很有意思,但是试了挺多次也没有跳楼过,这没有失败结局吗
3 个赞
是的hhh,如果追求质量的话还是要开thinking。
3 个赞
似乎是deepseek的道德在这两天提高了,把死亡结局判断弄得很难。
我用gpt5.5试了一下,会好很多,很容易触发死亡结局 ![]()
3 个赞
这两天试着对deepseek针对性优化一下
3 个赞
现在单独设立了一个裁判llm,做了一下分离,现在效果会好一些了。![]()
3 个赞
佬,目前对我的帖子和项目有什么建议吗,感觉最近的流量比较小 ![]() 。是因为我帖子写的不好吗
。是因为我帖子写的不好吗
3 个赞
可以分享到一些社交媒体中,比如抖音小红书,或者qq群之类的,喊大家过来体验一下,如果对方觉得不错就可以请别人帮忙投投票啥的。
我觉得你这个作品是真的很好,后续迭代我也有一直在玩。期待你能够拿奖![]()
3 个赞
收到收到,感谢您的体验!您的评价真的让我很感动,我明天会试着在我们学校和抖音b站上推广一下,感谢您的建议!
3 个赞

收到(^^ゞ
3 个赞
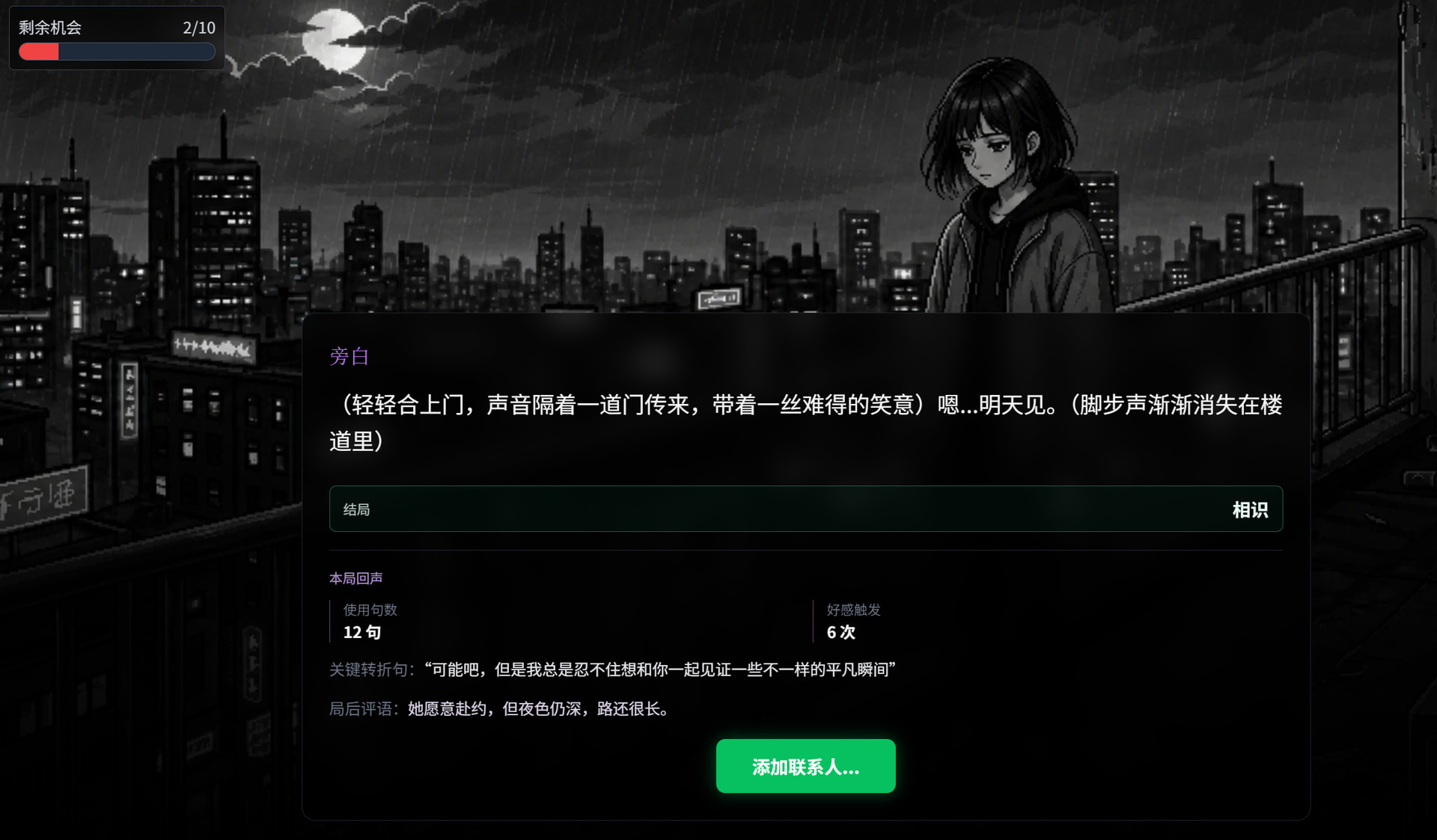
谢谢认可!您的评价让我感到我这几周的努力没有白费。《天台十句》还有很多地方在继续打磨,也欢迎你试玩后告诉我打出了什么结局,你的反馈对后续迭代很有帮助。![]()
4 个赞
刚去玩了十几分钟,第二次才打出好结局。里面那个“情绪值”的判断逻辑还挺有意思的,我好奇你是怎么写prompt让它保持连贯的?
3 个赞
谢谢试玩!“情绪值”这里我后来没有继续放在主回复 prompt 里硬判,而是拆成了两层:主 LLM 只负责写艾的自然回复;后面再接一个结构化裁判 prompt,专门根据“玩家本句 + 艾的回复 + 历史状态”输出 emotion / ai_state / affection_delta / pressure_delta / ending_type。
裁判 prompt 不直接看单句情绪,而是带上当前剩余机会、好感、已触发次数、角色状态和历史摘要;同时限制枚举值,解析失败就走保守兜底,比如 emotion=normal、不额外扣机会、不触发结局。这样主对话可以保持自然,机制判断也不会污染正文。
3 个赞
有意思,双层结构这么拆就合理多了。
3 个赞
不错不错,bgm搭配的很好,再加上ui的色彩,整体非常不错
4 个赞
感谢您的认可 ![]()
3 个赞
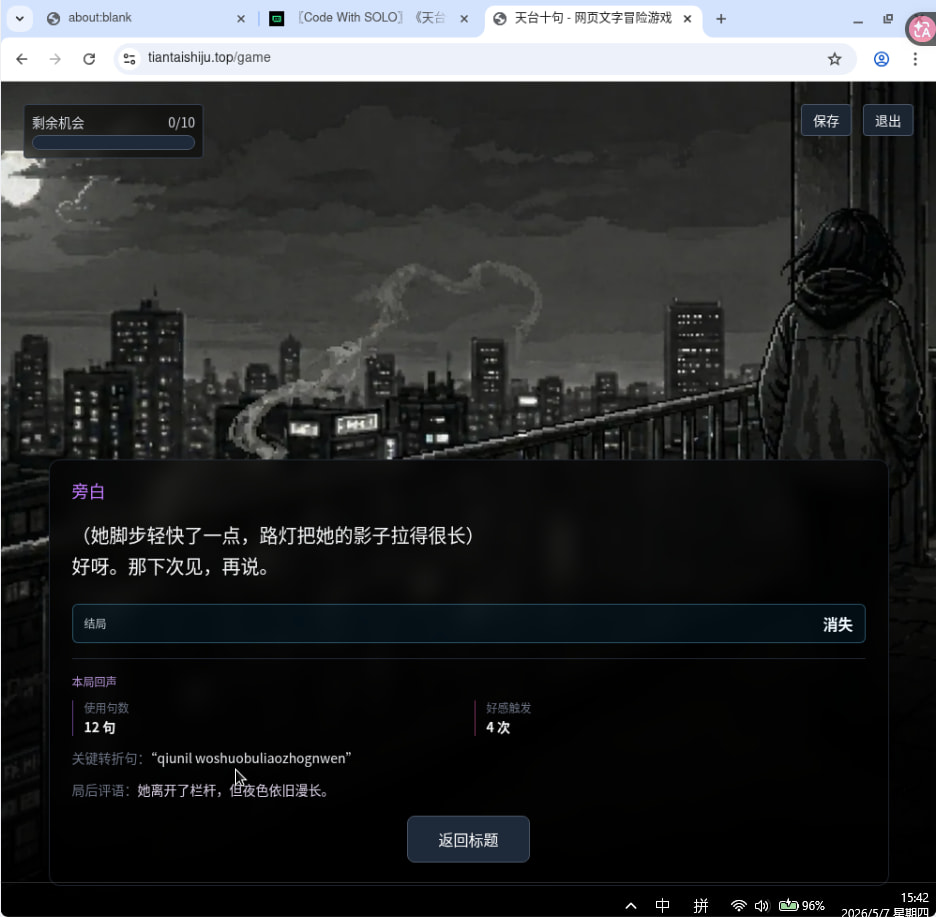
deepseek会蠢一些 ![]() 。接gpt会好很多
。接gpt会好很多
3 个赞
哈哈,我感觉 deepseek 在某些场景下也没那么离谱吧,可能你是踩到它盲区了。不过能用 SOLO 把这个项目完整跑通,还是厉害。
2 个赞