1. 摘要
这次我用 TRAE SOLO 辅助开发了一套轻量级视频转码控制面服务:mps-transcode-serverless。
它解决的问题是:业务系统只提供一个外部视频 URL,服务自动完成素材拉取、COS 暂存、腾讯云 MPS 转码、回调处理、状态管理、CDN 地址返回和短周期清理,最终把各种来源的视频统一转换成可投放、可访问的 MP4 CDN 地址。
这个项目不是单纯调用一个云 API,而是围绕真实生产链路补齐了幂等、回调、补偿、Serverless 部署、MySQL 状态管理、COS 生命周期、并发竞争处理等一整套工程化能力。
2. 背景
我的工作场景和广告素材分发、ADX/DSP 投放链路有关。
在广告投放系统里,经常会遇到这样的问题:
业务方给过来的素材可能是:
-
外部 HTTP/HTTPS 视频 URL;
-
COS 上的原始视频文件;
-
不同格式、不同编码的视频;
-
临时有效的素材地址;
-
不同媒体侧要求不一致的视频格式。
但投放链路最终更希望拿到一个标准化结果:
稳定可访问的 MP4 CDN 地址
如果只是本地用 FFmpeg 转一次,当然很简单。
但一旦进入生产环境,会遇到很多实际问题:
-
外部 URL 不一定能被腾讯云 MPS 直接拉取;
-
转码任务是异步的,需要回调处理;
-
回调可能重复、乱序或丢失;
-
Serverless 实例会扩缩容,内存状态不可靠;
-
同一个素材不能重复提交、重复扣费;
-
转码完成后需要把 COS 输出改写成业务 CDN 地址;
-
原始素材和转码结果都不能永久保存,需要生命周期清理;
-
MySQL 任务状态也不能无限增长,需要定时清理。
所以我希望做一个小而完整的控制面服务,把这些复杂性封装起来。
3. 实践过程
这次开发主要使用 TRAE SOLO 来完成需求拆解、代码实现、测试补齐和部署排查。
整体流程可以概括为:
需求拆解
-> 设计接口和状态机
-> 实现 Go 服务
-> 接入腾讯云 MPS / COS / MySQL
-> 补齐回调和幂等
-> Serverless zip 部署
-> 线上日志排查和修复
-> 生命周期清理
4. 任务拆解方式
我先让 SOLO 帮我把需求拆成几个模块:
1. HTTP API 层
2. 转码服务业务层
3. 腾讯云 MPS 适配层
4. COS staging 层
5. MySQL job store
6. MPS callback 解析
7. ADX outbound callback
8. 定时补偿 sync
9. Serverless 部署
10. MySQL cleanup 定时函数
其中比较核心的接口包括:
POST /jobs/submit
POST /jobs/batch-submit
GET /jobs/{id}
POST /jobs/callback
POST /jobs/{id}/sync
POST /admin/sync-stale
单个素材提交:
{
"source_url": "https://example.com/video.f4v",
"template_id": "328016"
}
批量提交:
{
"template_id": "328016",
"callback_url": "https://adx.example.com/callback",
"items": [
{
"external_id": "creative-001",
"source_url": "https://example.com/a.f4v"
},
{
"external_id": "creative-002",
"source_url": "https://example.com/b.f4v"
}
]
}
5. SOLO 在开发中的作用
这次不是让 AI 一次性“写完整项目”,而是把任务拆成小块,逐步推进。
我比较常用的 Prompt 方式是:
请基于当前 Go 项目,实现一个批量提交接口 POST /jobs/batch-submit。
要求:
1. items 最多支持环境变量 BATCH_SUBMIT_MAX_URLS 控制;
2. 每个 item 独立返回结果;
3. 单个 URL 失败不能影响整个 batch;
4. 使用 source_url + template_id 做幂等;
5. 重复 URL 要返回 duplicate_of;
6. 补充单元测试。
另一个例子是排查线上回调 panic:
这是 SCF 日志:
callback: concurrent update detected on callback, other instance won the race
随后 jobToView(nil) panic。
请分析根因,并做最小修复。
要求:
ErrConcurrentUpdate 时重新 Repo.Get(ctx, jobID) 并返回当前 job。
补充回归测试。
SOLO 很适合这种“明确边界 + 明确验收条件”的开发方式。
我的经验是:
不要一次性让 AI 做整个系统。
要把任务拆成接口、状态机、存储、回调、部署、测试几个小步骤。
每一步都要求它自测和解释。
6. 整体架构
最终服务链路大致是:
ADX / 投放系统
-> 提交外部视频 URL
-> mps-transcode-serverless
-> 下载源视频
-> 上传到 COS staging
-> 调用腾讯云 MPS ProcessMedia
-> MPS 异步转码
-> MPS 回调 /jobs/callback
-> 更新 MySQL job 状态
-> 生成 CDN MP4 地址
-> 回调 ADX / 返回查询结果
核心组件:
Go HTTP Server
提供 submit、batch-submit、callback、query、sync 等接口。
Tencent MPS Adapter
封装 ProcessMedia 和 DescribeTaskDetail。
COS Stager
把外部 HTTP/HTTPS 视频下载后上传到 COS,再交给 MPS。
MySQL Store
保存 job 状态、幂等 key、MPS task id、回调事件、CDN URL。
Serverless SCF
主 Web 函数处理 API 请求和 MPS 回调。
Cleanup SCF
定时清理 3 天前的 MySQL job 状态。
7. 关键实现一:外部 URL 先 staging 到 COS
实际接入时发现,不能假设腾讯云 MPS 一定能直接处理任意公网 URL。
所以服务做了一层 staging:
外部 URL
-> 服务下载
-> 上传 COS staging
-> 得到 cos://bucket/region/object
-> 传给 MPS
staging 文件路径类似:
staging/{jobID}/source.f4v
这样 MPS 输入更加稳定,也方便做生命周期管理。
8. 关键实现二:幂等和去重
同一个素材不能反复提交,否则会造成重复转码、重复计费。
所以项目使用:
NormalizeSourceURL(source_url) + effective_template_id
作为幂等 key。
如果同一个素材之前已经提交过:
-
已成功:直接返回
ready + cdn_url -
处理中:返回
processing + job_id -
已失败:允许重新提交
批量接口里还做了同批次去重:
{
"index": 3,
"status": "ready",
"duplicate_of": 0
}
这样一个 batch 里重复出现的 URL 不会重复提交 MPS。
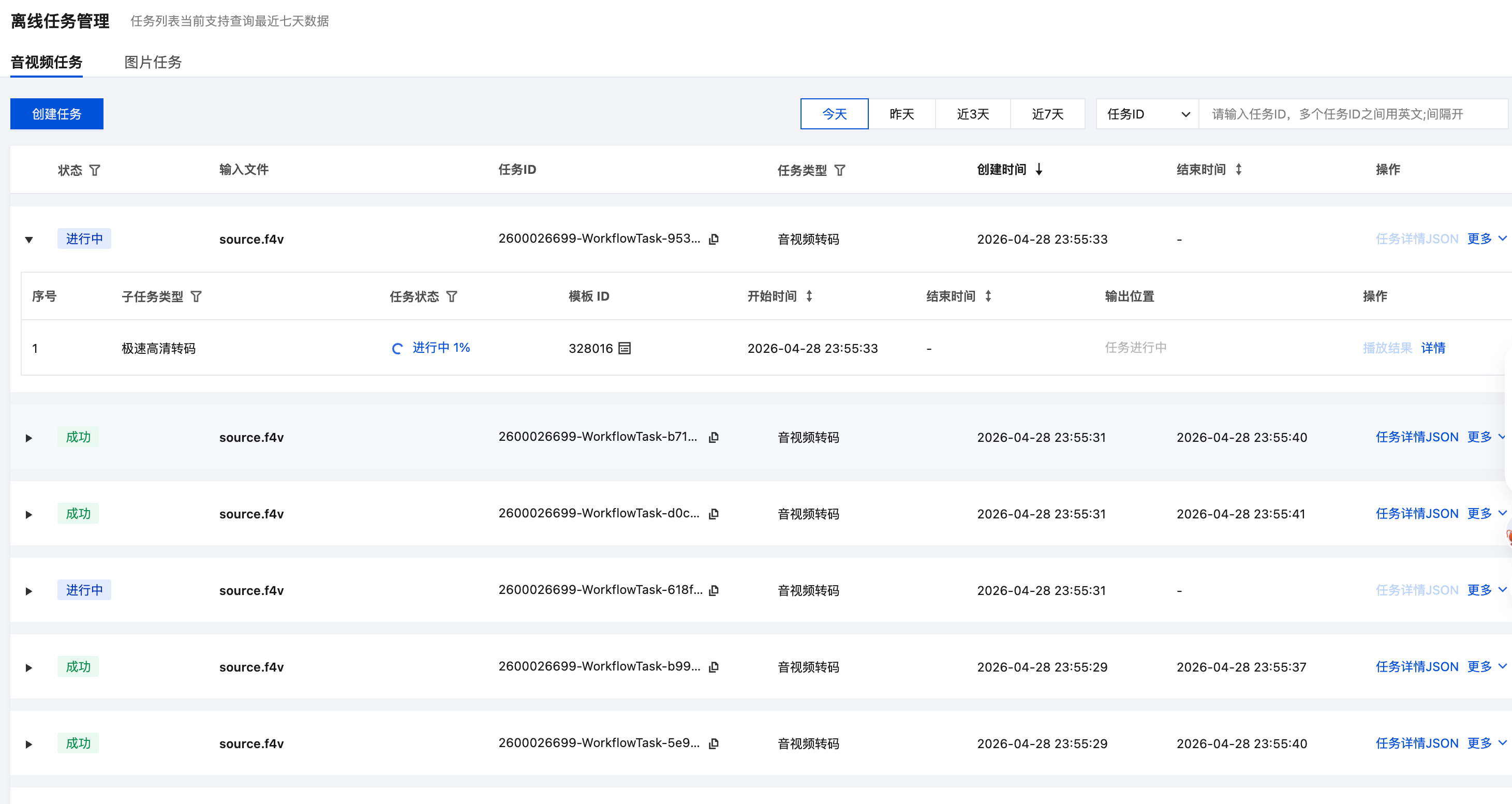
9. 关键实现三:MPS 回调解析和 CDN URL 改写
MPS 回调 payload 有一定复杂性,不同任务类型外层结构可能不同。
项目里做了兼容解析:
ProcedureStateChangeEvent
ProcedureStateChangedEvent
WorkflowTaskEvent
WorkflowTask
TaskEvent
Data
EventContent
另一个坑是 MPS 输出里真正可用的路径在:
TranscodeTask.Output.Path
而不是 Output.Object。
最终服务会把 MPS 输出路径改写成业务 CDN 地址:
/transcode/{jobID}/xxx_transcode_328016.mp4
改写为:
https://cdn-mps.360os.com/transcode/{jobID}/xxx_transcode_328016.mp4
也就是说业务方拿到的是稳定的 CDN 地址,而不是原始 COS 地址。
10. 关键实现四:并发回调和乐观锁
Serverless 场景下,同一个 MPS 回调可能被多个实例并发处理。
项目里 MySQL job 使用 version 字段做乐观锁:
UPDATE transcode_jobs
SET ...
WHERE id = ? AND version = ?
如果更新行数为 0,说明另一个实例已经抢先更新成功。
线上真实遇到过一次问题:
callback: concurrent update detected on callback, other instance won the race
http: panic serving ...
jobToView(0x0)
根因是并发更新被识别后,服务返回了:
return nil, nil
HTTP 层以为成功了,于是执行:
jobToView(job)
最终 job == nil 导致 panic。
修复方式是:
if errors.Is(err, ErrConcurrentUpdate) {
log.Printf("callback: concurrent update detected ...")
return s.Repo.Get(ctx, req.JobID)
}
也就是并发竞争失败的一方重新读取当前 job 返回。
这个问题也补了回归测试,覆盖第一次 Save 和 ADX callback 二次 Save 两个场景。
11. 关键实现五:回调丢失后的补偿同步
MPS 回调不是百分百可靠,网络、配置、签名、实例冷启动都可能导致回调失败。
所以项目提供了同步接口:
POST /jobs/{id}/sync
它会主动调用腾讯云:
DescribeTaskDetail
查询 MPS 任务状态,并更新本地 MySQL job。
还提供了定时扫描卡住任务的能力:
POST /admin/sync-stale
用于补偿长时间停留在:
pending
submitted
running
的任务。
12. 关键实现六:Serverless 部署
项目使用 Go 编译成腾讯云 SCF Web 函数需要的 zip 包。
打包结果必须包含:
scf_bootstrap
不是 bootstrap。
Makefile 里现在区分了 Web 函数和 cleanup 定时函数:
make package-web
make package-cleanup
make deploy-web
make deploy-cleanup
Web 主函数负责:
/jobs/submit
/jobs/batch-submit
/jobs/callback
/jobs/{id}
cleanup 定时函数负责:
每小时清理 MySQL 中超过 3 天的 job 记录
cleanup 函数使用同一个 function.zip,只是环境变量不同:
APP_MODE=cleanup-jobs
JOB_RETENTION_DAYS=3
JOB_CLEANUP_BATCH_SIZE=1000
13. 生命周期设计
为了避免数据无限增长,最终生命周期设计为:
COS staging 原始/临时文件:1 天
COS transcode 转码输出文件:3 天
MySQL job 状态记录:3 天
COS 文件过期靠 COS 生命周期规则:
staging/ 1 天删除
transcode/ 3 天删除
MySQL 清理靠定时 SCF:
DELETE FROM transcode_jobs
WHERE updated_at < 当前时间 - 3 天
LIMIT 1000
这样 MySQL 不作为长期素材库,只承担短期状态、幂等、回调去重和查询功能。
14. 踩坑记录
这次最有价值的地方其实不是写 API,而是把生产坑一个个补上。
坑一:SCF 函数超时默认只有 3 秒
线上出现过:
batch-submit: internal error: context canceled
Invoking task timed out after 3 seconds
根因是 SCF 超时还是默认 3 秒。
batch-submit 会同步做下载、上传 COS、调用 MPS、写 DB,3 秒完全不够。
最终 Web 函数超时设置为:
180 秒
坑二:Web 函数可执行文件必须叫 scf_bootstrap
腾讯云 SCF Web 函数 Go 运行时要求 zip 根目录里的文件名是:
scf_bootstrap
不是:
bootstrap
否则会出现启动失败或 exec format 类问题。
坑三:MPS 回调 SessionId 在外层
真实 MPS 回调里:
{
"EventType": "WorkflowTask",
"WorkflowTaskEvent": {...},
"SessionId": "job_id",
"SessionContext": "job_id"
}
SessionId 和 SessionContext 不在 WorkflowTaskEvent 里面,而在外层。
解析时需要把外层字段传播进内层,否则会出现:
job_id is required
坑四:TaskId 不能单独作为回调去重 key
MPS 会对同一个任务发多次状态回调,例如:
PROCESSING
FINISH
如果只用 TaskId 做事件去重,FINISH 可能被当成重复事件跳过。
最终事件 ID 使用:
TaskId + "/" + Status
坑五:输出路径在 Output.Path
MPS 回调里转码文件路径在:
Output.Path
不是:
Output.Object
CDN URL 需要基于 Output.Path 拼出来。
15. 成果展示
目前项目已经实现:
![]() 单 URL 转码提交
单 URL 转码提交
![]() 批量 URL 转码提交
批量 URL 转码提交
![]() 同批次 URL 去重
同批次 URL 去重
![]()
source_url + template_id 幂等
![]() 外部 URL staging 到 COS
外部 URL staging 到 COS
![]() 腾讯云 MPS ProcessMedia 接入
腾讯云 MPS ProcessMedia 接入
![]() MPS 回调解析
MPS 回调解析
![]() CDN URL 改写
CDN URL 改写
![]() ADX outbound callback
ADX outbound callback
![]() MySQL 状态管理
MySQL 状态管理
![]() 乐观锁防并发覆盖
乐观锁防并发覆盖
![]() 回调丢失后的 sync 补偿
回调丢失后的 sync 补偿
![]() stale job 定时扫描
stale job 定时扫描
![]() Serverless zip 部署
Serverless zip 部署
![]() cleanup 定时函数
cleanup 定时函数
![]() COS / MySQL 短周期清理策略
COS / MySQL 短周期清理策略
16. 效果与总结
这个项目的价值不在于“调用了一次腾讯云 MPS”,而在于把一个真实业务链路里容易出问题的部分工程化封装了起来。
对业务侧来说:
输入:一个视频 URL
输出:一个标准 MP4 CDN URL
中间的复杂性都被服务吸收:
-
源文件暂存;
-
云转码;
-
异步回调;
-
状态查询;
-
失败补偿;
-
幂等去重;
-
生命周期清理;
-
Serverless 部署。
对我个人来说,TRAE SOLO 在这个项目里的价值主要体现在三点:
第一,帮助我把一个复杂需求拆成多个小任务,而不是一开始就陷入细节。
第二,在 Go 代码、测试、部署模板之间来回切换时,SOLO 能持续保持上下文,适合做这种多模块工程项目。
第三,线上问题排查时,我可以直接把 SCF 日志贴给 SOLO,让它定位到具体代码路径,再做最小修复和回归测试。
最后总结一句:
AI 编程最适合的不是“替我写完一切”,而是把真实工程里的每一个小闭环快速完成:设计、实现、验证、排查、修复、沉淀。
这个项目就是一次比较完整的实践。