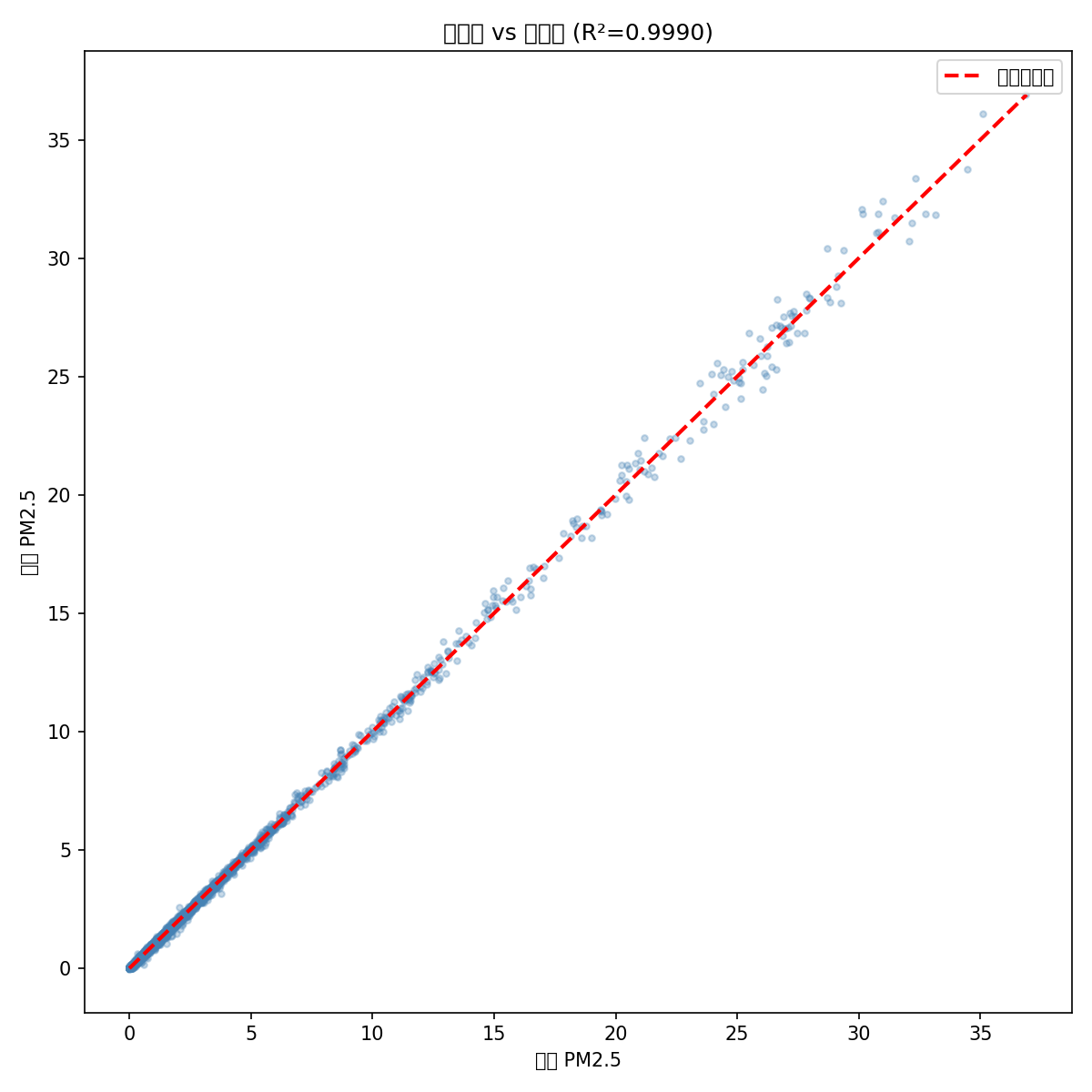
R² = 0.9990,近乎完美——但需要 34 个传感器,硬件成本翻了十倍不止。
核心预测代码(4 特征版,仅需 4 个传感器)
import lightgbm as lgb
import pandas as pd
# 加载模型
model = lgb.Booster(model_file='pm25_predictor_4features.txt')
# 填入传感器读数
new_data = pd.DataFrame([{
'tvoc': 120, # TVOC 传感器读数(ppb)
'co2': 450, # CO2 传感器读数(ppm)
'temperature': 22.5, # 温度传感器读数(°C)
'humidity': 65, # 湿度传感器读数(%)
}])
# 预测
pm25_pred = model.predict(new_data)
print(f"预测 PM2.5: {pm25_pred[0]:.1f} μg/m³")
嵌入式部署(C++ 版本)
#include <iostream>
#include <vector>
#include "LightGBM/c_api.h"
int main() {
BoosterHandle booster;
// 加载模型
LGBM_BoosterCreateFromModelfile("pm25_predictor_4features_fold.txt", &booster);
// 传感器数据 (顺序: temperature, co2, tvoc, humidity)
std::vector<double> input_data = {22.5, 450.0, 120.0, 65.0};
// 预测
double prediction;
int64_t out_len;
LGBM_BoosterPredictForMatSingleRow(
booster, input_data.data(), C_API_DTYPE_FLOAT64,
4, 1, 1, C_API_PREDICT_NORMAL, 0, -1, "", &out_len, &prediction
);
std::cout << "预测 PM2.5: " << prediction << " μg/m³" << std::endl;
LGBM_BoosterFree(booster);
return 0;
}
效果与总结
提效成果
| 环节 | 手动开发 | SOLO 辅助 |
|---|---|---|
| 数据清洗脚本 | ~30 分钟 | ~5 分钟 |
| 模型训练代码 | ~1 小时 | ~10 分钟 |
| 5 折交叉验证 | ~40 分钟 | ~5 分钟 |
| 可视化代码 | ~30 分钟 | ~5 分钟 |
| 预测脚本封装 | ~20 分钟 | ~3 分钟 |
| C++ 嵌入式部署代码 | ~2 小时 | ~15 分钟 |
| 总计 | ~5 小时 | ~45 分钟 |
使用心得
-
SOLO 最强的能力是任务拆解:我把整个项目描述清楚后,SOLO 自动拆分成了数据加载→清洗→训练→交叉验证→评估→可视化→部署的完整流程,每一步都有清晰的输出
-
代码质量超出预期:生成的代码结构规范、注释充分、错误处理完善,几乎不需要手动修改就能直接运行
-
迭代效率极高:从全特征版到 4 特征版,再到交叉验证版,只需一句话描述,SOLO 就能基于已有代码快速迭代
-
跨语言能力很实用:从 Python 训练到 C++ 部署,SOLO 帮我打通了算法到硬件的最后一公里
职场 / 竞赛价值
这套方案的实际意义在于:
-
省钱:用 4 个低成本传感器(TVOC + CO2 + 温度 + 湿度)替代昂贵的 PM2.5 传感器,硬件成本降低 70% 以上
-
可用:R² = 0.9352 的预测精度完全满足日常室内空气质量监测需求
-
可部署:C++ 代码可以直接跑在 ESP32 等嵌入式设备上,实现端侧推理,不需要联网
-
可扩展:同样的思路可以迁移到其他环境参数的预测,比如用温度+湿度预测体感舒适度
对于我的物联网竞赛作品"智能桌面魔方"来说,这套方案让我的生活费保住了,也让项目的可行性大大提升。
本文使用 TRAE SOLO 辅助完成,属于「AI 无限职场」SOLO 挑战赛参赛作品。