场景
每天帮助我去自动检索网络的信息源。帮我生成符合我理解的日报系统。该系统也可以为我生成更加结构化的文章,方便我像听播客一样,听生成的文章。
成果展示

每天通过抓取生成日报。在生成的日报这里,会检索出更值得「深挖」线索,在该条信息旁边会有一个生成文章的入口。点击这个入口,用户就可以看到更多的针对该工具有更加深挖的思考文章。文章不满意的话也可以重新生成。
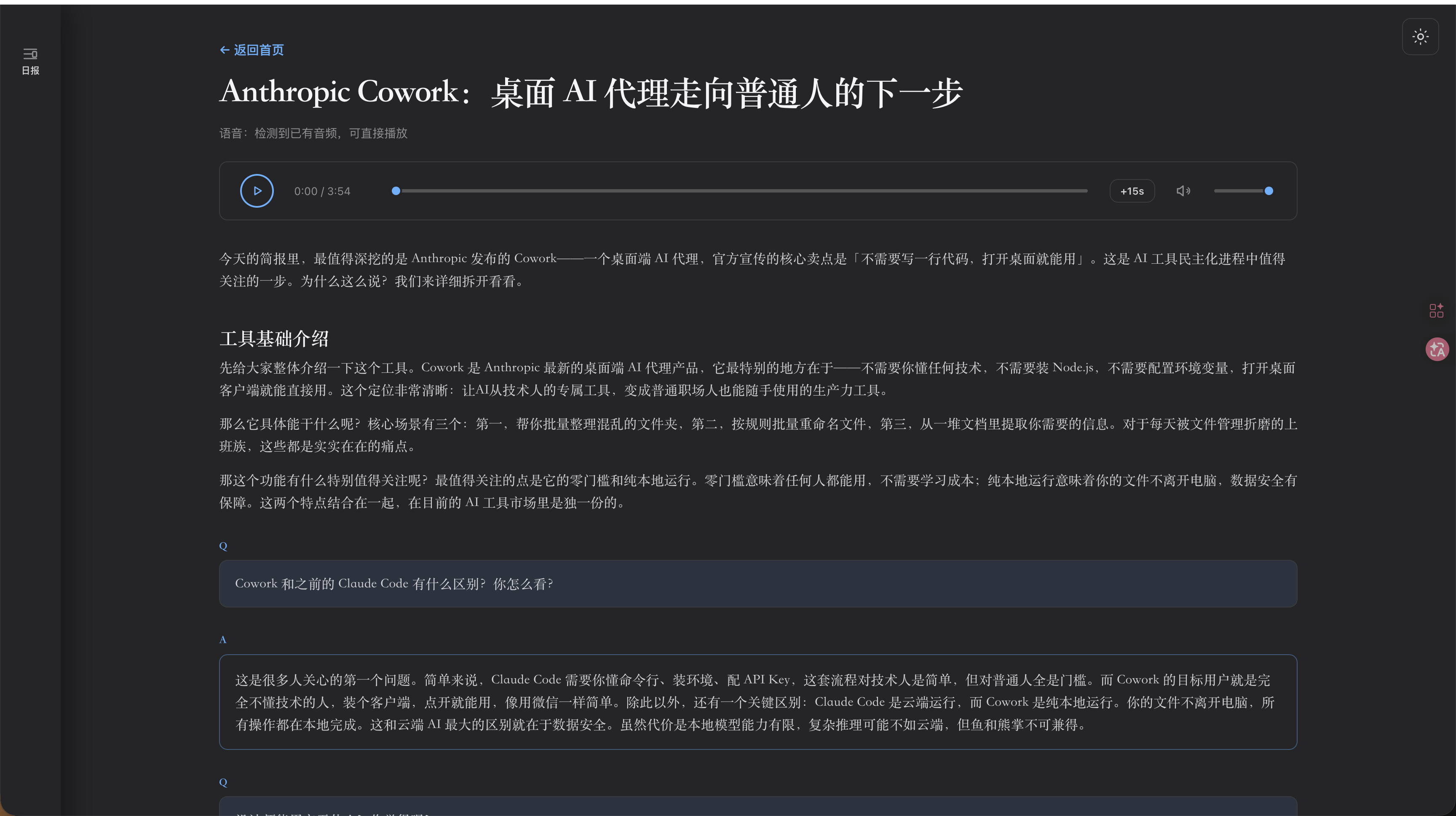
点开之后,上面展示一个博客按钮,下面是对这个工具的一些深度思考。全部内容都是由AI生成。AI通过自己的理解,并且我给他制作了一个表达方式的skill。帮助AI更好的表达观点。

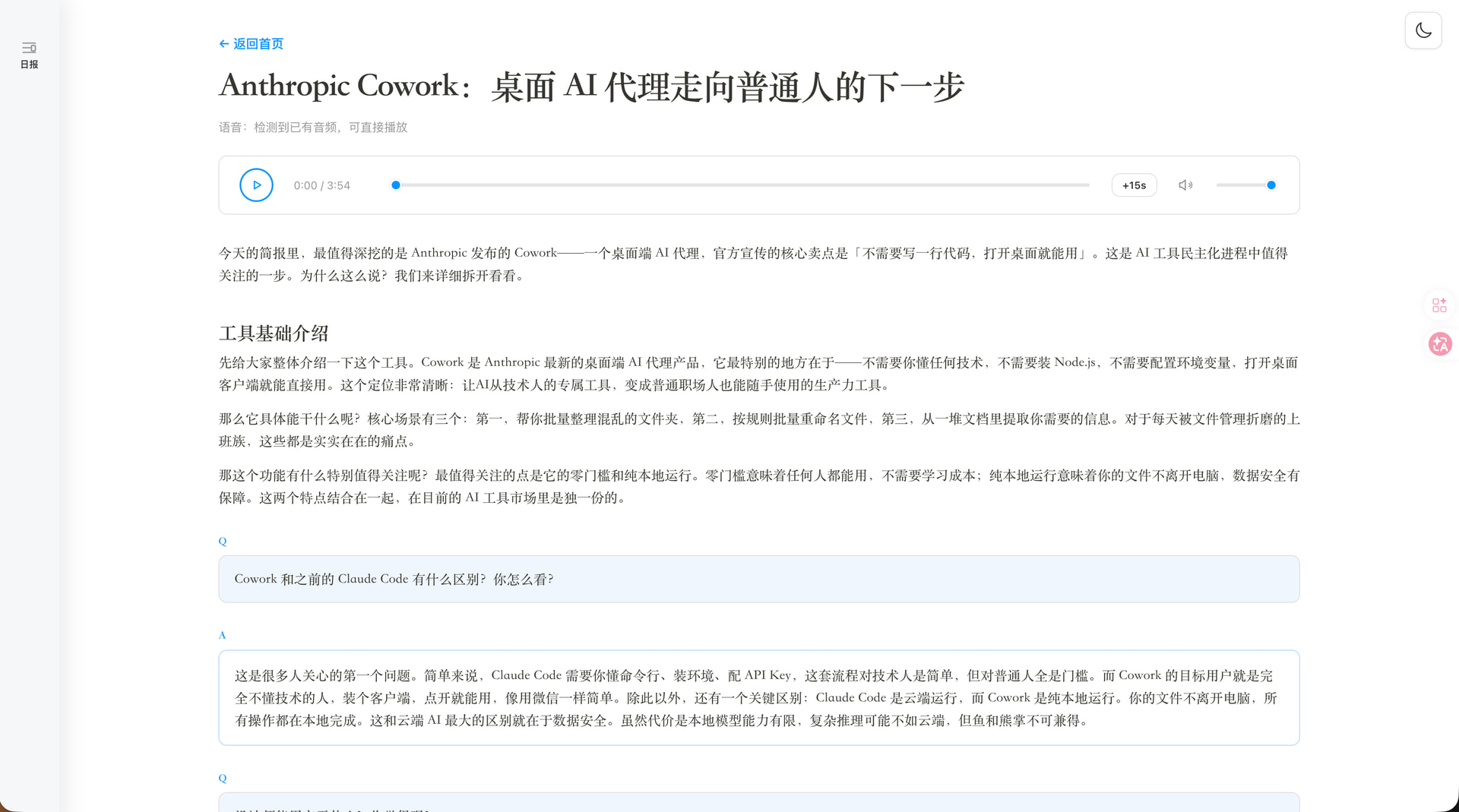
整个产品还做了暗夜模式切换。左侧的导航未来可以有更多的拓展。
效果总结
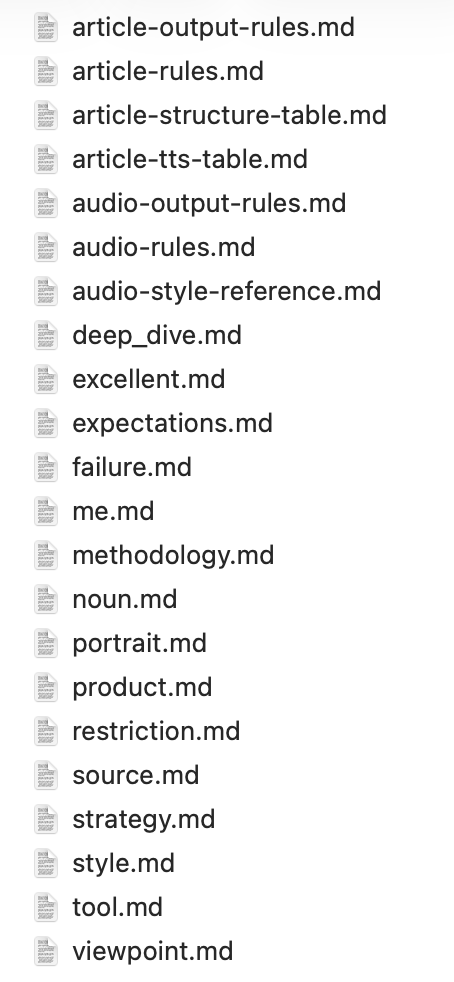
我自己存有一个 context 的文件夹,这个文件夹里面有很多我个人对产品和设计的理解。他可以复用到更多的产品相关的生成里面。
架构概览
Playwright 抓取 → 关键词预过滤 → LLM 评分 → LLM 分类 → LLM 生成简报 → 人工审核 → 发布
daily-briefing/
├── README.md
├── requirements.txt
├── .env.example
├── .gitignore
├── run.sh # 一键执行脚本
│
├── config/ # 配置文件
│ ├── settings.py # 全局配置(API key、模型选择)
│ ├── sources.py # 信源清单
│ ├── keywords.py # 关键词白名单
│ └── blacklist.py # 关键词黑名单
│
├── context/ # 你的知识体系(prompt 注入用)
│ ├── strategy.md
│ ├── style.md
│ ├── portrait.md
│ ├── me.md
│ ├── restriction.md
│ ├── methodology.md
│ ├── excellent.md
│ ├── tool.md
│ ├── noun.md
│ ├── failure.md
│ ├── viewpoint.md
│ └── expectations.md
│
├── scraper/ # 数据采集
│ ├── init.py
│ ├── base.py # 抓取基类
│ ├── autocli.py # Autocli 抓取
│ ├── rss.py # RSS 通用抓取
│ └── manual.py # 手动输入合并
│
├── pipeline/ # LLM 处理流水线
│ ├── init.py
│ ├── main.py # 主流程
│ ├── prefilter.py # 关键词预过滤
│ ├── prompts/ # Prompt 模板(核心资产)
│ │ ├── init.py
│ │ ├── scoring.py # Step 1: 评分
│ │ ├── processing.py # Step 2: 分类 + 实体提取
│ │ └── generation.py # Step 3: 生成简报
│ ├── llm.py # LLM 调用封装
│ └── notify.py # 完成通知
│
├── tools/ # 工具脚本
│ ├── init.py
│ └── add.py # 手动添加条目
│
├── data/ # 数据目录(gitignore)
│ ├── raw/ # 每日原始抓取
│ ├── manual/ # 手动输入
│ ├── intermediate/ # 中间处理结果
│ └── output/ # 最终简报
│
├── logs/ # 运行日志
│
└── .github/workflows/
└── daily-briefing.yml # GitHub Actions 定时任务=
GitHub Actions: UTC 21:00 (北京时间 05:00) 自动执行
抓取 → Playwright + RSS,输出统一 JSON
预过滤 → 关键词黑白名单,减少 LLM 调用量
评分 → 6维加权评分(1-5分),漏斗分层
分类 → 打标 + 实体提取 + 影响判断
生成 → 按模板生成可发布的简报 Markdown
通知 → 推送到飞书/企业微信,等待人工审核
该评分体系也帮助我从海量的信息中找到我最需要的内容。
产品链接:https://www.qearldesign.top/
目前还有服务器不太稳定的问题,定时抓取还有一些问题~在努力修改中