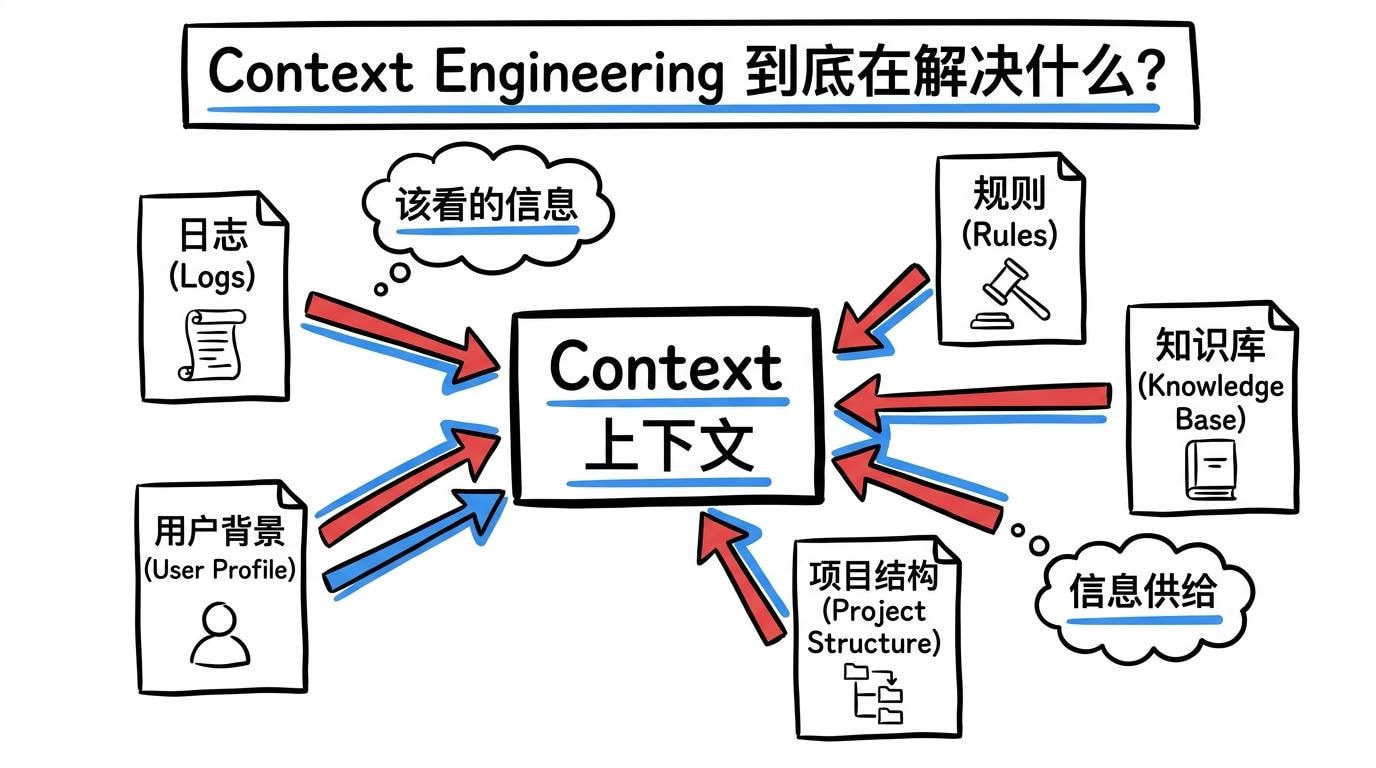
- Context 解决的不是表达,而是信息是否正确、是否及时、是否可用。
- 成熟的上下文工程离不开三件事:召回(找对)—压缩(变短)—组装(摆对)。
- 在多步骤 Agent 场景里,上下文设计差会导致偏差累积,最终变成系统性不稳定。
如果说 Prompt Engineering 解决的是“怎么把话说清楚”,那 Context Engineering 解决的,就是另一个更现实的问题:
模型到底有没有看到它应该看到的信息?
上下文的重要性,通常在任务失败时最明显:模型话说得很完整,但依据的事实可能过期/缺失/抓错重点,于是“看起来对、实际不可用”。在复杂任务和多轮执行里,这种偏差会被迅速放大。
这时你会发现,一个任务做得好不好,关键不只是模型聪不聪明,而是它在当前这一轮思考时,手里拿着的“信息包”质量高不高。
这就是 Context Engineering 的本质。
它不是简单地“多给一点背景资料”,也不是把相关文档一股脑粘进上下文窗口。它更像是一种信息供给系统,核心目标是:
在正确的时间,把正确的信息,用正确的顺序和形式,交给模型。
这里面至少包含三个层面的挑战。
第一,信息不在一个地方。
现实任务中的信息是分散的。代码在仓库里,报错在日志里,用户信息在工单系统里,规则在知识库里,历史记录在聊天线程里,限制条件可能在项目 README、注释或者某个会议纪要里。模型并不会自动知道去哪里找,也不会天然理解哪些信息最关键。
第二,信息不一定都该给。
很多人对上下文的第一反应是“那我多塞一点”。但问题是,上下文窗口不是无限的,模型的注意力也不是无限的。信息太少,它会瞎猜;信息太多,它会失焦。你越想让它看全,它反而越有可能抓不住重点。
第三,信息需要被组织。
即使给到了正确材料,顺序、格式和优先级也会显著影响模型的使用效果。真正重要的规则如果被埋在长段历史记录后面,模型可能根本注意不到;成功标准如果和背景说明混在一起,执行时就容易偏。
所以,Context Engineering 不是“信息搬运”,而是“信息设计”。
一套成熟的上下文工程,通常绕不开三个动作:召回、压缩、组装。
一、召回:先把对的东西找出来
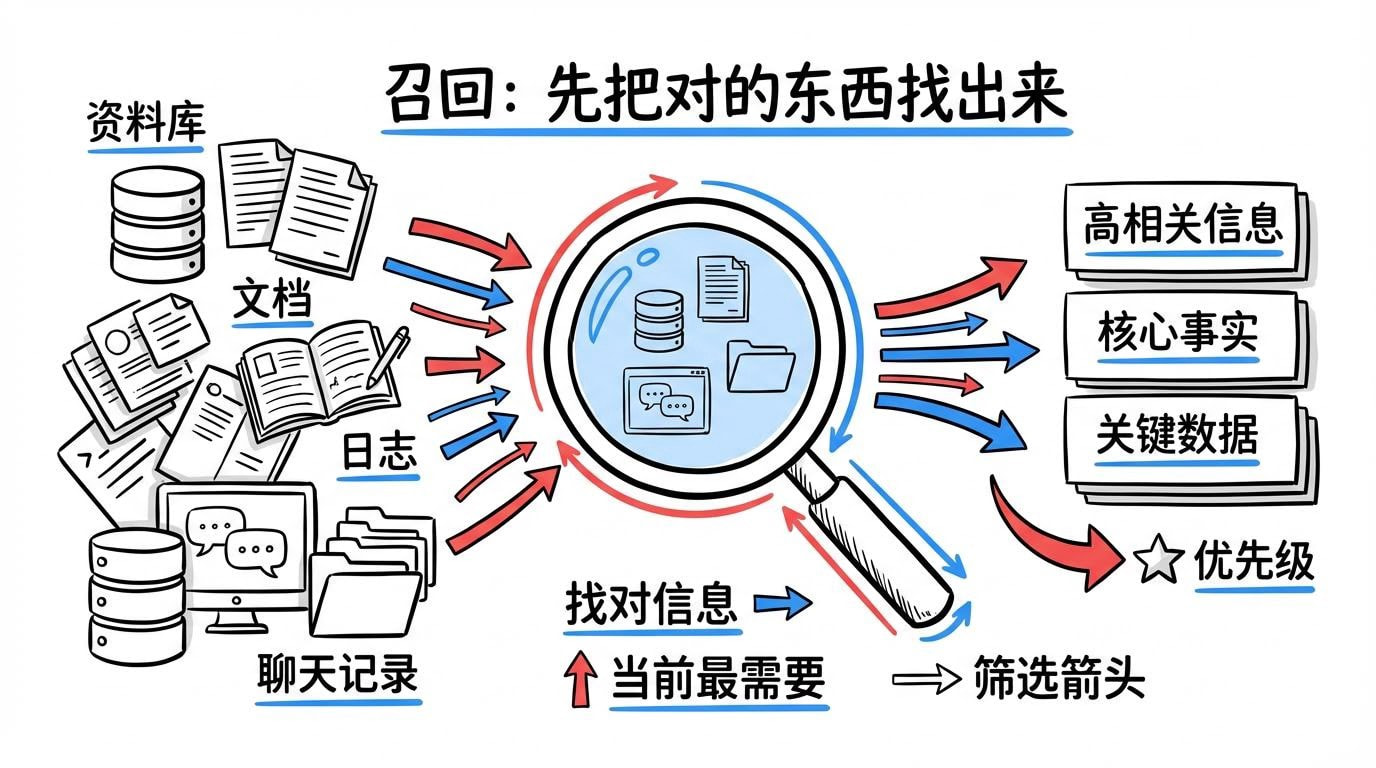
召回解决的是:从大量资料里找出“当前决策最需要”的那部分。它看起来像搜索,但更强调优先级——不是“相关就都要”,而是“能立刻支撑下一步判断/行动的才要”。
好的召回系统会围绕任务目标来判断:这一轮决策最需要什么信息。它关注的是“对现在有用”,而不是“理论上都可能有关”。
本节要点:
- 召回的目标是“对当前决策有用”,不是“相关就都要”。
- 召回结果要能直接支撑下一步行动或判断。
二、压缩:把长材料变成可用材料
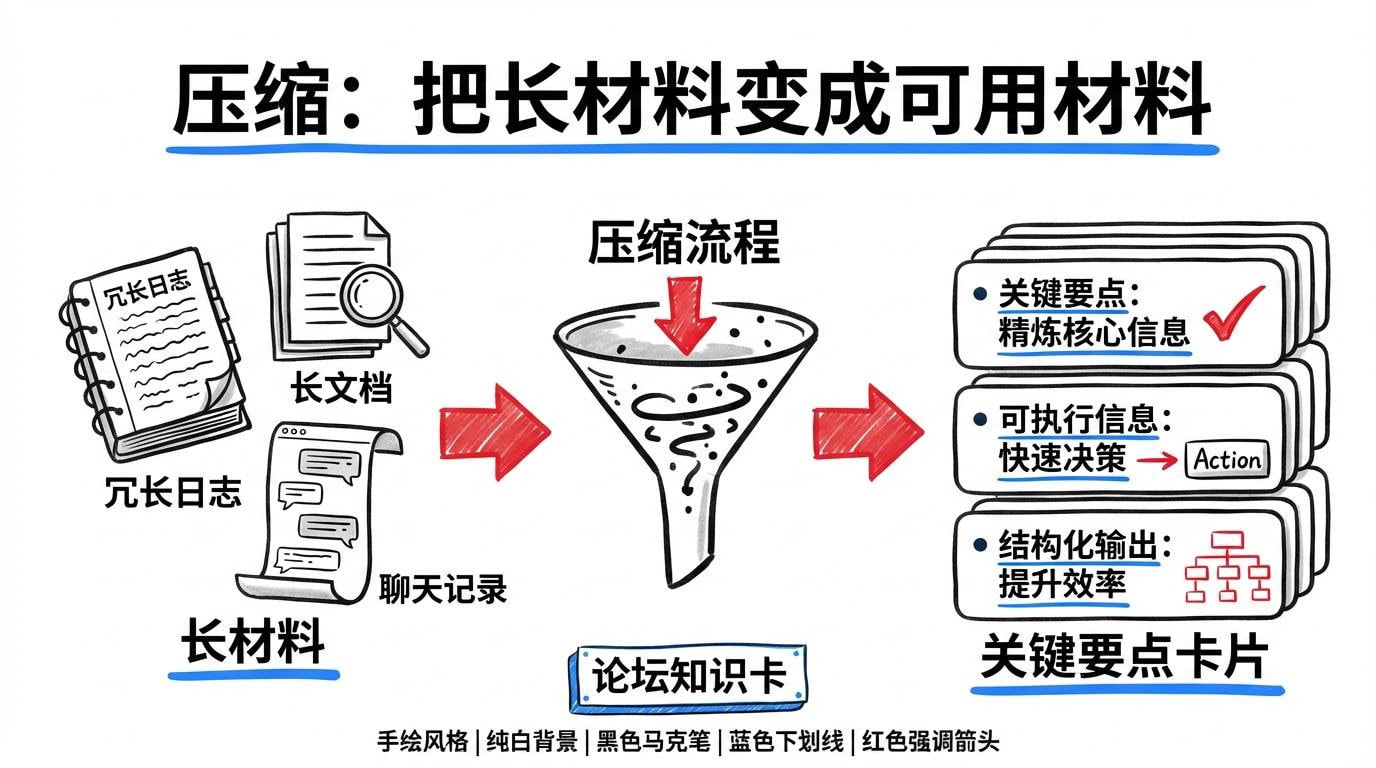
原始资料通常太长(日志/文档/聊天记录/代码)。压缩的目标不是“变短”,而是提炼可执行信息:保留影响判断的要点(时间点、范围、关键堆栈、变更、约束与验收),去掉噪音。
在很多实际场景里,压缩能力直接决定了模型是否能“聚焦”。因为模型不是看得越多越好,而是看得越对越好。
本节要点:
- 压缩不是“缩水”,而是“保留影响判断的要点”。
- 原始日志/文档/聊天记录往往要先提炼成可执行信息。
三、组装:让模型按正确顺序看到信息
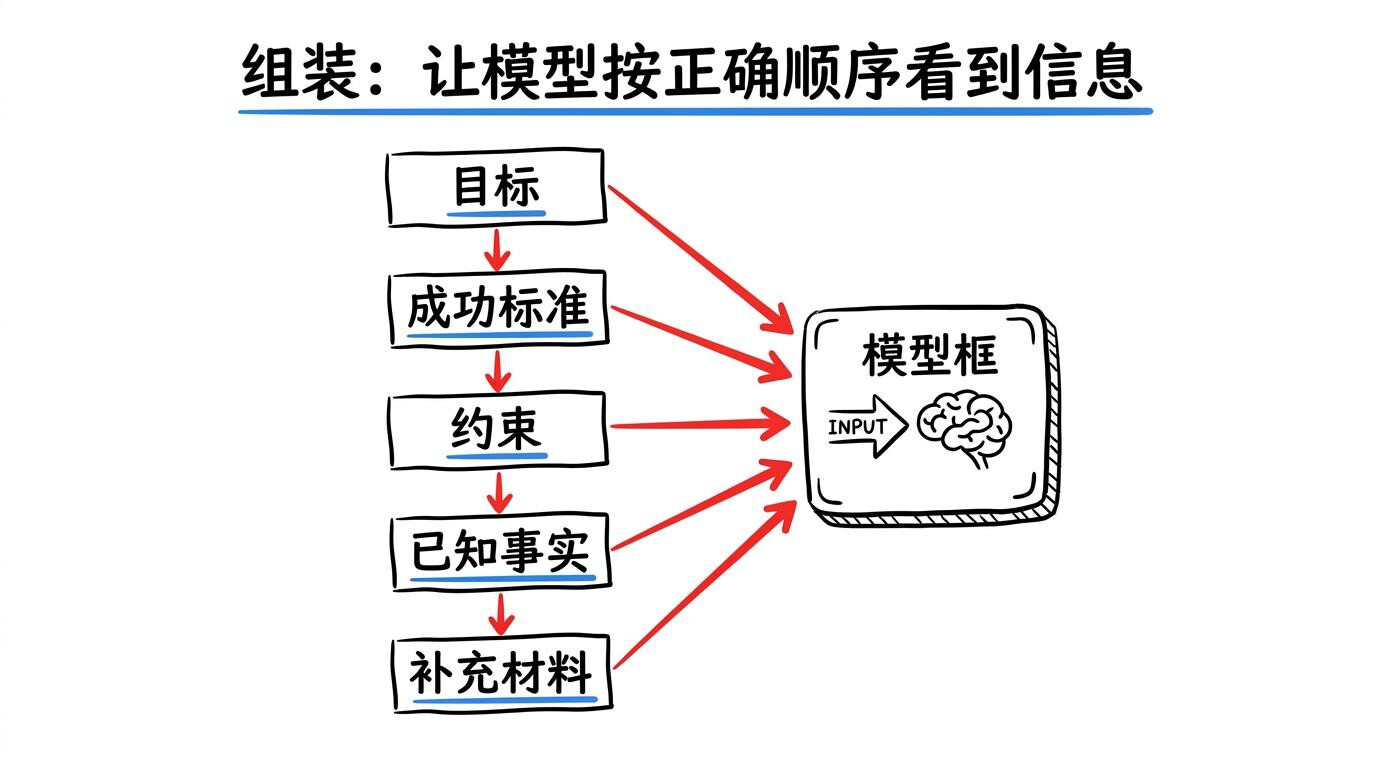
组装解决的是“摆放顺序与分层”。同一批信息,如果目标、约束、验收标准被埋在背景材料里,模型就容易执行跑偏。建议固定分层:
- 目标
- 成功标准(验收)
- 约束(不能做什么)
- 已知事实(当前证据)
- 补充材料(历史/参考)
这也是为什么成熟的上下文管理,不只是做资料拼接,而是在做一种“信息分层”。它希望模型先抓到最关键的骨架,再去参考细节,而不是在大量噪音中自己摸索重点。
本节要点:
- 同样的信息,顺序与结构会改变模型的执行依据。
- “目标/成功标准/约束/事实/补充材料”需要分层呈现。
四、为什么 Context 设计不好,Agent 就会越来越不稳定

在单轮问答里,上下文问题可能只是让回答质量波动一点;但在多步骤任务里,它会放大成系统性不稳定。
因为 Agent 并不是只看一次输入然后给一次输出。它会持续读信息、做决策、执行动作、接收结果、再进入下一轮判断。只要上下文设计稍微有偏,后面每一步都可能在错误基础上继续累积偏差。
最常见的几种问题是:
- 给少了,模型开始脑补
- 给多了,模型抓不住重点
- 给晚了,模型前面已经做错决定
- 给乱了,模型分不清主次
- 给旧了,模型基于过时事实继续行动
所以,Context Engineering 的价值不只是“让回答更准确”,而是“让任务在多轮推进中不至于越来越偏”。
这也是 Agent 系统和普通聊天产品最不一样的地方之一。聊天产品可以容忍一定程度的偏差,因为用户随时可以重新提问;但 Agent 一旦带着错误上下文继续执行,后面每一步都可能浪费时间、资源,甚至引发连锁错误。
五、上下文工程最容易踩的几个误区
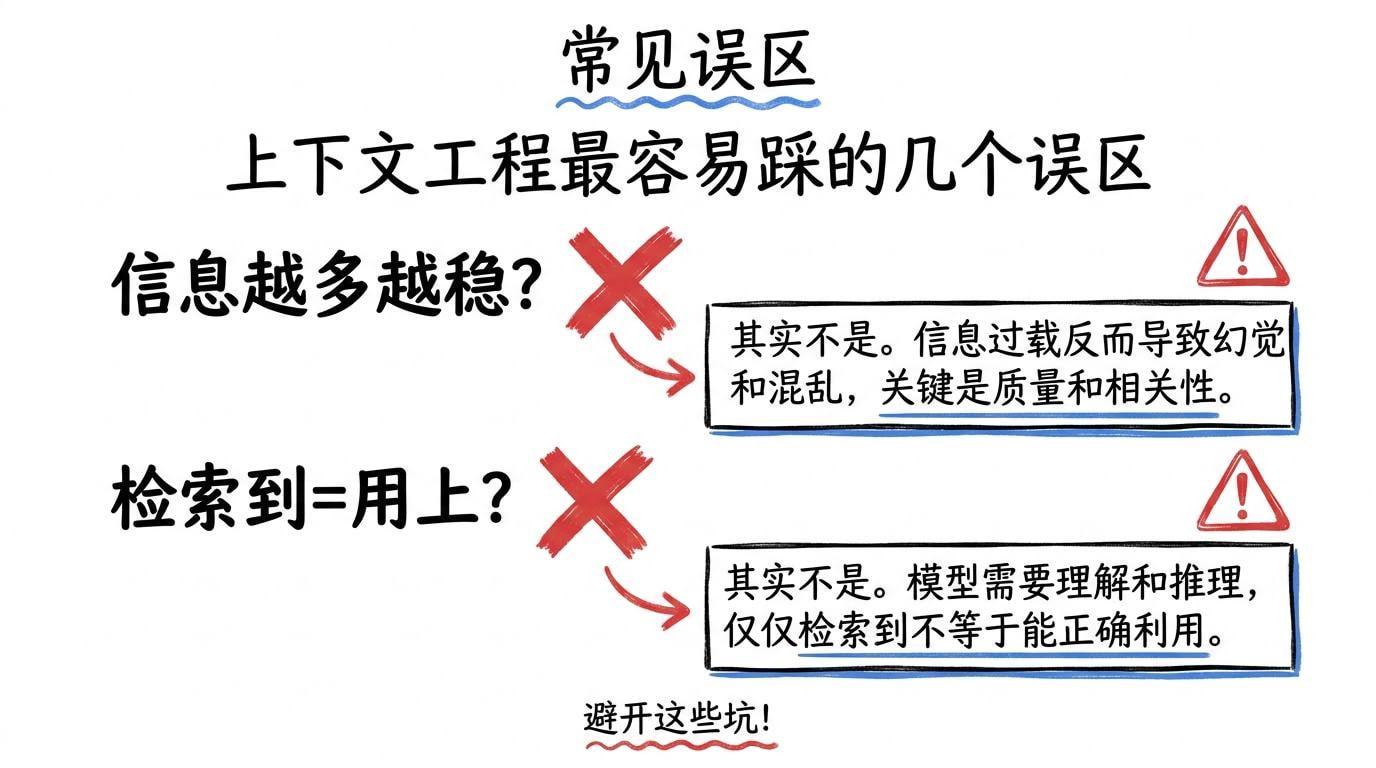
很多团队开始重视上下文后,会踩两个常见坑:
- 信息越多越稳(实际会稀释重点)
- 检索到=用上(实际还需要压缩与组装)
此外还要记住:Context 解决“看什么”,但不负责“怎么把过程跑稳”,这会把我们带到下一篇的 Harness Engineering。
这也意味着,Context Engineering 虽然非常关键,但它依然只是中间层,而不是终点。
六、从 Prompt 到 Context,是一次认知升级
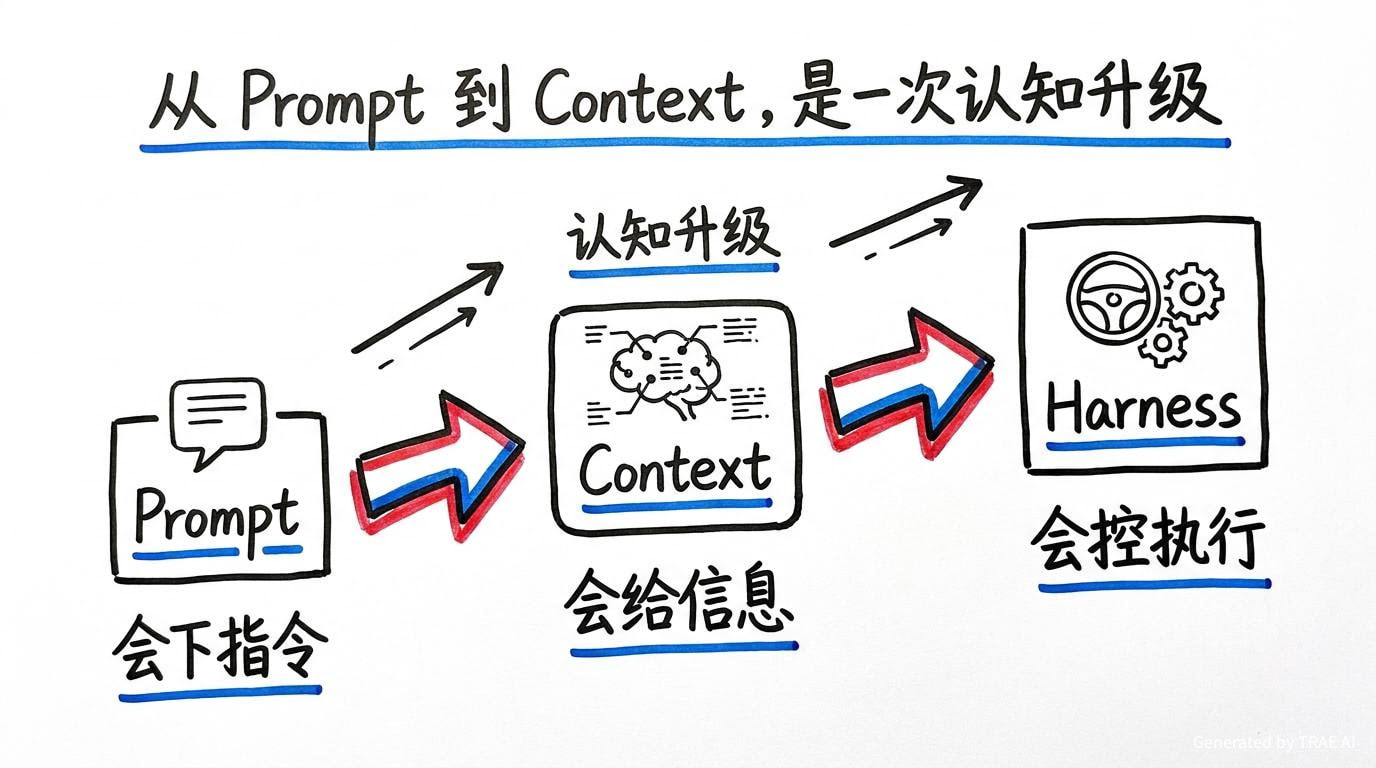
当大家从 Prompt 转向 Context,本质上是在承认一件事:
复杂任务的失败,很多时候不是因为你指令写得不够漂亮,而是因为系统没有在正确时刻,把足够好的信息交给模型。
这是一种非常重要的进步。因为它把大家的注意力,从“语言技巧”转向了“信息供给能力”。
也正因为如此,很多 Agent 产品在这一阶段会出现明显提升:不换模型,只要把检索、摘要、裁剪与优先级做好,成功率就能上一个台阶。
不过,事情走到这里还没有结束。
因为即使模型拿到了正确的信息,它也不一定能在真实环境中一直稳定执行下去。它可能仍然会漏步骤、忘检查、调用错工具、在失败后重复走弯路,甚至在长任务中慢慢失控。
于是我们就来到下一层问题:
当模型已经听懂了,也看对了,谁来保证它真的能持续、可靠、可控地把事情做完?
这正是 Harness Engineering 出场的原因。