① 摘要
研究生在读,打算投暑假实习。
网申投递本身不复杂,但重复劳动太多:传一份 PDF 简历,再手动把教育、实习、项目经历填进不同公司的系统里。换一个岗位,又要重新改模板、重新上传每次投递要花数10分钟,效率太低了。
试了几次之后,觉得不如自己做个工具来解决。
这个工具针对应届生和在校大学生,核心做了四件事:
- PDF 简历智能解析(金融、互联网、制造业等不同格式都测过)
- 素材库管理(经历分门别类存起来)
- 多模板简历生成(根据岗位快速切换版式)
- 网申表单快速填写(减少复制粘贴)
- 网申表单自定义(根据岗位需求添加、删除、修改字段)
经过多轮真实简历测试,解析准确率和分类正确率已经到了能用的程度。
不算什么大东西,但是能解决自己投实习时的具体麻烦。
② 真实场景与需求
目标人群: 2026 届及以后的在校大学生,尤其是需要同时投递多个岗位、频繁填写网申表单的同学。
痛点描述:
- 简历改到崩溃:不同岗位需要不同侧重点的简历,每次都从零开始改,投了 20 份简历石沉大海,不知道问题出在哪
- 网申填到手软:每个公司的网申系统都要填自我介绍、实习经历、项目经历、求职动机……同样的内容反复手打,费时又容易出错
- 旧简历没法复用:之前写的简历是 PDF,想改一改投新岗位,却只能对着 PDF 重新手敲一遍
- 不知道该写什么:看到网申上的开放性问题(“你的职业规划是什么?”“你遇到的最大挑战是什么?”)大脑一片空白
③ 作品介绍
作品名称:ResumeKit — 网申辅助工具
作品类型:网页工具(纯前端单页应用,无需后端服务器)
核心功能:
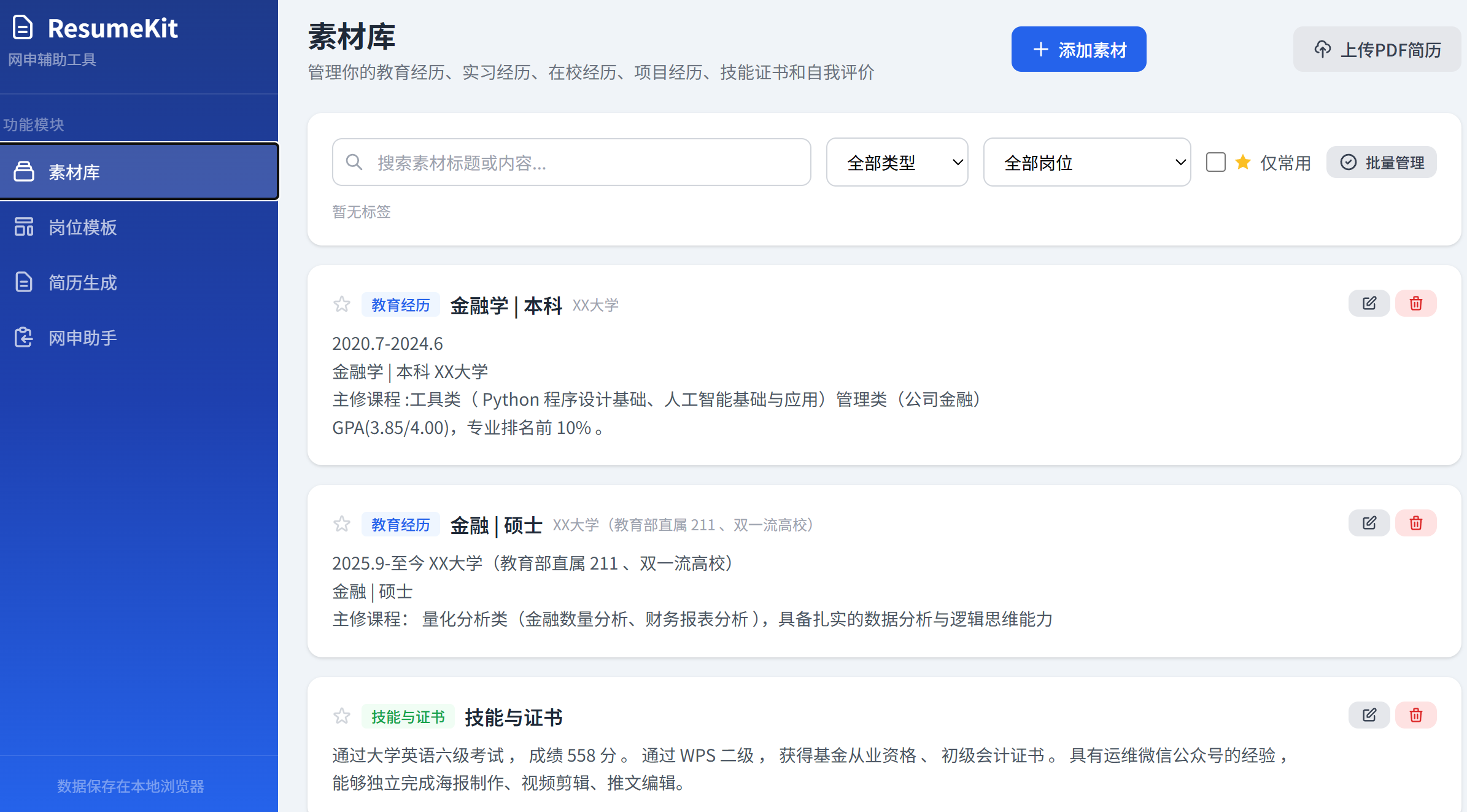
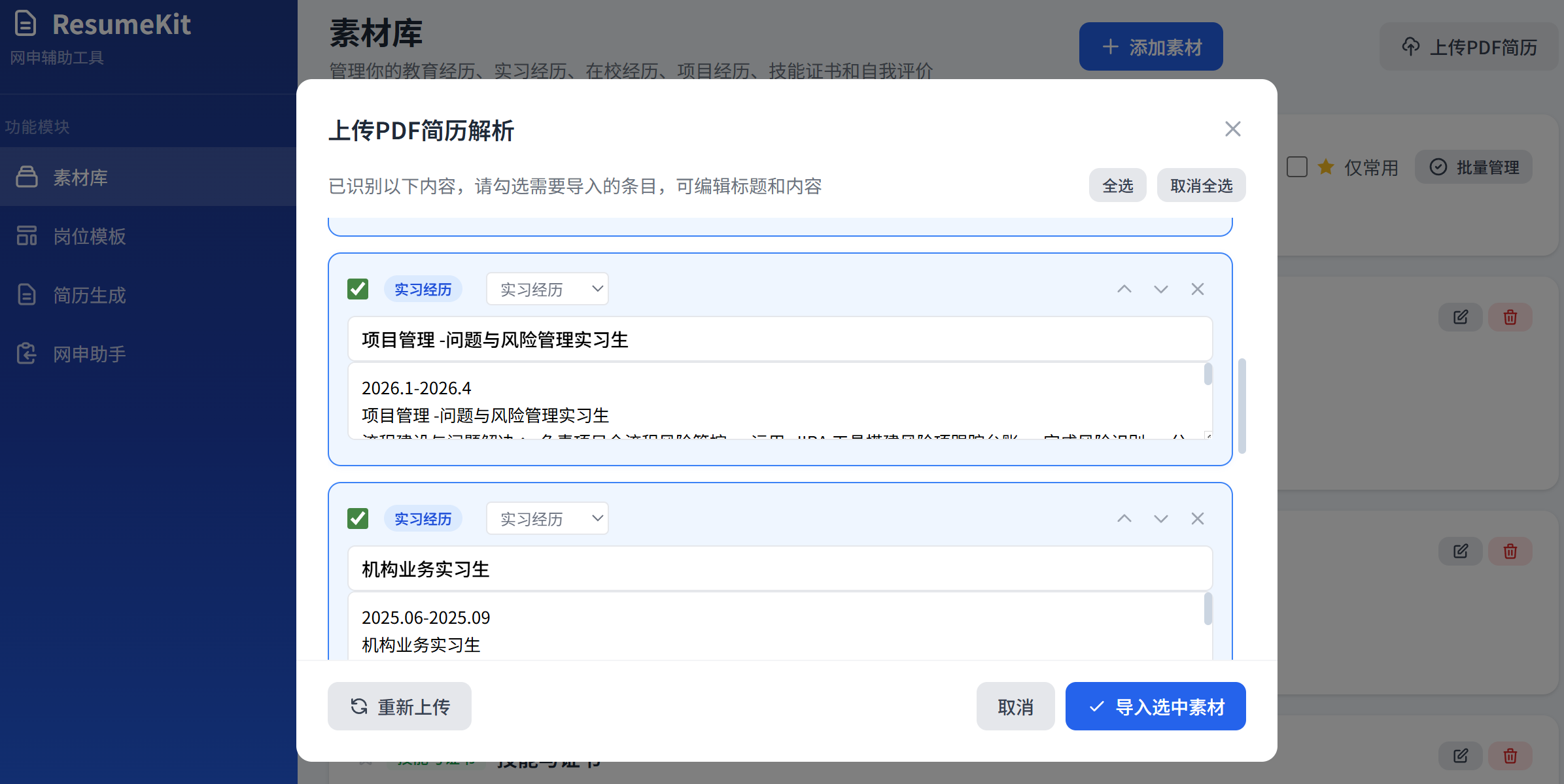
- PDF 简历智能解析:用户上传旧版 PDF 简历,工具自动识别教育经历、实习经历、在校经历、项目经历、技能证书、自我评价六大板块,提取公司名、职位名、时间线等结构化信息,一键导入素材库
- 素材库管理:将个人经历按类型分类管理,支持标签、适用岗位标记、搜索筛选、批量操作,一次录入、多份简历复用
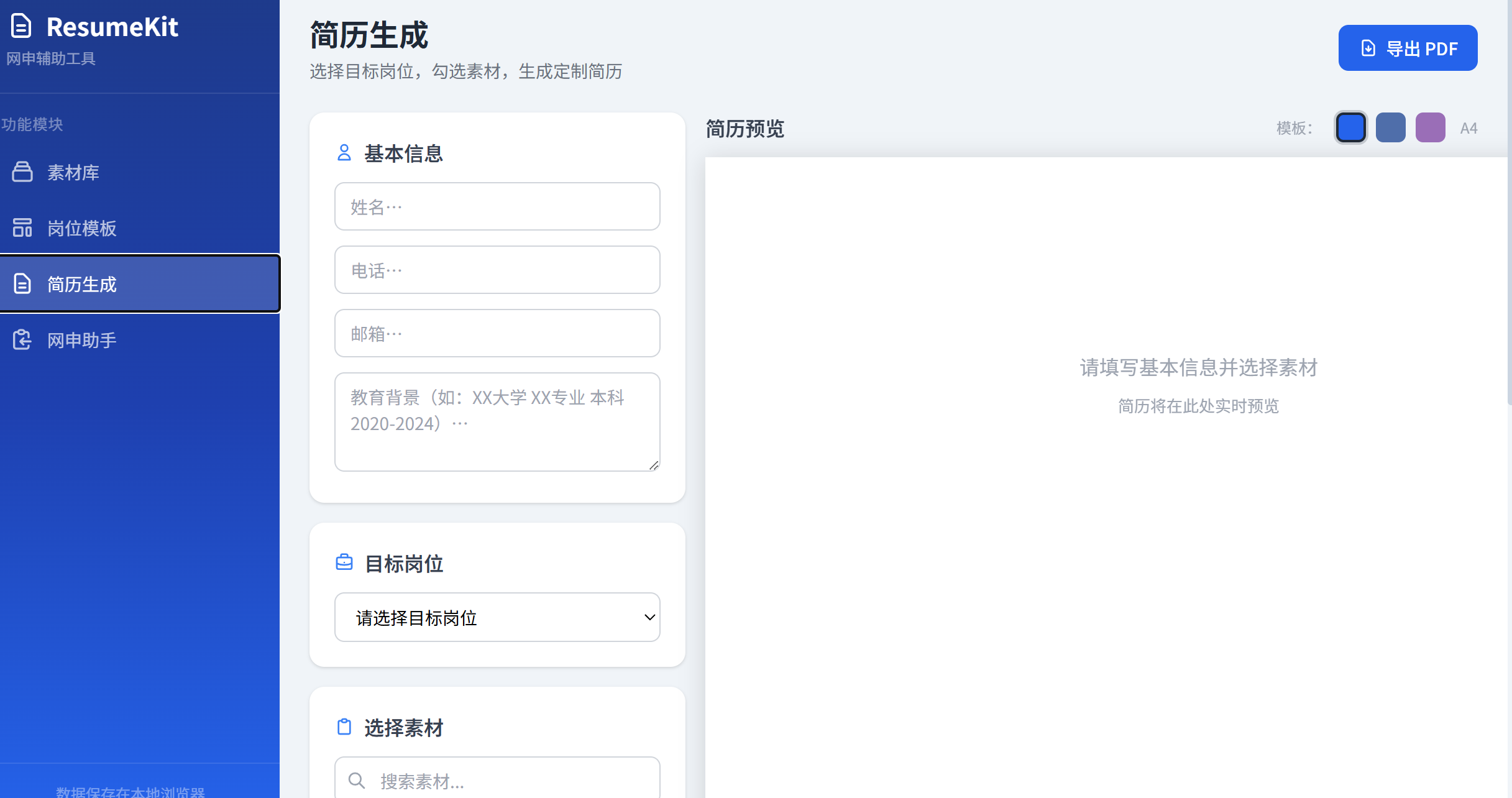
- 多模板简历生成:提供 3 种专业简历模板,按岗位方向智能推荐素材,实时 A4 预览,一键导出 PDF
- 网申助手:预设自我介绍、实习经历、项目经历、求职动机、职业规划、最大挑战、为什么选择该公司 7 大常见网申字段,素材一键选用,内容一键复制到剪贴板
技术方案:纯前端实现 — HTML + Tailwind CSS + 原生 JavaScript,PDF.js 解析简历文本,html2pdf.js 导出 PDF,localStorage 本地持久化存储,零后端依赖
④ 用 SOLO 实现的过程
4.1 任务拆解
我将整个项目拆解为以下步骤:
-
需求分析与功能设计(确定四大模块、素材类型体系、岗位模板)
-
素材库模块开发(增删改查、搜索筛选、批量管理)
-
PDF 简历解析模块开发(文本提取 → 板块识别 → 子项拆分 → 类型判断 → 公司名提取)
-
简历生成模块开发(基本信息、素材选择、实时预览、模板切换、PDF 导出)
-
网申助手模块开发(字段管理、素材选用、一键复制)
-
岗位模板模块开发(8 个岗位方向、推荐标签、素材匹配)
-
测试与迭代优化(PDF 解析准确率提升、Web Design Guidelines 合规审查)
-
Bug 修复与体验优化(浏览器兼容、缓存问题、交互细节打磨)
4.2 关键实现过程
模块一:PDF 简历智能解析
目标:上传 PDF 简历后,自动识别六大板块(教育经历、实习经历、在校经历、项目经历、技能证书、自我评价),提取每个条目的标题、公司名、时间线和详细描述。
使用的 SOLO 能力:代码生成、调试排错、文件读取
关键 Prompt 与迭代过程:
第1版 Prompt:
"我想制作一个网申辅助工具,根据不同的职位,生成不同版本的简历;类似一个个人库,我可以根据网申中需要填写的内容选择内容去复制粘贴。添加素材的方式,增加一个解析pdf简历(我直接上传简历就可以更新素材),同时保留手动添加素材的功能。"
→ 问题:
1. 板块识别不准确——"宣传部部长"被识别为教育背景(因为包含"部"字)
2. 公司名和职位名错配——"XX集团-XX股份有限公司"和"项目管理实习生"被拆到了不同条目
3. "在校经历"板块标题未被识别,内容被错误归入实习经历
4. 教育背景缺少独立分类,本科和硕士经历被标记为"实习经历"
第2版 Prompt(优化后):
"优化 PDF 简历解析逻辑:
1. 板块标题匹配使用行首锚定(^),避免正文内容误匹配
2. 日期行作为子项起始标记,下一行的职位名自动关联为标题
3. 添加'在校经历'到校园经历匹配规则
4. 新增'教育经历'独立分类,不再强制映射为实习经历
5. 修复'至今'日期正则,避免公司名前多出'今'字"
→ 效果:
- 六大板块全部正确识别,分类准确率显著提升
- 公司名与职位名正确关联,不再错配
- "至今"日期格式正确处理,公司名提取准确
踩坑记录:
- 正则捕获组索引错误:提取公司名的正则有两个捕获组,代码错误地使用了
match[1](可选日期部分)而非match[2](公司名),导致Cannot read properties of undefined (reading 'trim')崩溃。通过打印正则匹配结果才发现索引搞反了。- "至今"日期处理:正则
[-–—~~至到]中的"至"被单独匹配消费,导致"至今 xx大学"中的"今"字残留在公司名中。解决方案:将分隔符改为[-–—~~],再用(?:至今)?整体匹配"至今"。- "瘦"条目合并过于激进:合并逻辑将有实质描述的条目(如"协助对接银行渠道资源")误判为"瘦"条目并合并到前一条。解决方案:改为只合并去除日期行和标题后描述内容 <10 字的真正空条目。
- 导航项从 div 改为 button 后样式崩溃:按 Web Design Guidelines 将
<div onclick>改为<button>后,浏览器默认按钮样式覆盖了自定义 CSS,导致所有交互失灵。解决方案:添加border: none; background: none; font: inherit; width: 100%; text-align: left;重置默认样式。- 多余的闭合大括号导致全局语法错误:重构
splitSectionBySubItems函数时遗留了一个多余的},导致后续代码变成全局作用域,return语句触发Illegal return statement,整个 JavaScript 执行中断。这个 bug 花了多轮排查才定位到。
模块二:素材库与简历生成
目标:将解析出的经历素材结构化管理,支持按岗位方向智能推荐,实时预览并导出 PDF 简历。
使用的 SOLO 能力:代码生成、Web Design Guidelines 审查
关键 Prompt:
"实现素材库管理功能:
- 6 种素材类型(教育经历、实习经历、在校经历、项目经历、技能与证书、自我评价)
- 支持标签、适用岗位、常用标记
- 搜索、筛选、批量操作
- 简历预览支持 3 种模板切换
- 一键导出 A4 格式 PDF"
踩坑记录:
- 教育经历类型缺失:最初设计时没有"教育经历"分类,教育背景被强制映射为"实习经历"(
education: 'internship'),导致本科和硕士经历显示为实习经历。需要在所有下拉菜单、类型映射、简历预览渲染中全面添加 education 支持。- Web Design Guidelines 合规:通过 SOLO 的 Web Design Guidelines 审查,发现 80+ 处合规问题,包括模态框缺少 ARIA 属性、图标按钮缺少 aria-label、表单控件缺少 label、
transition: all反模式等,逐一修复。
模块三:网申助手
目标:预设常见网申字段,支持从素材库快速选用内容,一键复制到剪贴板。
使用的 SOLO 能力:代码生成
踩坑记录:
剪贴板 API 在部分浏览器中不可用,需要
document.execCommand('copy')作为降级方案。
⑤ 成果展示
产品截图
素材库界面
图:素材库管理界面,支持 PDF 上传解析、搜索筛选、批量管理*
简历生成界面
图:简历生成界面,3 种模板切换,实时 A4 预览*
PDF 解析结果
图:PDF 简历智能解析结果,自动识别六大板块,支持编辑确认*
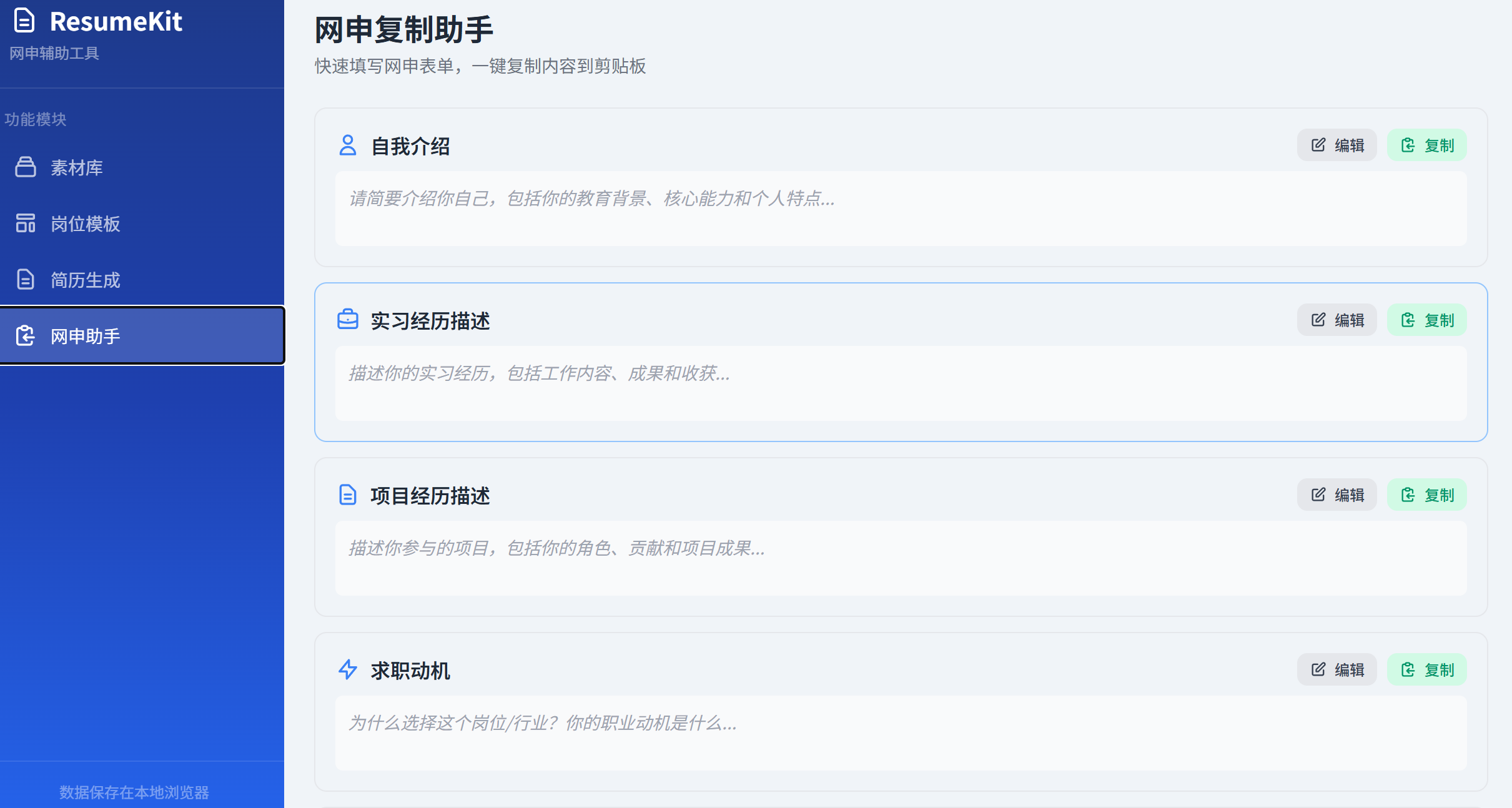
网申助手界面
图:网申助手界面,7 大预设字段,素材一键选用,一键复制*

技术亮点
| 亮点 | 说明 | ||
|---|---|---|---|
| 纯前端零后端 | 单个 HTML 文件,无需服务器,打开即用,数据完全本地化 | ||
| PDF 智能解析 | 多层解析策略:板块识别 → 日期行切分 → 类型判断 → 公司名提取 → 去重合并 | ||
| 素材复用体系 | 一次录入,多份简历、多个网申表单复用,告别重复劳动 | ||
| 岗位导向推荐 | 8 个岗位模板,自动匹配素材,精准投递 | ||
| 无障碍合规 | 通过 Web Design Guidelines 审查,支持键盘导航、屏幕阅读器 |
演示链接
-
在线体验:本地打开即可使用
-
代码仓库:单文件应用,无需仓库
⑥ 验证方式与下一步
验证方式
| 测试场景 | 输入 | 预期输出 | 实际表现 |
|---|---|---|---|
| 解析金融专业硕士简历 | xxx-个人简历2025A.pdf | 正确识别教育经历(2条)、实习经历(3条)、在校经历(1条) | |
| 解析含至今日期的简历 | 2025.9-至今 xx大学 | 公司名提取为xx大学,不含今字 | |
| 解析含校园职务的简历 | 宣传部部长 | 识别为在校经历,不误判为教育背景 | |
| 多公司实习经历拆分 | 3 段实习经历 | 拆分为 3 个独立条目,各自关联正确的公司和职位 |
下一步计划
- 增加 PDF 解析的简历格式兼容性(支持更多排版风格)
- 接入 AI 大模型,实现 JD 智能解析和简历内容优化建议
- 增加更多岗位模板(覆盖互联网、咨询、快消等行业)
- 支持简历内容的多语言版本(中英文切换)
- 部署上线,邀请更多同学试用并收集反馈
一句话总结:让每一个大学生都能零成本、高效率地管理求职素材、生成专业简历、快速填写网申,把重复劳动交给工具,把时间留给真正重要的事。