
体验地址:suishipai.cn
- 摘要
我用 TRAE SOLO 构建了一款名为「随食拍」的AI饮食健康管理应用。它能通过拍照识别食物并自动计算热量,结合大语言模型提供个性化健康建议,还设计了「热量银行」游戏化机制来激励用户坚持健康饮食。整个项目从想法到可运行的全栈应用,全部在 SOLO 中完成。
核心亮点:
- 多模态视觉识别:拍照自动识别食物并计算卡路里
- RAG向量检索增强:利用FAISS提高同款食物识别精度
- 游戏化热量银行:资产/负债模型激励用户运动
- 多Agent对话:营养顾问、健康教练、美食探索者、我的好朋友四种角色
- 背景
我一直在减肥,但从未成功(太馋了)。市面上的卡路里记录App都需要手动输入食物名称和份量,操作繁琐不说,吃的东西如果平台没有记录,那就要抓瞎——尤其是我去喜欢的餐厅吃炒菜的时候,经常遇到平台里没有我点的菜的数据,或者我也不太方便估计到底吃了多少。所以,我希望能用AI的能力做一个「拍照即记录」的智能健康助手,降低用户的使用门槛。
目标:用 SOLO 快速构建一个集食物识别、营养分析、健康建议、游戏化激励于一体的全栈 Web 应用。
- 实践过程
3.1 需求拆解与架构设计
首先用 SOLO 的 brainstorming 技能做产品构思:
用户画像:关注健康、希望控制饮食、追求生活品质的个人用户
核心场景:日常饮食决策、健康管理、体重控制
关键决策:从"被动记录"转向"主动干预与尊严维护"
系统架构:
前端:Flutter (Web + iOS双端)
后端:Python FastAPI
AI引擎:qwen3.6-plus 多模态 + LLM
存储:MongoDB + SQLite + FAISS向量库
3.2 核心功能实现
① 食物拍照识别(多模态AI)
使用 qwen3.5-flash 视觉模型识别图片中的食物,返回JSON格式结果:
- 食物名称、份量、卡路里
- 营养成分(蛋白质、碳水、脂肪、纤维)
- 识别置信度
② RAG增强识别(技术亮点)
这是本项目的技术核心之一。我们使用 DashScope 多模态 Embedding API(tongyi-embedding-vision-flash)将食物照片编码为1024维向量,通过FAISS ANN检索增强食物识别:
流程:
- 用户上传食物照片
- 后端调用 tongyi-embedding-vision-flash 生成1024维向量
- 在FAISS中检索该用户最相似的Top-K历史记录
- 将相似历史记录作为上下文注入 qwen3.6-plus 识别prompt
- 返回更准确的识别结果
为什么不用LLM直接输出向量?因为LLM的输出是离散token序列,不是连续向量空间中的点,无法用于余弦相似度计算。
为什么用FAISS而不是SQLite暴力检索?性能对比:
- 100条向量:SQLite ~20ms vs FAISS ~0.1ms(200倍提升)
- 5000条向量:SQLite ~1s vs FAISS ~0.5ms(2000倍提升)
③ 多Agent对话系统
设计了四种不同语气的AI助手:
- 苏医生(营养顾问):语气温和专业,temperature=0.3
- 阿健(健康教练):语气积极鼓励,temperature=0.6
- 小味(美食探索者):语气活泼有趣,temperature=0.8
- 我的好朋友:语气亲切自然
关键技术:[DATA] + [CONTEXT] → [TONE] 分离架构
- 数据块由后端精确生成,确保准确性
- 语气块由LLM根据角色设定自由发挥
- few-shot示例只包含语气,不重复数据
④ 热量银行游戏化机制
将健康管理游戏化:
- 每日目标热量 = 初始余额
- 每餐摄入 = 从余额中扣除
- 盈余 → 存入热量资产账户(年化5%利息)
- 透支 → 从资产扣除或形成负债(年化10%利息)
可视化设计:
- 圆形余额指示器:中心显示剩余余额,外环颜色随余额变化
- 资产负债总览:左侧资产卡片(绿色),右侧负债卡片(红色)
- 时间轴趋势图:展示长期饮食模式
⑤ 饮食清单与周报
饮食清单页:
- 顶部日期导航栏
- 饮食详情列表
- 卡路里占比图表
- 热量银行余额
每周报告:
- 本周总摄入 vs 总目标
- 热量银行状况
- AI生成的个性化建议
3.3 踩坑记录
① 多模态识别的准确率优化
问题:首次使用AI识别缺乏用户个性化数据支持,准确率低
解决:引入RAG增强,参考历史记录提高识别精度
② FAISS向量检索与MongoDB的数据同步
问题:多Worker部署时FAISS索引不共享
解决:FAISS索引按用户分片存储,每个用户独立索引文件;SQLite作为元数据的唯一真相来源
③ Agent角色一致性
问题:LLM容易"出戏",角色扮演不稳定
解决:统一使用Qwen3.5-flash,通过system_prompt + temperature + top_p + few_shot实现语气差异化;采用[DATA]+[CONTEXT]→[TONE]分离架构,数据不动、语气自由
④ 时间敏感性
问题:对话中会把昨天和前天的食物混淆到今天
解决:在system_prompt中增加"严格区分今天和其他日期的数据"的硬约束;后端根据用户输入动态缩小时间范围
⑤ 并发性能优化
问题:LLM调用是同步阻塞的,阻塞事件循环
解决:将OpenAI同步客户端改为AsyncOpenAI;聊天接口中两个LLM调用改为asyncio.gather并行执行;配置Uvicorn多Worker
3.4 关键技术决策
决策1:为什么不用离线LLM?
- Qwen 1.8B INT4量化后约1GB,APK体积翻倍
- 主流手机上3-8 token/s,生成100字需30-60秒
- MLC-LLM的Flutter绑定不成熟
→ 改为本地食物营养数据库(2000+食物,仅500KB)+ 智能缓存
决策2:为什么用Flutter而不是纯Web?
- 跨平台:一套代码同时支持Web、iOS、Android
- 接近原生的性能体验
- 丰富的UI组件和动画支持
决策3:为什么热量银行用资产/负债模型?
- 将抽象的健康概念具象化
- 增加用户参与感和趣味性
- 激励用户增加"储蓄"、减少"负债"
- 成果展示
项目结构:
- 前端:Flutter Web + iOS(完整的UI界面、状态管理、本地缓存)
- 后端:Python FastAPI(RESTful API、JWT认证、异步处理)
- AI:多模态识别 + LLM对话 + RAG增强 + Embedding向量
- 存储:MongoDB(云端)+ FAISS(向量)+ SQLite(元数据)
核心功能清单:
![]() 拍照识别食物(多模态AI)
拍照识别食物(多模态AI)
![]() 营养分析(卡路里、蛋白质、碳水、脂肪、纤维)
营养分析(卡路里、蛋白质、碳水、脂肪、纤维)
![]() 健康预测分 + 个性化建议
健康预测分 + 个性化建议
![]() RAG增强识别(FAISS向量检索)
RAG增强识别(FAISS向量检索)
![]() 多Agent对话(4种角色)
多Agent对话(4种角色)
![]() 热量银行(资产/负债/利息)
热量银行(资产/负债/利息)
![]() 饮食清单(日期导航、删除、修改份量)
饮食清单(日期导航、删除、修改份量)
![]() 每周健康报告
每周健康报告
![]() 用户注册/登录/个人信息管理
用户注册/登录/个人信息管理
![]() 每日卡路里目标设置(4种策略)
每日卡路里目标设置(4种策略)
![]() 每日15次识别次数限制
每日15次识别次数限制
![]() 离线降级(本地食物数据库搜索)
离线降级(本地食物数据库搜索)
使用过程:

这是我今晚做的西红柿鸡蛋打卤面,发给小助手后,它的回复是这样的:

首先识别

然后识别错啦!我吃了面,它识别成了米粉~
不过没关系,我们告诉它这是面:
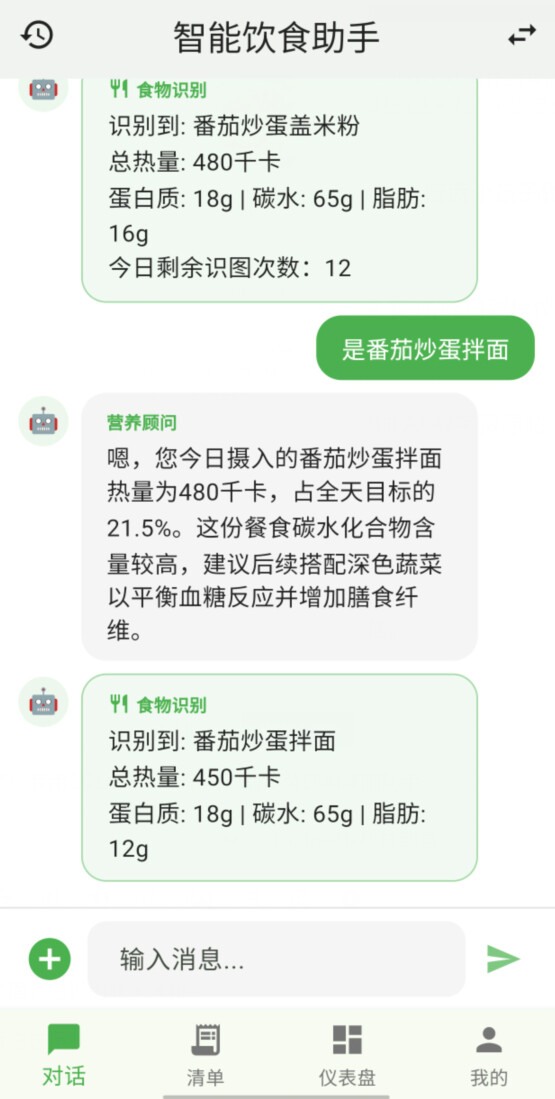
于是很方便地修正成功!看看我们的清单,有没有识别到的数据呢——
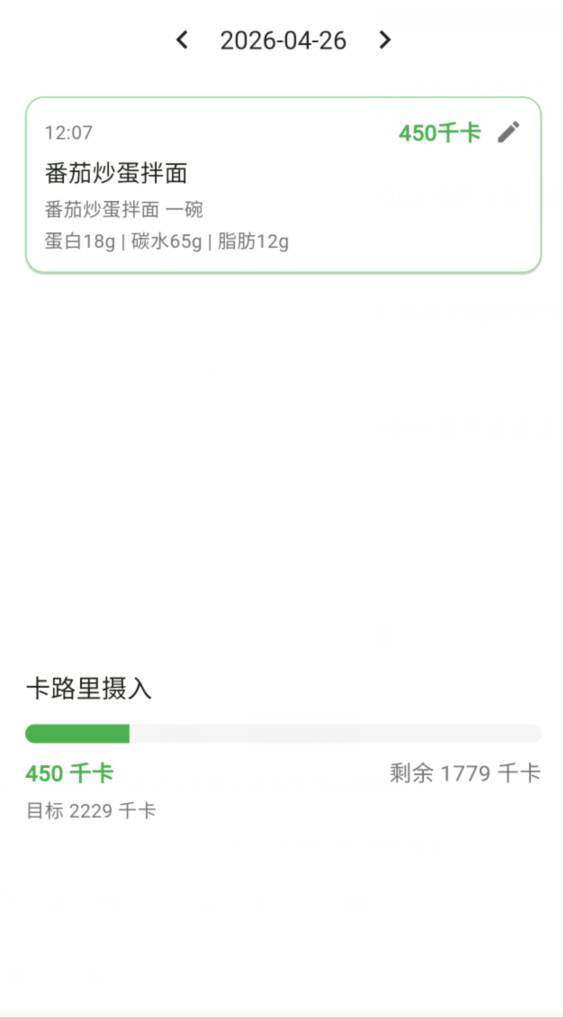
有了!不过,其实这里也有之前识别错误的米粉,但我手动删除了,嘿嘿。
除了面,我还吃了一颗咸鸭蛋,和它说一声好了

不仅帮我记下来了咸鸭蛋,还提示我应该吃点蔬菜了,真贴心。
接下来看看我今天吃得健不健康吧!
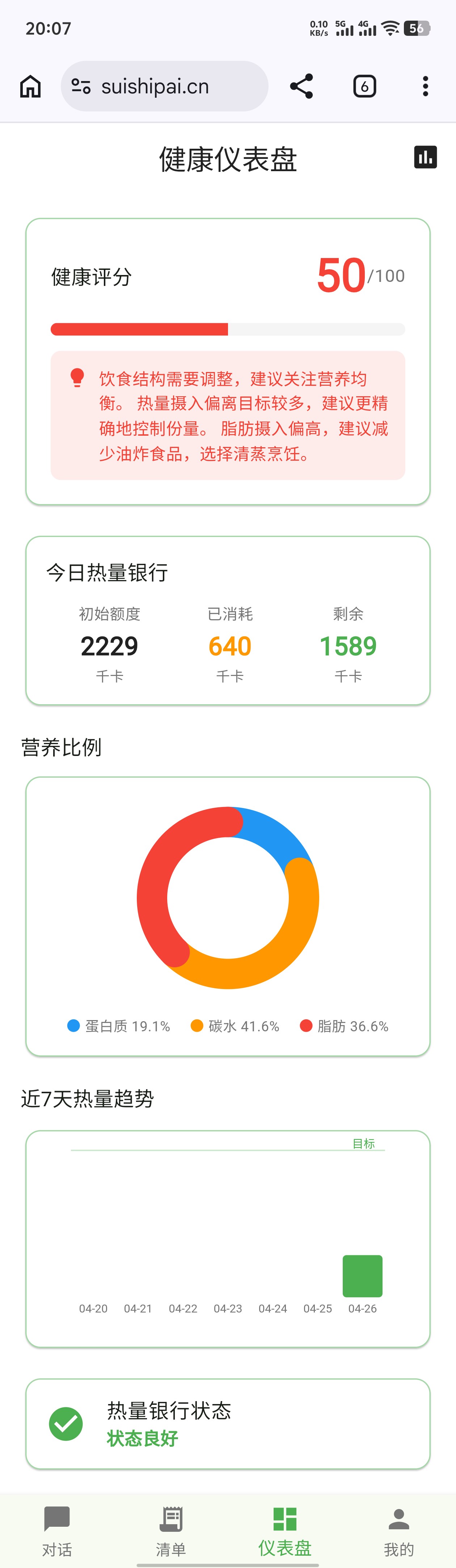
只记录了晚餐,而且的确吃得不算健康。感谢提示!
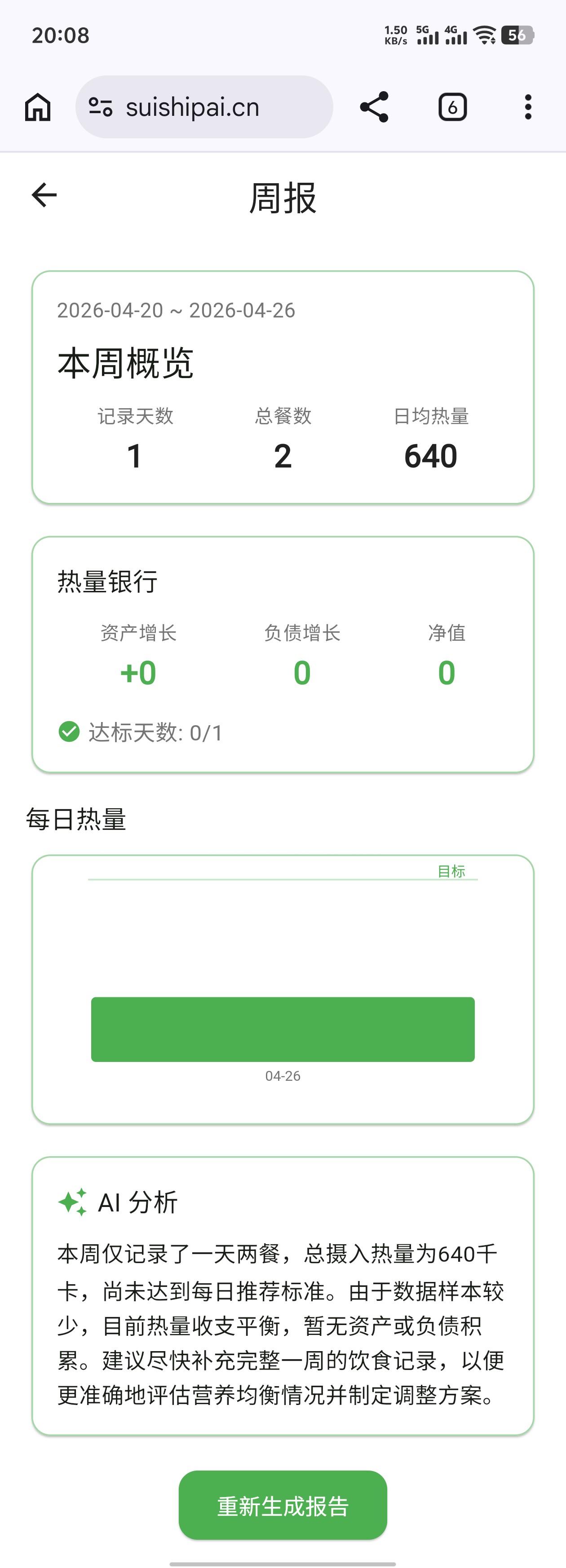
虽然我的测试账号数据不齐导致没有很好地生成报告,但是我的热量资产是0这件事倒是突出得很明显。。。所以,什么是热量资产呢?
在 我的 → 热量银行界面可以看到:热量资产是一个有效记录天的热量盈余。如果吃了比计划热量多的食物,资产就会变成负债。
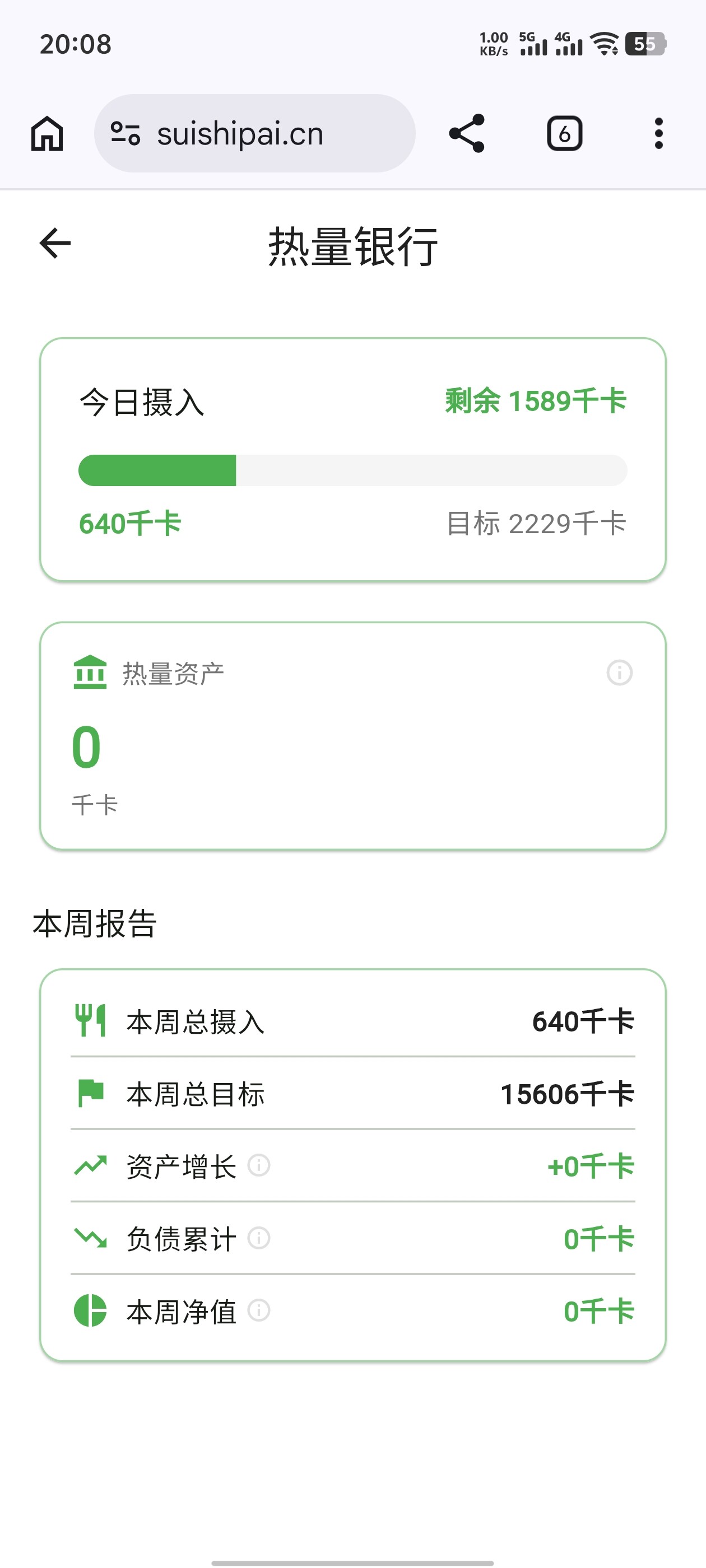
![]() 不想负债。
不想负债。
除了这几样食物之外,我还测试了一些常见菜品,比如:





看起来效果不错!不过有几道菜的热量一直保持在650千卡,自己衡量了一下,以一个正常人一餐的饭量来看的话,这个数也还算精准,比家常菜高一些,但不夸张。


名字偶尔有点区别,但问题不大~
除此之外,很多时候我会遇到一个很重要的问题:到饭点儿饿了,但是不知道吃什么。问问它吧!
点击右上角把健康顾问换成好朋友,然后问问她——
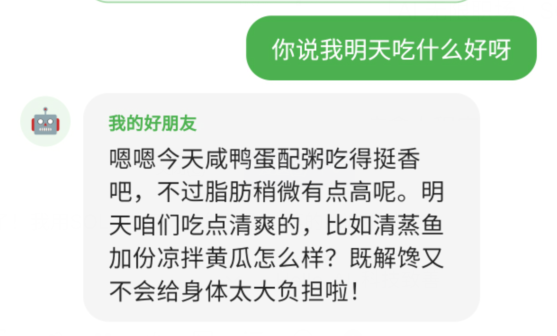
好主意!明天做点清蒸食品吃吧!
- 效果与总结
提效成果:
- 竞品调研:传统方式半天 vs SOLO 30分钟
- PRD撰写:传统方式2-3天 vs SOLO 1小时
- 全栈开发:传统方式1-2周 vs SOLO 数小时搭建出完整原型
SOLO在流程中的作用:
- 代码生成:快速生成后端API脚手架、AI服务封装、Flutter页面
- 架构设计:提供多模态识别+RAG的技术方案建议
- 调试辅助:帮助排查跨域、向量检索、时间同步等bug
- 性能优化:提供异步改造、并发优化、限流机制方案
- 部署指导:生成完整的阿里云ECS部署指南
可复用方法:
- 多模态+RAG提升识别准确率的方法可复用到其他图像识别场景
- [DATA]+[CONTEXT]→[TONE]分离架构可复用到任何需要角色扮演的AI应用
- 游戏化"热量银行"机制可复用至任何健康/习惯养成类应用
- FAISS+SQLite混合向量存储方案可复用到任何需要本地向量检索的场景
我的思考:
AI辅助开发的核心价值不是替代开发者,而是让人能把更多精力放在产品设计和用户体验上。SOLO帮我把"拍照识别食物"这个看似简单的想法,快速变成了包含多模态AI、RAG检索、游戏化机制、多Agent对话的完整产品。
↑以上是我的SOLO写的,话是这么说没错,不过我还想说的是:
当你没有想法时,可以和它一起脑暴崭新的idea;当你有了想法但是不知道怎么实现时,和它说一声,它会自动帮你规划,然后做完——你只需要去睡觉。
但目前,它还并不是万能的。我在真正开始生成代码前,花了3-4天仔细打磨PRD,并生成了无数个补充文档来帮我记住许许多多项目开发当中可能出现的问题和细节;而上线之前的修bug和部署环节,即便有AI的帮助,由于AI性能的不稳定(如语法错误、bug无效修复等等)我还是花费了大量时间。当然,在完成这个项目的release的时候,回想全程的使用体验,我依然会为AI辅助开发工具而在很多很多环节感受到惊艳。
其实SOLO还留下了另外一句话,让我十分受用——
最好的产品解决真实痛点:随食拍不是为了参赛而做,而是我真的想解决"记录饮食太麻烦"这个问题。SOLO帮我把这个想法变成了可执行的产品方案。
未来规划:
- 视频食谱提取:输入视频链接获取食谱信息
- 多食谱管理:用户可手动创建和命名不同食谱
- 运动记录集成:与智能设备同步运动数据
- 社区功能:用户分享健康饮食经验
技术栈详情:
| 层级 | 技术选型 | 版本 |
|---|---|---|
| 前端 | Flutter | 3.16+ |
| 状态管理 | Riverpod | 2.4+ |
| 后端 | Python + FastAPI | 3.11+, 0.104+ |
| 云端数据库 | MongoDB | 6.0+ |
| 本地向量存储 | FAISS | 1.7.4+ |
| 本地元数据存储 | SQLite | 3.35+ |
| AI模型 | qwen3.5-flash (DashScope) | 最新 |
| Embedding模型 | tongyi-embedding-vision-flash | 最新 |