1. 项目概述
我希望解决一个工程管理人员最头疼的问题:
施工进度计划每次都要靠人工一点点抠,效率低、改起来麻烦、还容易出错。
于是,我用 Trae 以 Solo 模式开发了这个 《BIM施工进度智能编制工作台》。
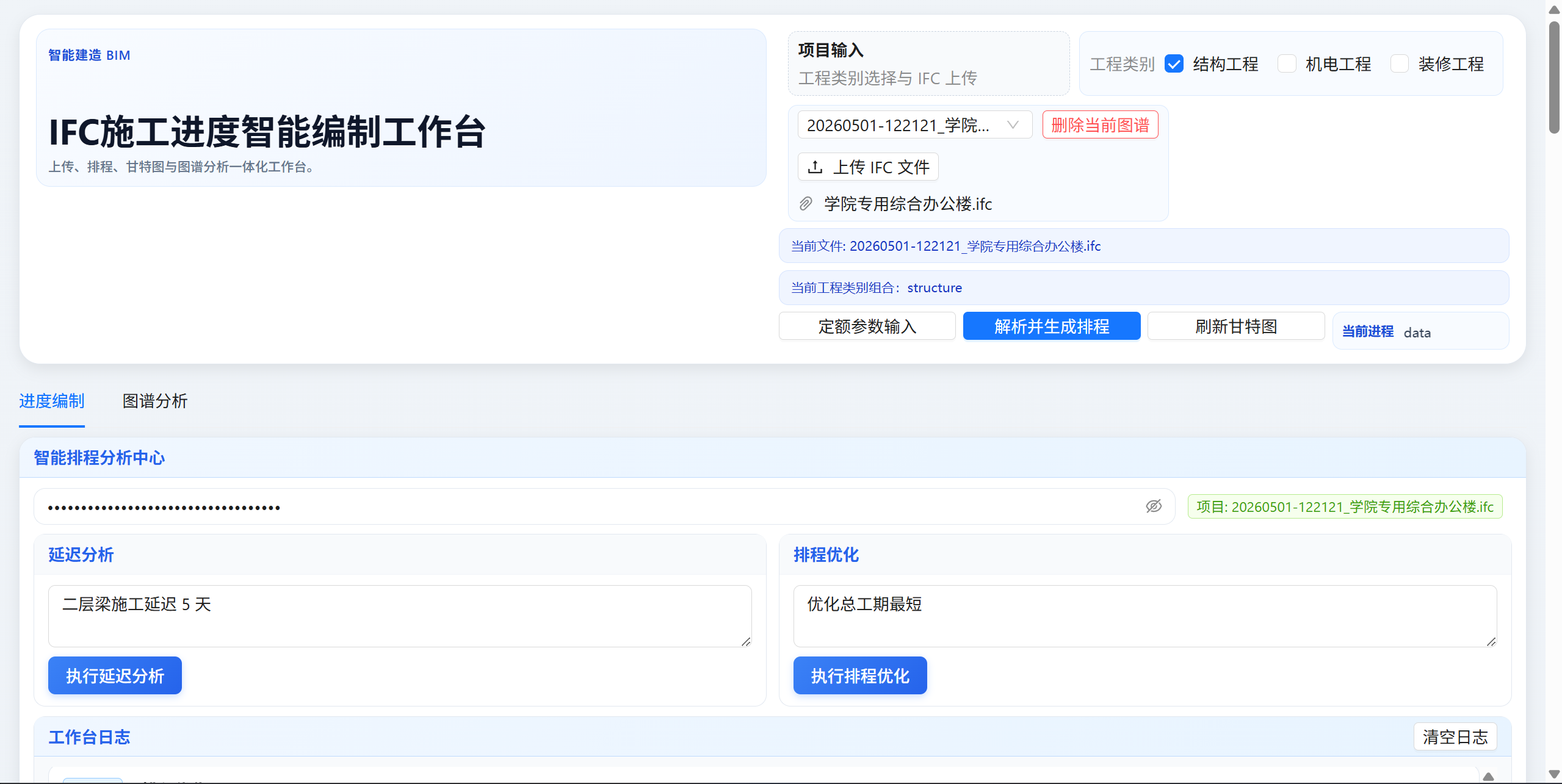
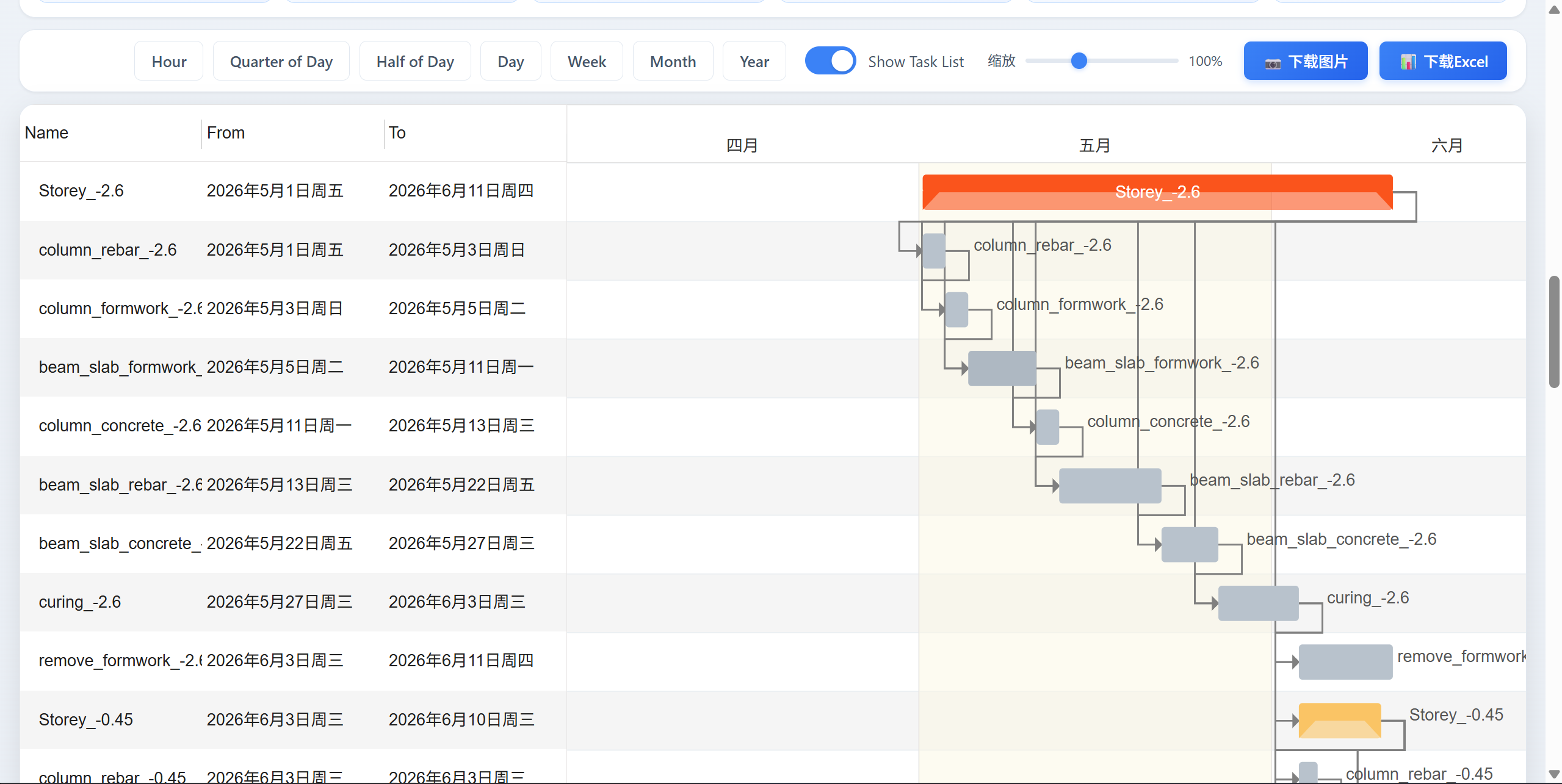
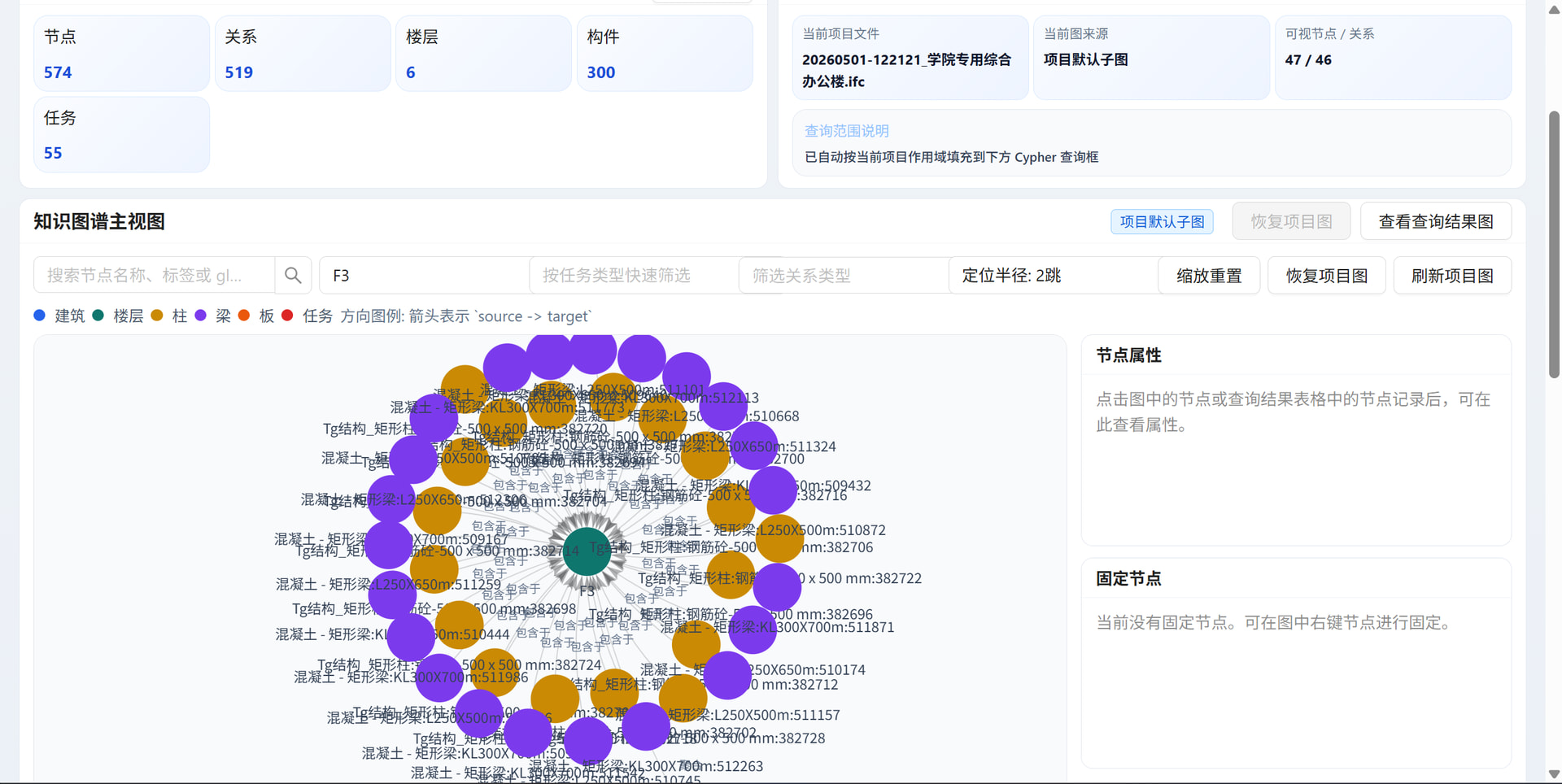
它的目标非常简单直接:
让工程人上传一个 IFC 模型文件,就能快速、自动、智能地生成一份靠谱的施工进度计划,并支持后续动态调整和优化。
1.1 核心功能
-
一键解析 IFC 模型:上传建筑模型后,自动识别楼层、柱、梁、板等构件信息(已支持结构工程,可后续扩展机电、装修)。
-
智能图谱构建:在后台用 Neo4j 建立构件之间的关系网络,让系统“懂”建筑是怎么搭起来的。
-
AI 自动排进度:结合大语言模型(DeepSeek),理解施工逻辑,自动生成任务序列和甘特图。
-
甘特图可视化:直观展示进度计划,支持任务依赖查看和手动微调。
-
定额灵活配置:可以根据实际项目情况调整各工序的班组人数和单位定额,让计划更贴合现场。
1.2 技术架构
后端基于 Python + Flask,前端使用 React + TypeScript + Vite,数据库采用 Neo4j 图数据库,并通过 Docker 一键部署。目前已成功跑通从模型上传到智能排程的完整流程。
2. 为什么要做这个工具?
作为工程管理人员,我深知传统进度编制有多痛苦:
-
每次都要靠经验手动排,耗时耗力
-
设计一改,进度计划就要大改,经常返工
-
任务逻辑复杂,容易漏项或冲突
-
团队沟通时缺乏直观的可视化工具
我希望做出一个真正能给自己和同行减负的趁手工具——上传模型后,几分钟内就能得到一份靠谱的初始进度计划,即使要调整,也可以很快输出新的排程,而不是花4-5个小时重复枯燥的劳动,大幅提升工作效率,也让后续调整变得轻松很多。
3. 实现过程(Solo模式)
整个项目我都是用 Trae 以 Solo 模式开发的:
-
技术选型:Python + Flask(后端)、React + TypeScript(前端)、Neo4j(图数据库)、ifcopenshell(IFC解析)、DeepSeek(大模型)
-
核心突破:从 IFC 模型解析 → 构建中文知识图谱 → LLM 智能排程 → 甘特图可视化,实现了端到端的自动化流程
-
关键功能:支持人工定额配置、延迟分析、智能优化排程等实用特性
-
部署方式:使用 Docker 容器化,已部署到云服务器,可远程访问
在这个项目中,TRAE 的 Agent(SOLO)主要发挥了以下几大自主能力:
- 全局代码检索与理解 (Codebase Search & Read) :
- 不需要您告诉我文件在哪。通过 SearchCodebase 和 Glob 工具,我自主找到了负责图谱生成的 mixins.py 和负责过滤的 graph_view_utils.ts 。
- 环境探测与终端控制 (Terminal Execution) :
- 当您反馈“后端没启动”时,我没有盲目改代码,而是使用 RunCommand 跑了 curl http://127.0.0.1:5000/graph/summary 和 docker ps -a 。发现是 Neo4j 容器没开,并直接通过 docker start neo4j 帮您拉起了数据库。
- 跨栈协同修改 (Full-Stack Edit) :
- 在实现“删除指定图谱”功能时,我同时在后端 app.py 写了 DELETE 接口,并在前端 App.tsx 加了清空状态的逻辑,一次性打通前后端。
- 自主编译与排错 (Auto-Debugging) :
- 在修改前端 filterGraphData 的多跳(Multi-hop)逻辑后,触发了 TypeScript 的 Set 和 includes 编译报错。我自主分析出是编译目标版本过低,通过修改 tsc --target es2020 解决了问题,没有把报错抛给您去解决。
- 核心记忆管理 (Core Memory) :
- 通过 manage_core_memory 工具,我把“图谱的节点包含建筑/楼层/柱/任务,任务和构件是[:作用于]关系”这些核心规则写进了长期记忆。这样在后续对话中,我不需要每次都去翻代码就能理解您的业务指令。
3.1 关键 Prompt 与操作过程示例
场景 :设计的前端图谱的 1跳/2跳检索功能失效。
- 输入 (Prompt) : “图谱的搜索、快速筛选、定位一跳二跳这些检索图谱的功能进行检测,确保可用”
- TRAE 操作流 :
-
检索 :查找前端处理图谱数据的逻辑,定位到 graph_view_utils.ts 。
-
分析 :发现原有的 filterGraphData 函数只做了单层过滤,没有处理深层关系(例如:选了楼层,没有把属于该楼层的柱子,以及作用于该柱子的任务一起查出来)。
-
重写逻辑 :将代码重写为基于 Set 的交集运算,加入了 2-hop 的遍历逻辑(楼层 → 构件 → 任务)。
-
修改 Cypher :同步修改 graph_workspace.tsx 中的图谱查询语句,增加 OPTIONAL MATCH (ctx)-[loc_rel:包含于|聚合]->(loc) 确保后端把楼层节点也一并返回给前端。
-
验证 :通过终端执行 npx tsc 确保前端类型安全。
-

3.2. 中间踩过的坑与解决方案
回顾开发过程,我解决过几个典型的“坑”:
- 坑一:大模型(LLM)生成 Cypher 语句时的“幻觉”
- 现象 :最初 DeepSeek 生成的查询语句会查出不存在的节点,或者试图使用 DELETE 语句修改图谱。
- 解决 :在 app.py 中实施了强力 Prompt Engineering。硬编码注入了业务 Schema(告诉 LLM 构件名称在 Name 字段,任务名称在 name 字段),并明确声明“禁止使用 CREATE/DELETE 等写操作”。
- 坑二:服务假死与依赖链路断裂
- 现象 :前端提示“后端不可用”,但 Flask 进程明明在跑。
- 解决 :通过阅读您的 HANDOVER.md 文档,明确了 Neo4j → Backend → Frontend 的严格启动顺序。通过抓取 Flask 报错日志 ( ConnectionRefusedError: localhost:7687 ),定位到底层是 Docker Neo4j 挂了,从而从根源解决,而不是反复重启 Flask。
- 坑三:前端多维过滤的逻辑冲突
- 现象 :当用户同时选择“特定楼层”和“特定任务类型”时,图谱节点全部消失。
- 解决 :发现原逻辑是简单的数组串行过滤(导致相互覆盖)。重构为“计算各自的合法节点 ID 集合(Set),最后取交集”的算法,完美解决了多条件叠加检索的问题。
虽然目前功能还在持续迭代,但从模型上传到生成可用甘特图的核心链路已经打通,实际处理了多个装配式厂房和综合楼的 IFC 文件。
4. 成果与感受
现在,我已经拥有了一个属于自己的 BIM 施工进度智能辅助工具。
它虽然还不是完美无缺的成熟产品,但它真实可用、可以持续打磨,更重要的是——它让我看到了一个人借助 Trae,也能做出显著提升工作效率的工具。
这极大增强了我的信心:工程管理人员完全有能力用 AI 工具武装自己,把重复繁琐的工作交给智能系统,把精力放在更重要的决策和现场管理上。
5. 总结与展望
这个项目证明了:即使不是计算机专业出身的工程管理人员,也能借助 Trae 做出对实际工作有帮助的智能化工具。
下一步,我计划继续完善多专业支持(机电、装修)、增强优化建议的实用性,并探索与常用项目管理软件的对接。
如果你也是一线工程管理人员,也在为进度编制头疼,欢迎一起交流、共同迭代。
希望这个工具能帮到更多像我一样的同行,让大家的工作更高效、更轻松一些!