## 1. 摘要
我是一名存储系统测试工程师,维护着一套 600+ 文件的 Behave BDD 自动化项目。我发现市面上几乎所有 AI 测试工具都在解决「怎么写用例」,但测试工作中真正耗时的大头——**完全可执行的自动化用例+执行后预期结果验证**——几乎没人关注。我和 SOLO 一起,围绕这个瓶颈设计了完整的方案:先用 AST 分析项目建知识库给 AI 上下文,再用 RAG + Few-Shot 基于已有能力生成用例,最后用分层检查模型自动完成结果验证。原型验证下来,**单场景结果检查从 30-60 分钟降到 5 秒以内**。
## 2. 背景
我是一名存储系统测试工程师,负责存储相关业务的自动化测试,框架是 Python + Behave BDD。
日常工作中,一个测试场景跑完之后要做这些事:grep 日志查 ERROR、查进程还在不在、看端口有没有监听、检查业务数据是否一致。一个场景 30 到 60 分钟,跑 20 个场景一整天就进去了。根据我自己的工作记录估算,**写用例大概占 20% 的时间,执行和结果验证占了 80%**。
但观察了一圈 AI 测试工具,大家都在卷「用 AI 生成测试用例」,没人关注结果验证这块。**我判断这里才是真正的提效瓶颈。**
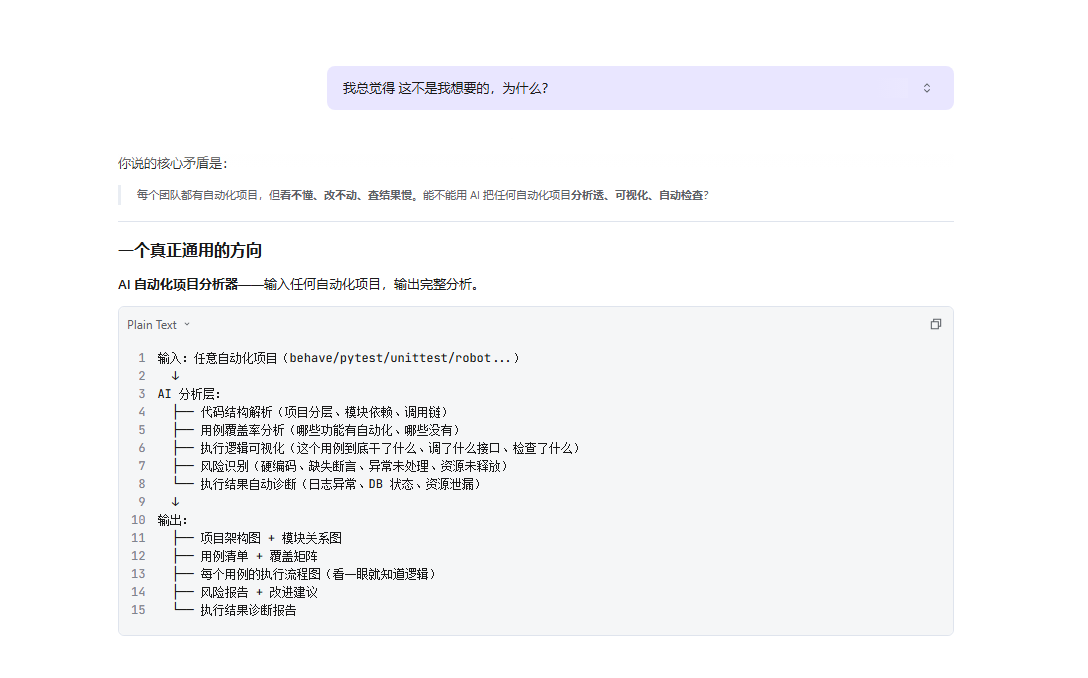
另外还有几个一直困扰我的问题:项目跑了好几年,1500 多个场景、3000 多个步骤定义,没人说得清覆盖了什么、哪些能复用;新人接手项目,从读代码到写出可执行的用例,链路太长;每次用 AI 帮忙,做完就是一次对话,**成果沉淀不下来**。
## 3. 实践过程
### 3.1 否掉第一版方案
我一开始让 SOLO 给方向,它列了 好几个方向:知识库建设、智能用例生成、自动化执行、结果验证、可视化报告、持续集成、团队协作。
我直接否了。**太虚,不具体,跟市面上已有的方案没区别。**
这次否定很关键,它让 SOLO 停止给大而全的方案,开始认真理解我的痛点。
### 3.2 读论文找方法论
我觉得光让 AI 自己想不够,让它帮我读了三篇:
**Apple《Reinforcement Infused Agentic RAG》**——学到两点:执行结果要反馈给系统让下次生成更好(回答了知识库怎么保持最新);评估不只看对错还要看效率和可维护性(回答了自检标准)。
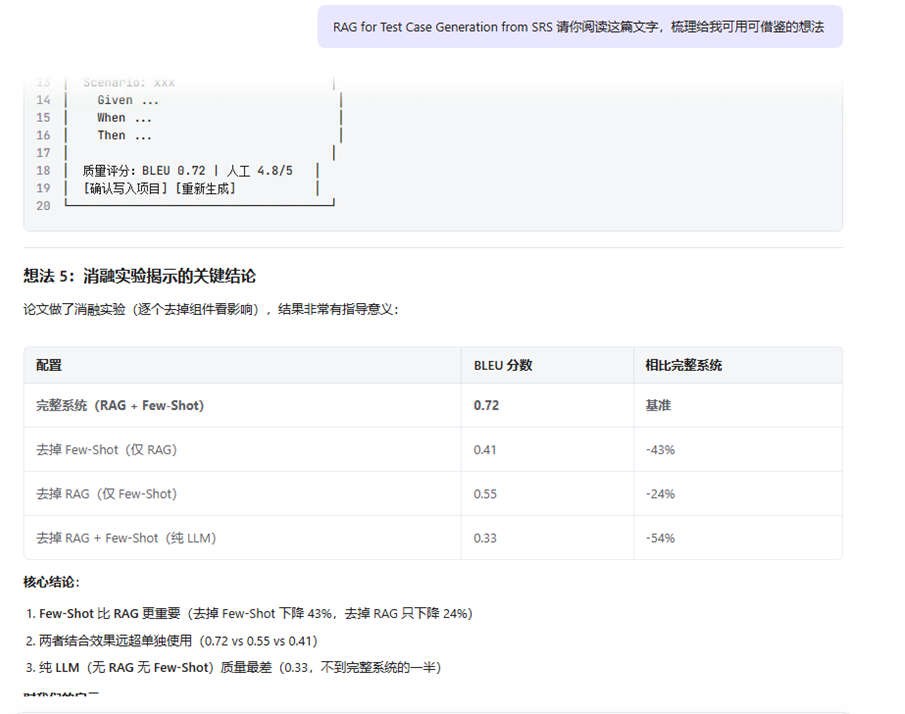
**《Leveraging RAG for Automated Test Case Generation from SRS》**——给了一个关键结论:**Few-Shot(给示例)比 RAG(检索)更重要,去掉 Few-Shot 质量下降 43%,去掉 RAG 只下降 24%。** 另外提到用 behave --dry-run 空跑验证生成用例,不通过的直接丢弃。
**《AI测试用例的幻影迷局》(CSDN 实战文章)**——作者团队搞了四重防御体系,各层独立拦截率 76% 到 99%,**3 个月把幻觉率从 31% 降到 4.2%**。这让我确信幻觉可以被系统性控制。
### 3.3 把问题变成方案
我梳理了 6 个核心问题,逐个转化为技术方案:
**问题:AI 的成果无法沉淀**
→ 用 Python ast 模块解析项目代码,建一个增量知识库(6 个 JSON 文件),文件哈希检测变更,只重新分析改过的部分。**实测 610 个文件 9.54 秒完成分析。**
**问题:已有方法怎么复用**
→ 知识库记录每个方法的名称、参数、返回值,新需求来的时候先检索已有能力,能复用的直接用。
**问题:怎么生成不重复的用例**
→ RAG 检索知识库中匹配的已有步骤 + Few-Shot 提供同领域参考示例 + LLM 生成。生成后过四重防御:知识锚定(只用知识库中存在的方法)→ 逻辑断路器(检查步骤顺序)→ 模拟沙箱(dry-run 验证)→ 人工审核(标记低置信度用例)。
**问题:预期结果检查怎么做(核心)**
→ 设计了四层检查模型:
- **L1 资源健康**:fd 泄漏、内存、磁盘、日志 ERROR、进程、端口。before_scenario 记录基线,after_scenario 对比差异。**全自动,不需要业务知识。**
- **L2 系统状态**:任务状态码、设备状态,模板匹配。半自动。
- **L3 接口返回**:API 返回值校验。半自动。
- **L4 业务结果**:数据一致性,用户配置规则。
原型数据:**L1 六项检查平均不到 1 秒,L2 不到 2 秒。** 原来 30-60 分钟的手动检查,**L1+L2 可以在 5 秒内完成大部分常见项。**
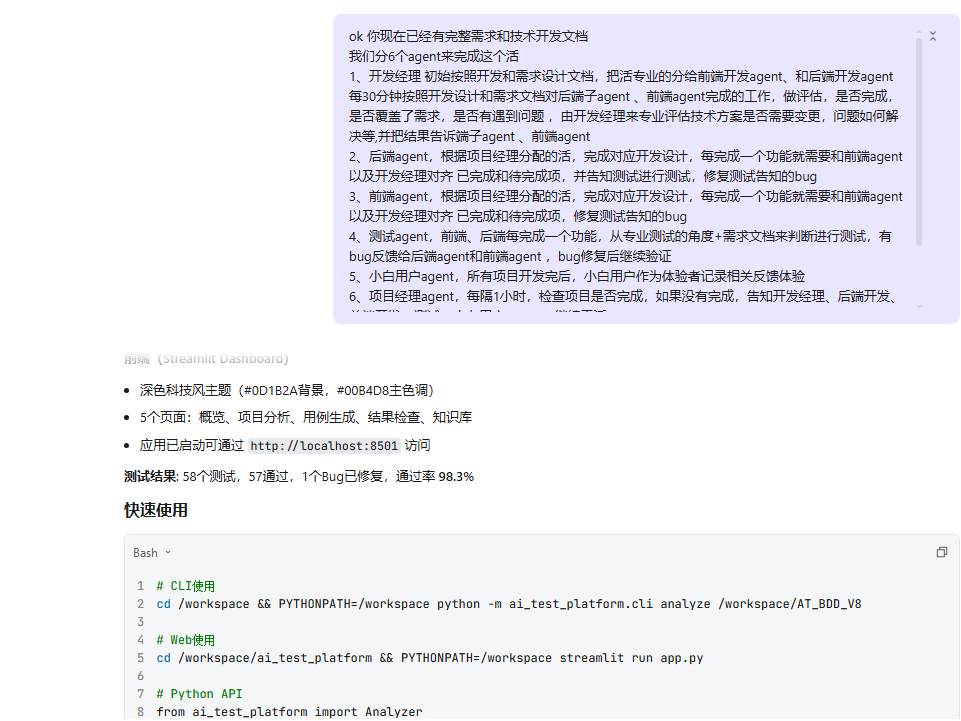
### 3.4 6 个 Agent 协作验证
方案设计完,我让 SOLO 模拟 6 个角色验证可行性:项目经理做计划、开发经理做评审、后端 Agent 写代码、前端 Agent 搭 Streamlit、测试 Agent 跑测试、小白用户做体验验证。
**踩过的坑:**
- SOLO 第一版方案太虚被我否了——**不能让 AI 给「全面」的方案,要逼它给「具体」的**
- 最初每个环节单独用 AI,成果无法沉淀——**必须有知识库来承载上下文**
- 论文结论 Few-Shot > RAG 直接改变了优先级——**先把示例库做好比先搞向量检索更有效**
- Streamlit 部署到服务器遇到版本兼容问题——label_visibility 参数在 1.x 和 2.x 之间不兼容
### 3.5 关键 Prompt
**让 SOLO 从「虚」变「实」:**
> 我迫切的想要改变测试的效率,帮我做执行,帮我检查结果,缩短测试执行时间。给出的方向都很虚,不务实,使用范围都很小,一直在重复造轮子。每次看到别人的项目都有使用了很多高大上的方法,给出的东西价值太低。
**让 SOLO 读论文并提炼:**
> 阅读这篇论文,梳理对我可借鉴的地方。重点关注:1. 什么技术可以直接用在自动化测试中 2. 什么数据可以证明这个技术有效 3. 落地的最小可行方案是什么
**让 SOLO 做多视角评审:**
> 从专业测试、专业开发、初级用户使用、专业框架设计四个角度,分析我们的自动化框架设计不合理的地方,给出具体改进意见和建议。不要泛泛而谈,要给出具体的代码级改进建议。
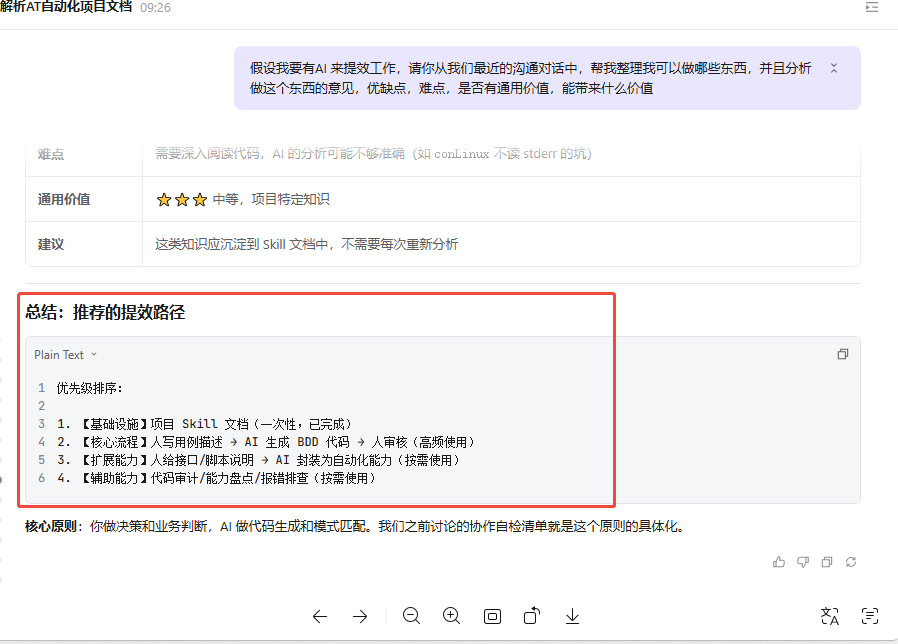
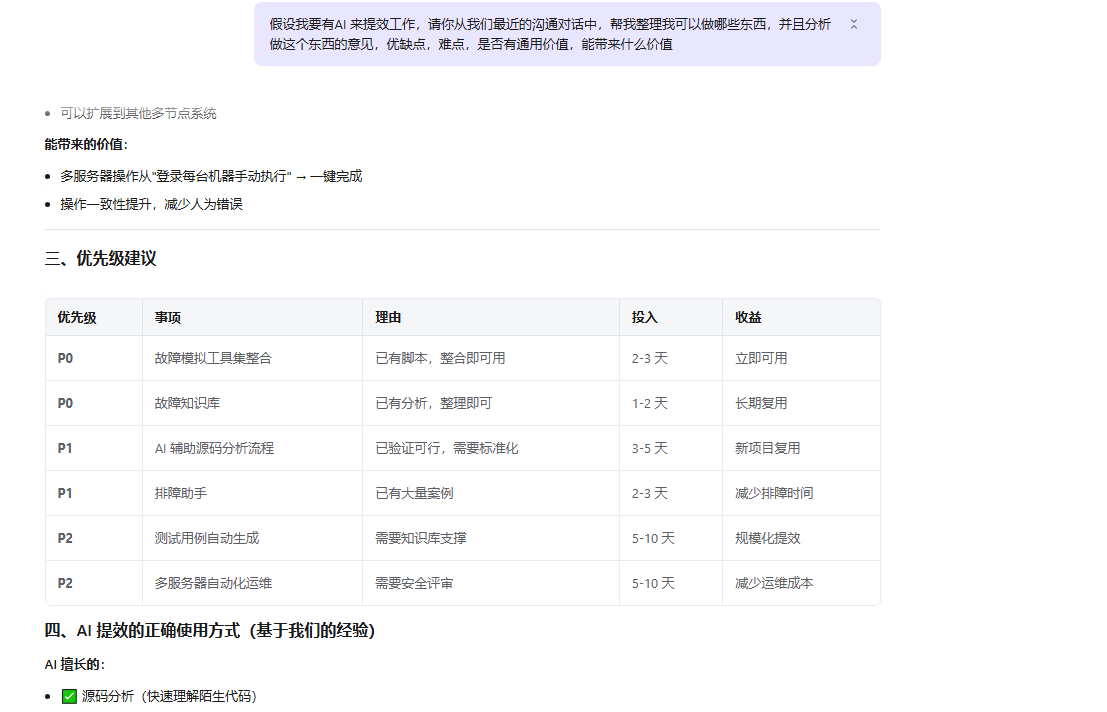
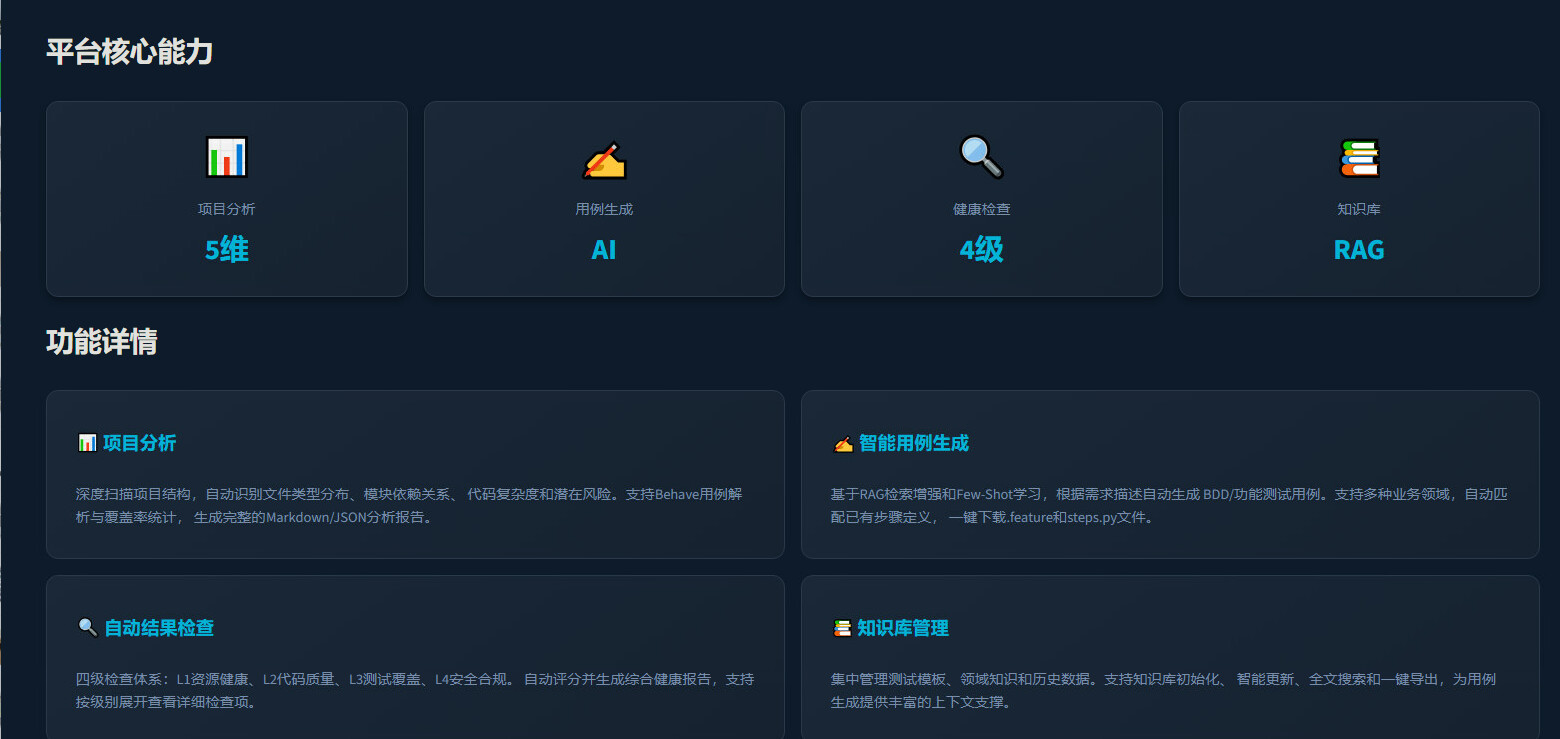
## 4. 成果展示
**原型数据:** 29 个 Python 文件、9242 行代码、**58 个测试用例通过率 98.3%**。
**项目分析:** 610 文件 / 184 Feature / 1552 Scenario / 3082 Step,**9.54 秒完成**。
**用例生成:** 共生成 61 个用例,防御体系拦截 3 个疑似幻觉,剩余 58 个执行测试。
**结果检查:** L1+L2 两层自动检查,**单场景从 30-60 分钟降至 5 秒以内**。
**配套文档:** 产品演示 PPTX(14 页)、产品需求文档、开发设计文档、可行性分析报告、项目进度报告。
## 5. 效果与总结
**提效数据:**
| 环节 | 之前 | 之后 |
|------|------|------|
| 理解一个陌生项目 | 半天~1天 | **< 10 秒**(项目分析) |
| 单场景结果检查 | 30-60 分钟 | **< 5 秒**(L1+L2 自动) |
| 新人上手了解项目全貌 | 1-2 个月 | **< 1 小时**(看分析报告) |
**几点体会:**
**AI 完全可以当执行者,但需要给它上下文。** 先分析项目建知识库,再基于知识库去执行,效果完全不一样。
**测试提效的真正瓶颈是结果验证,不是写用例。** 写用例占 20% 时间,执行和验证占 80%。四层检查模型把那 80% 分层自动化了,**这个投入产出比远比优化用例生成高。**
**控制幻觉比生成更重要。** 四重防御不是过度设计,是刚需。
**SOLO 最大的价值不是帮我写代码,而是帮我理清思路。** 从观察行业现状、到否定泛泛方案、到读论文找方法论、到把模糊问题转化为具体方案,**这个过程比最终产出的代码更有价值。**