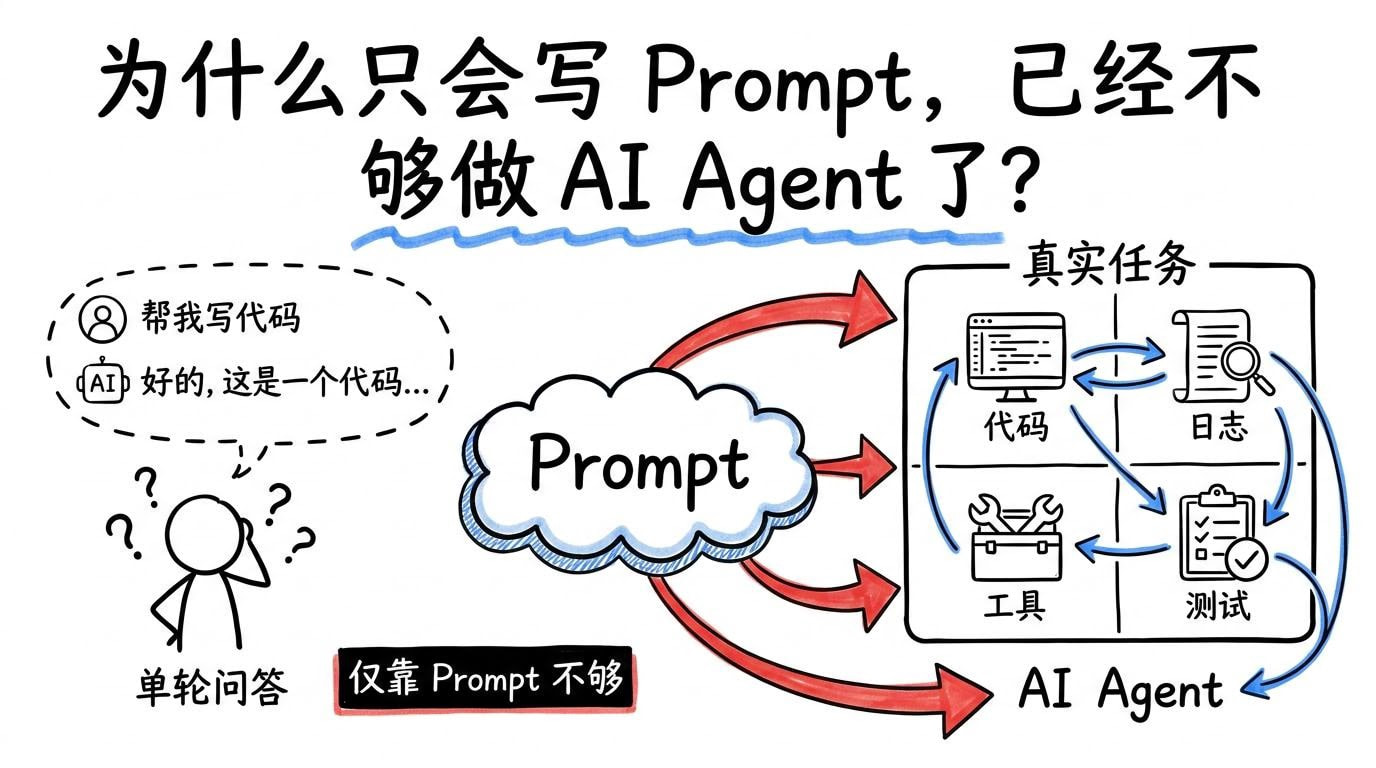
- Prompt 依然重要:它决定模型起步方向、格式边界与表达清晰度。
- 但 Prompt 不是系统能力:复杂任务的关键变量变成了“信息是否齐全、过程是否可控、结果是否验收”。
- Agent 时代的失败,常常不是“不会说”,而是“没看到关键事实 + 没有执行闭环”。这也是
Context Engineering、Harness Engineering走上台前的原因。
一、Prompt Engineering 为什么在早期非常有效
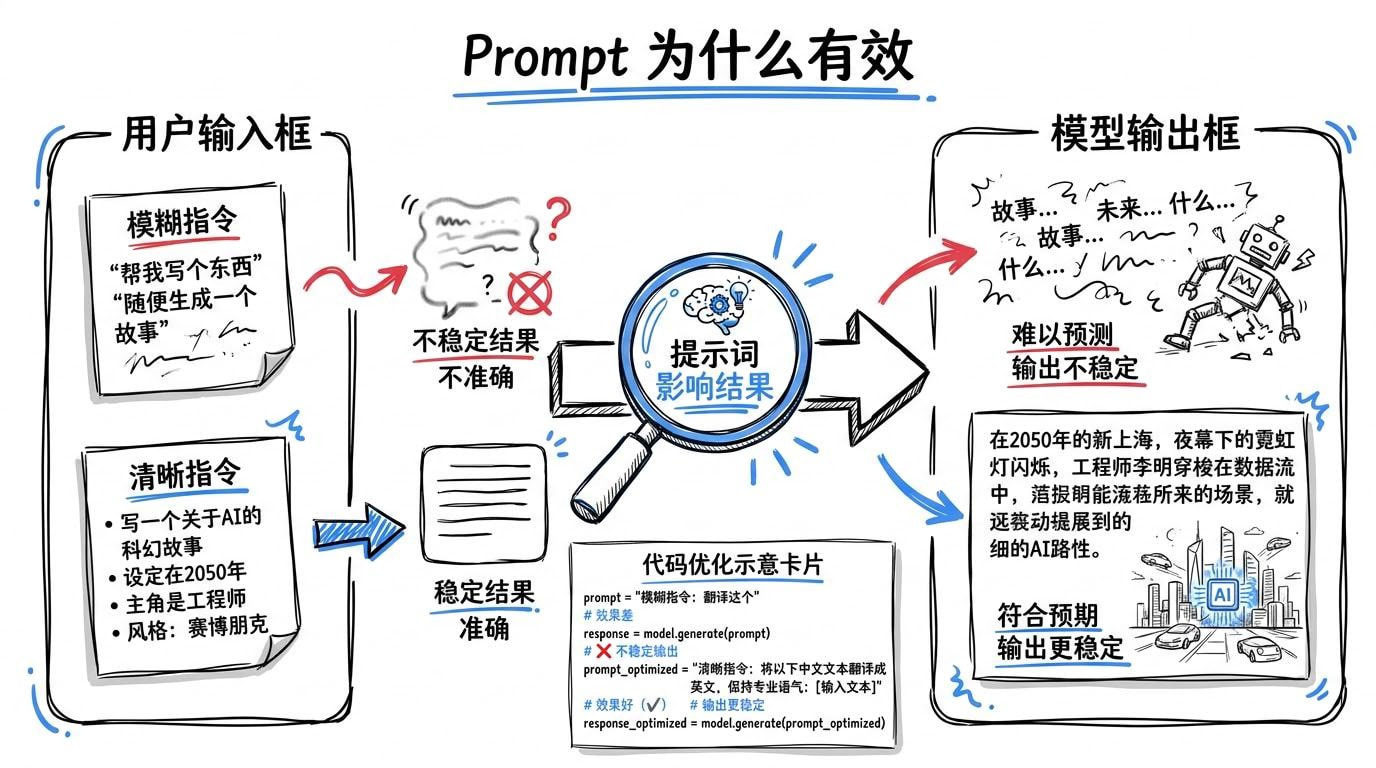
过去两年,很多人第一次真正“用好”大模型,靠的就是:把提示词写清楚。因为模型对输入极其敏感,表达是否具体、边界是否明确,会直接影响输出。
一个最常见的例子是改代码:
- 你说“帮我优化一下代码”,它可能会大改结构。
- 你说“只优化性能,不改结构,变量名别动,先分析再修改”,结果通常就会稳定得多。
于是很多人自然形成了一个判断:只要提示词足够好,模型就会足够好用。
这个判断在“单轮问答式任务”里大体成立:写文案、润色邮件、解释概念、翻译短文……Prompt 往往就是最强杠杆。
二、任务形态升级:从“问答式任务”走向“执行式任务”
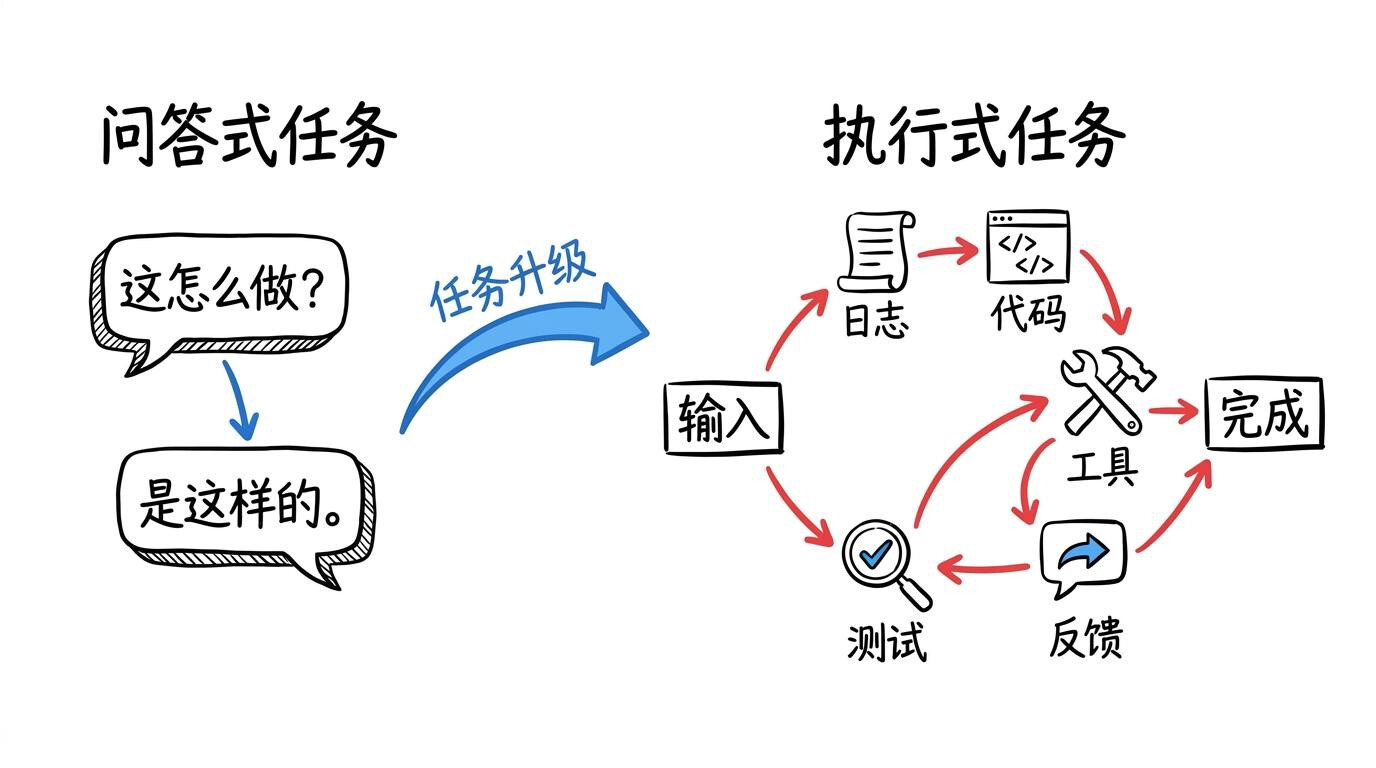
问题在于,AI 的主战场正在从“回答”转向“完成任务”。当目标变成修 Bug、做分析、处理投诉、走完一条流程时,决定成败的变量不再只有提示词。
2.1 两类任务的核心差异
(1)问答式任务通常有这些特点:
- 输入通常比较短
- 目标比较单一
- 输出往往一次性完成
- 模型只需要“回答”
**(2)执行式任务(Agent 任务)**通常有这些特点:
- 输入分散在多个来源里
- 目标需要分步骤推进
- 中间过程会产生新信息
- 模型不仅要回答,还要决策、调用工具、接收反馈、继续修正
2.2 为什么复杂任务不是“一句话”能完成的
比如你让 AI 修 Bug,它除了指令,还需要:
- 报错日志
- 相关代码与调用链
- 依赖版本与项目结构
- 修改边界与验收标准(例如必须通过哪些测试)
再比如处理用户投诉,至少还需要:
- 客户背景与购买记录
- 规则、话术边界、历史沟通与目标(挽回/退款/升级)
这时真正决定质量的,已经不是开头那句指令写得是否优雅,而是:模型手里到底有没有足够的信息与约束。
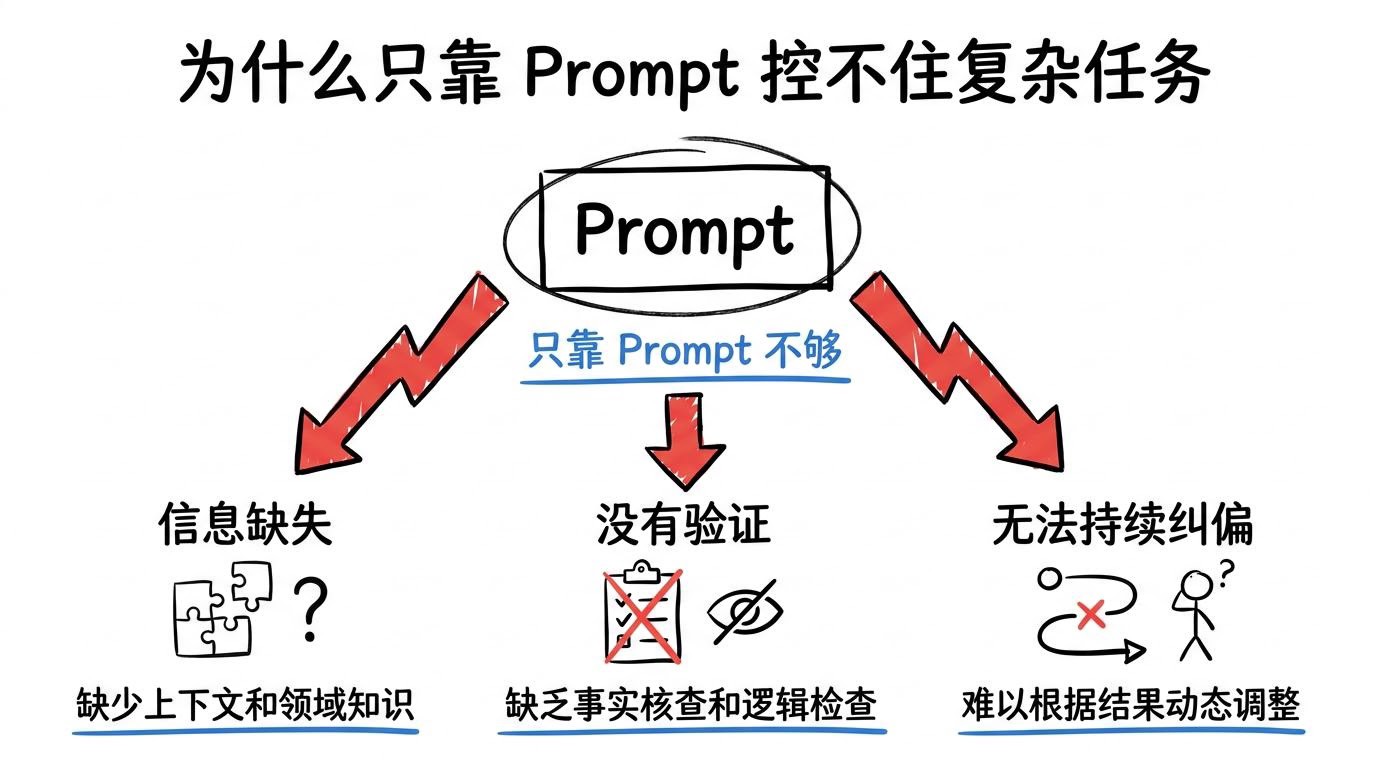
三、为什么只靠 Prompt 控不住:三个根本问题
很多团队做 Agent 时,一开始最容易陷入的误区,就是把问题过度归因于提示词:
- 失败了,觉得是提示词不够细
- 跑偏了,觉得是提示词不够严
- 结果差,觉得是提示词还没调好
于是不断追加约束、补充规则、增加格式要求,希望用更长的提示词把系统行为“锁死”。短期有效,长期往往变得冗长且脆弱。
更关键的是,提示词本身解决不了下面三类根本问题:
3.1 Prompt 不能凭空补足“模型没看到的信息”
没给关键日志/上下文,再“严谨分析”也只能基于残缺信息推断。
3.2 Prompt 不能替代“真实环境里的执行验证”
要求“先跑测试”不等于真的跑了测试;没有外部执行与反馈,可靠性无从保证。
3.3 Prompt 不能在长链路任务里持续纠偏
长链路任务里,模型可能漏步骤、忘约束、反复试错;这些不是开头一段提示词能长期兜住的。
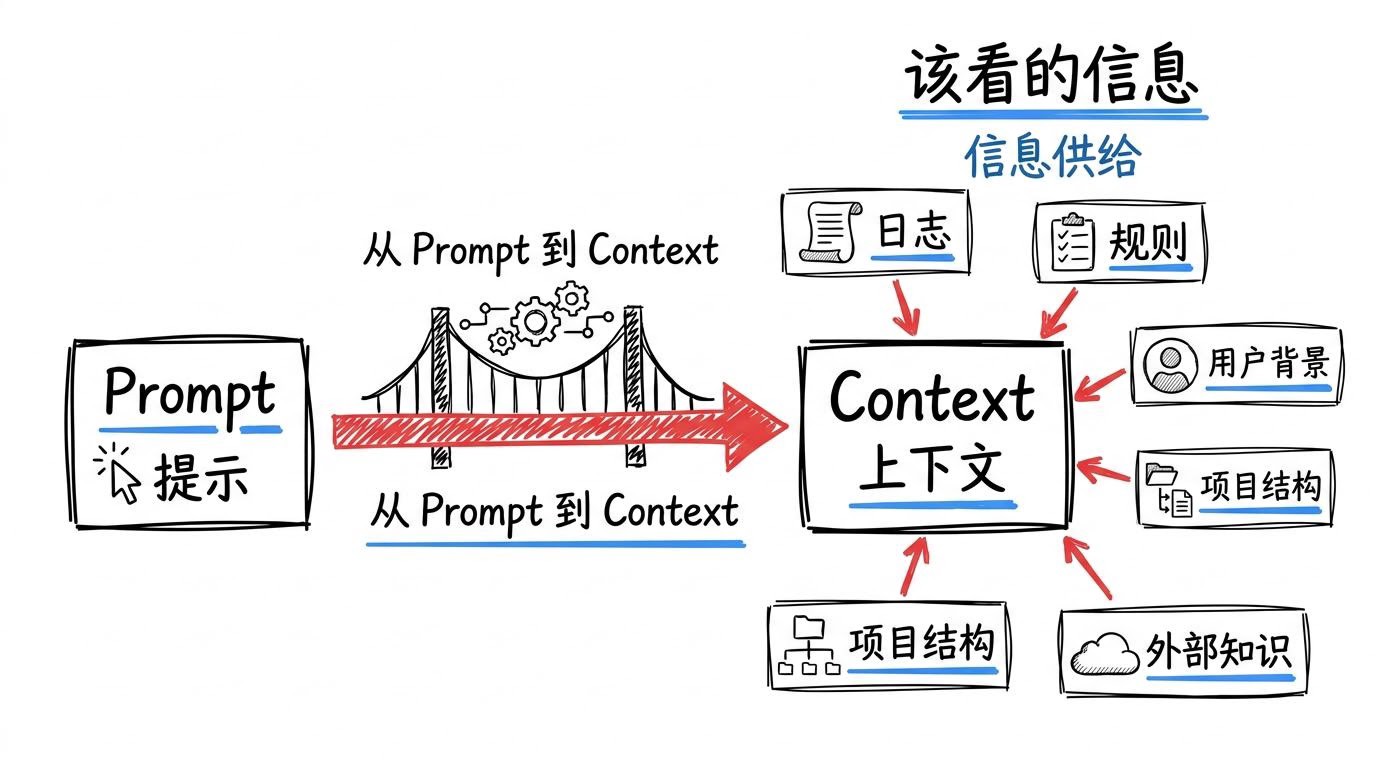
四、从 Prompt 走向 Context:下一层能力是什么
所以,Prompt Engineering 的真正价值,不是“包打天下”,而是帮助模型更好地进入任务。它更像启动阶段的方向盘,而不是整套交通系统。
这也是很多人开始重视 Context Engineering 的原因。
如果说 Prompt 解决的是“你有没有把要求说明白”,那么 Context 解决的是:
模型在当前这一刻,到底有没有看到对完成任务真正重要的信息?
现实中的失败,很多时候不是模型不会想,而是它在错误/缺失的信息基础上想:过期事实、缺失约束、噪音太多……最后自然不稳定。
五、小结:Prompt 没失效,但它不再足够
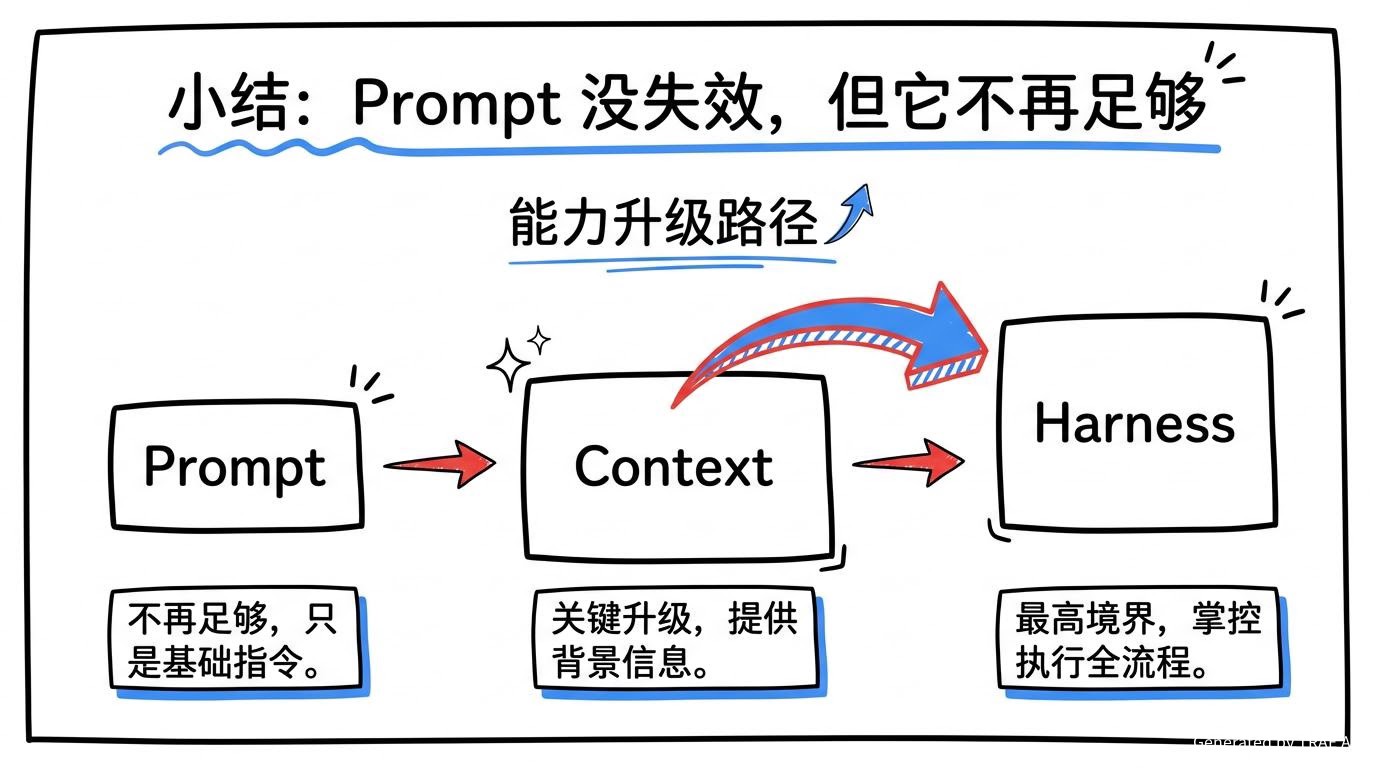
能力升级路径可以简单理解为:
- 会下指令(Prompt)
- 会给信息(Context)
- 会控执行(Harness)
所以,比“如何写出更强的 Prompt”更值得追问的问题是:
当任务不是一次性回答,而是一条需要持续推进的执行链路时,模型究竟该在什么时候看到哪些信息?