1.摘要:
用 TRAE SOLO 从零搭建了一套本地知识剪藏与智能整理系统:通过浏览器 Web Clipper 一键剪藏网页,后端自动调用大模型对文章进行分类和摘要,前端以思源笔记风格的桌面应用呈现笔记树、文章卡片和 Markdown 原文阅读。实现了"剪藏 → AI 分类摘要 → 本地归档管理"的完整闭环,让碎片化信息收集变成结构化知识沉淀。
2. 背景
我是一名程序员,日常需要大量阅读技术文章、行业资讯和学术论文。过去的工作流是:看到好文章 → 手动复制到笔记软件 → 自己打标签 → 事后写摘要,整个过程耗时且容易拖延,导致收藏夹越积越厚却几乎不会回顾。我希望有一个工具能让我一键剪藏,自动完成分类和摘要,所有数据保存在本地,不依赖任何云服务。
过程实践
任务拆解
整个系统拆分为三个核心模块:
1. 后端服务:FastAPI 实现,为了对接 web-clipper , 这个项目兼容思源笔记 API,可以使用网页插件 web-cliiper 一键剪藏到本地
2. 前端桌面应用:Electron + React + Tailwind CSS,笔记本侧边栏 + 文章卡片列表 + Markdown 原文阅读
3. 浏览器剪藏插件:基于开源 Web Clipper 定制 SiYuan Client,一键剪藏网页为 Markdown 并上传图片
用了SOLO哪些能力
- 网页阅读: 我先给出 web-clipper 的 gihub 地址给 solo, 让solo 阅读代码, 帮我适配了 web-clipper 剪藏的接口,
- 自动的架构规划: 在使用 solo 的过程中我没有告诉 solo 哪个地方需要存放什么类型的代码, 我只是告诉他后端使用 uv, 给了一个 src 文件夹, 和 front 文件夹, 他就会自己在里面创建项目级别的架构, solo 默认使用了比较好的技术栈 fastapi 很让我惊喜
- 前端开发: 我告诉 trae 使用 react+election, trae 通过理解它自己生成的后端接口自动的完成了对于功能的适配(笔记本侧边栏、文章列表、文章详情、Markdown 渲染器、队列状态面板),Tailwind CSS 样式一气呵成
- 集成调试: 最终生成完之后,运行还是会有一些报错, 我直接告诉 trae报错日志, 它自动修改好了
关键Prompt/操作过程
- 首先我得先规划好项目结构, 比如 src, front 告诉 solo 哪个地方的代码是存在哪里
- 在 src 的路径下我又建立了一个 feature 模板, 每个文件夹下有 service, router,schema, 如果让 trae 按照这个模板开发,代码是不会不可控的, 把每个功能点都拆分出来
- 对于每一步操作我都会告诉他在哪个路径实现, 详细的需求是什么,需要使用哪些技术栈
- 对于前端我 clone 了一个 github 的类似的项目的 web 代码, 让他参考实现, (但是效果不太好…


中间踩到的坑
我发现首先就得告诉 solo 使用什么 python, 比如我是用的 uv, 他总是调用我系统默认的 python
成果展示
仓库地址
https://gitee.com/goo-goo-gooQWQ/traechallenge.git
图片展示

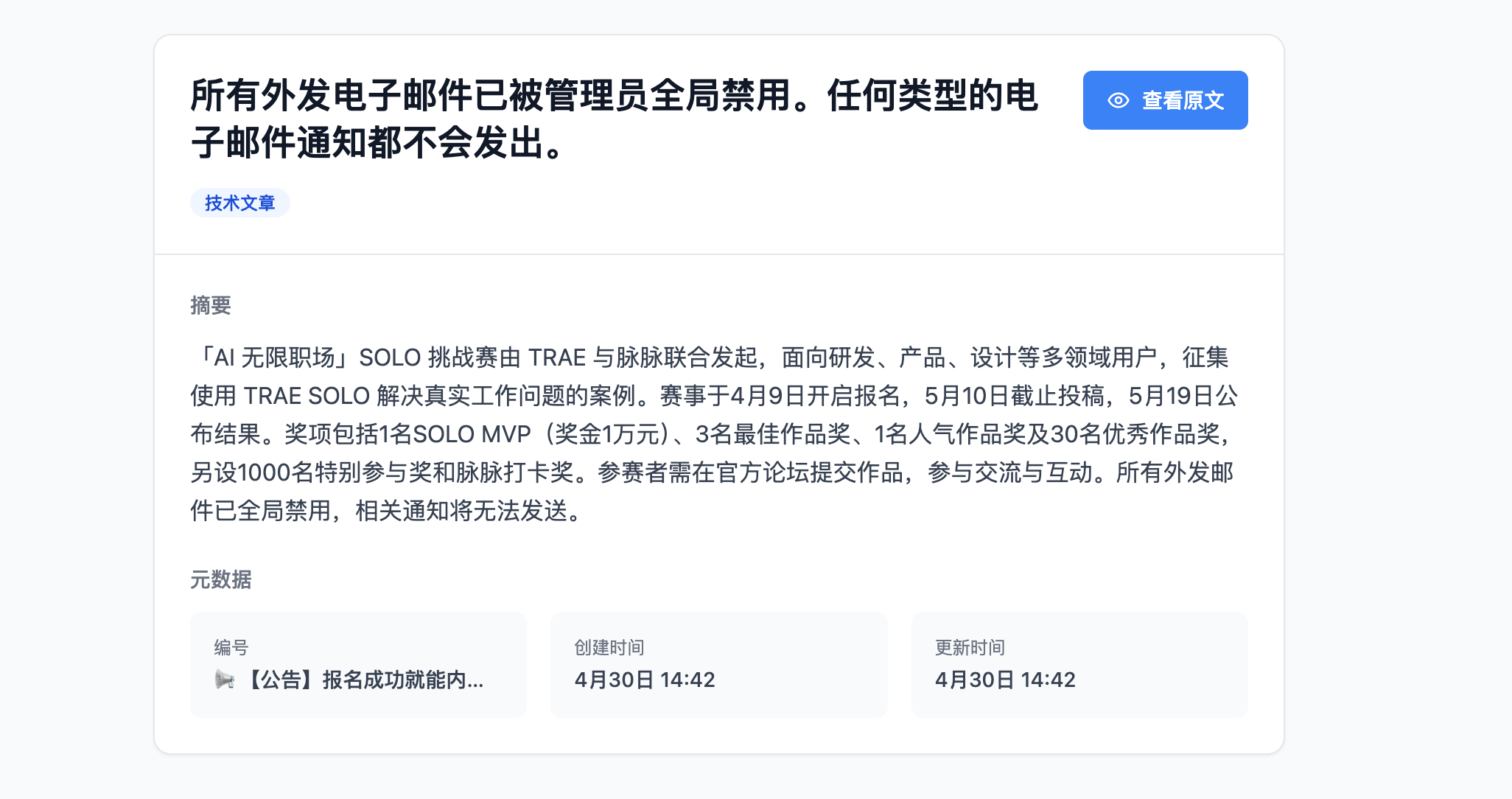
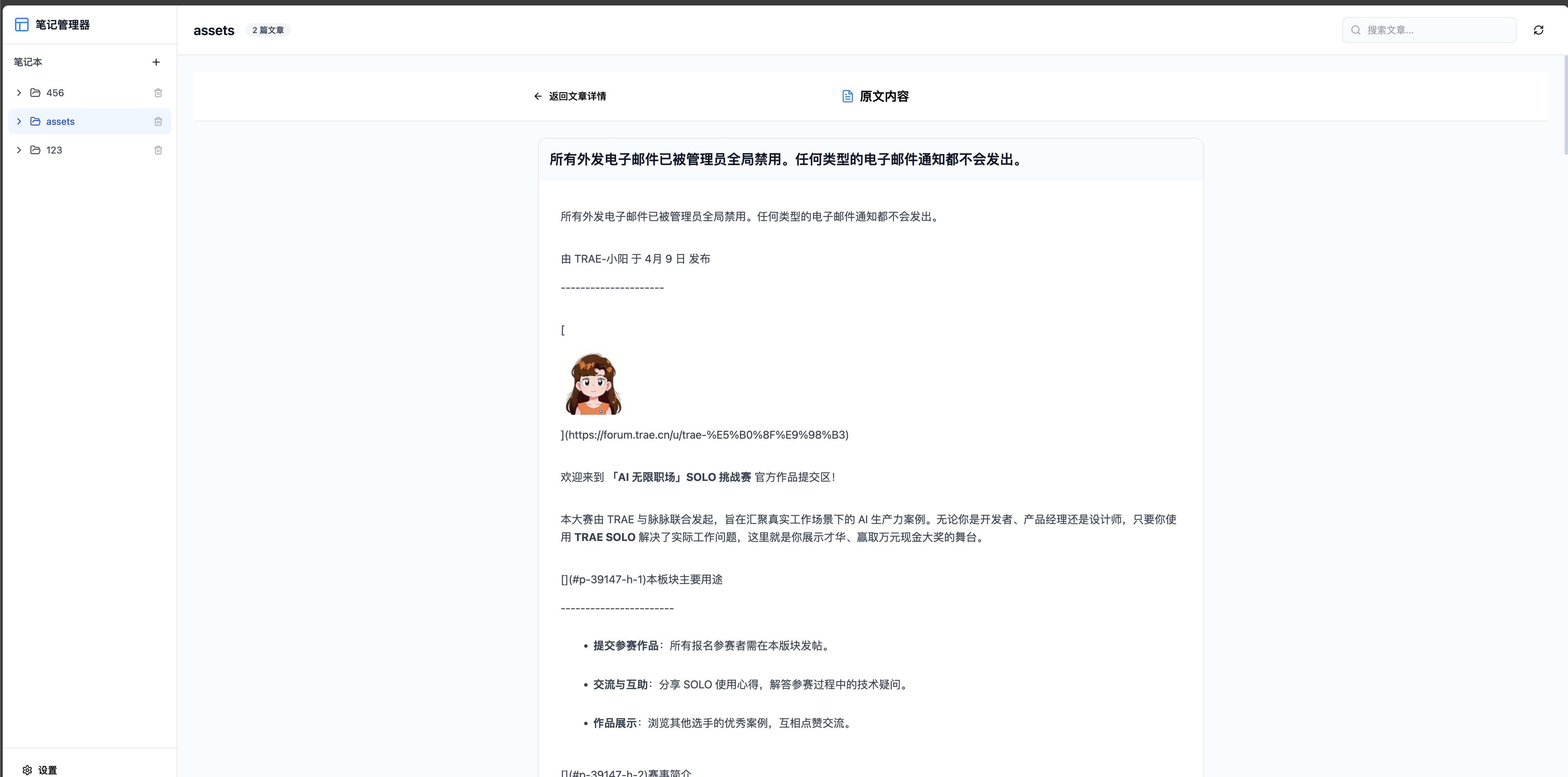
效果与总结
提效效果
剪藏效率:从手动复制粘贴 3-5 分钟/篇 → 一键剪藏 5 秒/篇
分类摘要:从手动打标签写摘要 5-10 分钟/篇 → AI 自动完成 10-20 秒/篇
整体效率提升约 20-30 倍,且分类一致性和摘要质量更稳定
SOLO 在流程中的作用
SOLO 帮我完成了 80% 以上的代码编写,从 API 设计到前端组件到集成调试
最有价值的是让 SOLO 理解"兼容思源笔记 API"这个需求后,自动生成了完整的接口规范和实现,省去了查阅思源 API 文档的时间 前端 UI 组件(侧边栏、卡片列表、详情页、Markdown 渲染器)全部由 SOLO 一次性生成,样式和交互逻辑都很完善