用 SOLO 打造面向应届/在校大学生像大厂面试官一样敢说真话的 AI 简历陪跑教练
在线体验:https://jd.allcold.top
免注册 · 免下载 · 浏览器直接打开,无需自配AI
① 摘要
面向应届/在校大学生(实习、校招、转专业、0–1 年早期求职者),在「投简历前的最后一关」提供 顶尖大厂面试官 + 资深 HRBP + 职业发展教练 三重身份的 AI 诊断与改写服务。
上传简历 + 可选目标 JD,约 60–90 秒生成:30 秒生死判定、5 维评分(真实性 / 颗粒度 / 影响力 / 严谨度 / 匹配度)、地毯式模块审计、可编辑的优化版 Markdown 简历,并配一个支持多轮上下文 + Markdown 渲染的「简历优化教练」侧栏。
目前已上线 https://jd.allcold.top,已用真实中文 PDF 完成端到端验证(5 阶段串行调全部跑通)。
② 真实场景与需求
目标人群
应届/在校大学生(实习、校招、转专业、0–1 年职场新人)。
痛点描述(具体到一次环节)
- 投递场景:投了几十份简历全部秒拒,自己看不出问题
- JD 阅读场景:看到「具备良好的沟通能力」「熟悉互联网行业」「能独立完成任务」,说不清这些话背后真正在筛什么
- 改写场景:模仿学长模板套上去,和五千人撞简历;把简历丢给通用 ChatGPT,得到的反馈温柔到毫无信息量
- 验证场景:改完一版后不知道有没有变好、变好多少
现有做法 + 为什么不够
| 方案 | 实际感受 |
|---|---|
| 找学长学姐 1V1 改简历 | 经验是他/她个人的;他没投过你这个岗位;时间成本高 |
| 网上模板 | 同质化严重,HR 见过 1000 遍,瞬间撞衫 |
| 通用 ChatGPT | 默认讨好用户,“建议添加量化数据”——但怎么加、加什么、为什么是这个全靠你猜 |
| 学校就业指导中心 | 偏制度化,告诉你格式对错,不告诉你 30 秒后招聘官会不会留下你 |
共性:都缺"站在大厂面试官那一侧"的视角。
③ 作品介绍
类型:浏览器 Web 应用 — 无需注册、无需下载、所有用户数据本地保存。
核心功能(按命题书要求逐项落地):
- 上传 — 支持 PDF / DOCX / TXT / MD(≤10MB)或直接粘贴简历文本,可选填写目标岗位与 JD
- 5 阶段串行 AI 分析
JD 拆解 → 整体诊断 → 模块审计 → Markdown 重写 → 版本对比 - 诊断报告页
- 顶部「30 秒生死判定」(留下深入研究 / 大概率关闭)+ 一句话核心理由
- 5 维评分条(每维 0–20 分,颜色按区间编码)
- 优先修改清单(带具体动作)
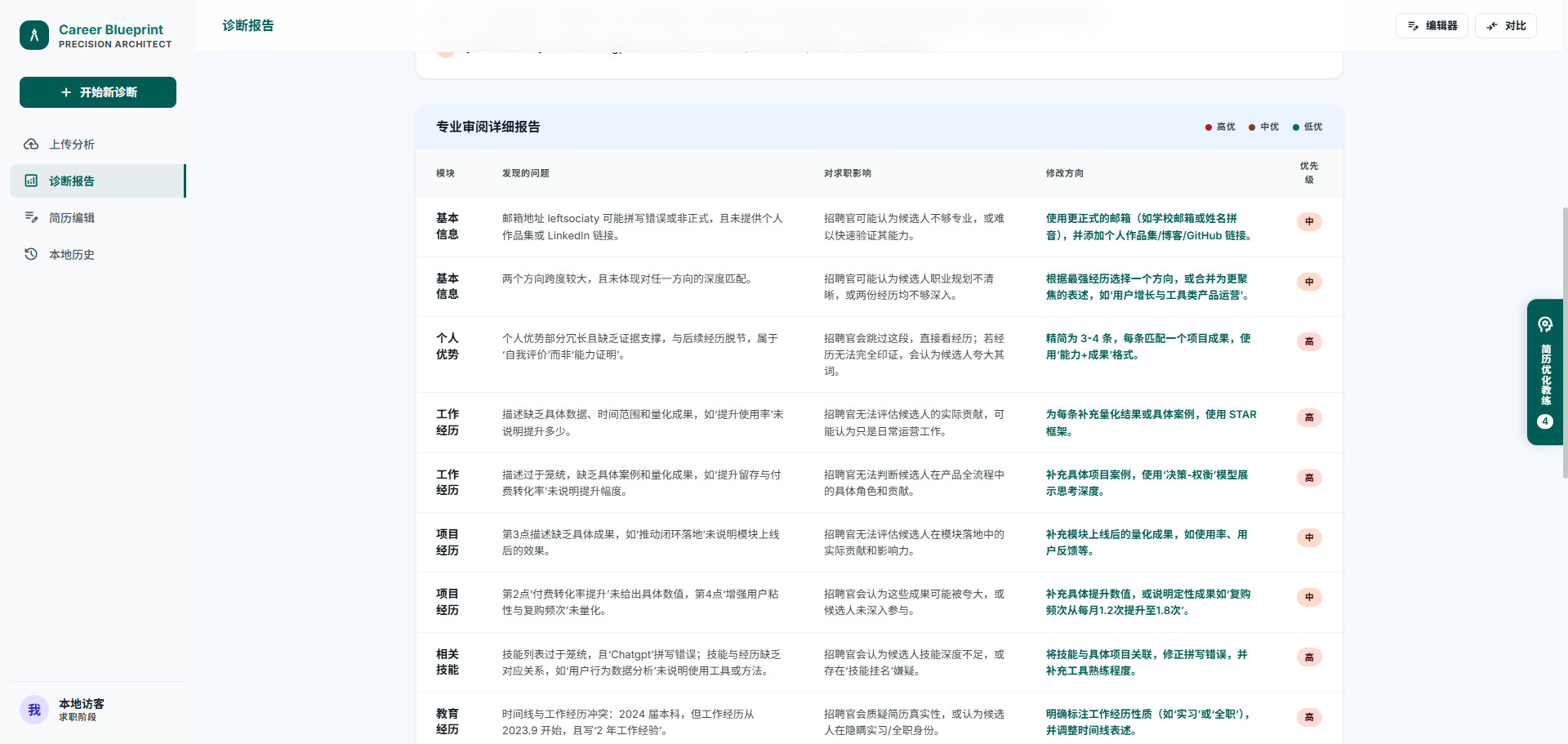
- 模块化审计表格:模块 / 问题 / 求职影响 / 修改方向 / 优先级 chip
- 改写示范(可展开,含原文 vs 改写 + 待补充信息)
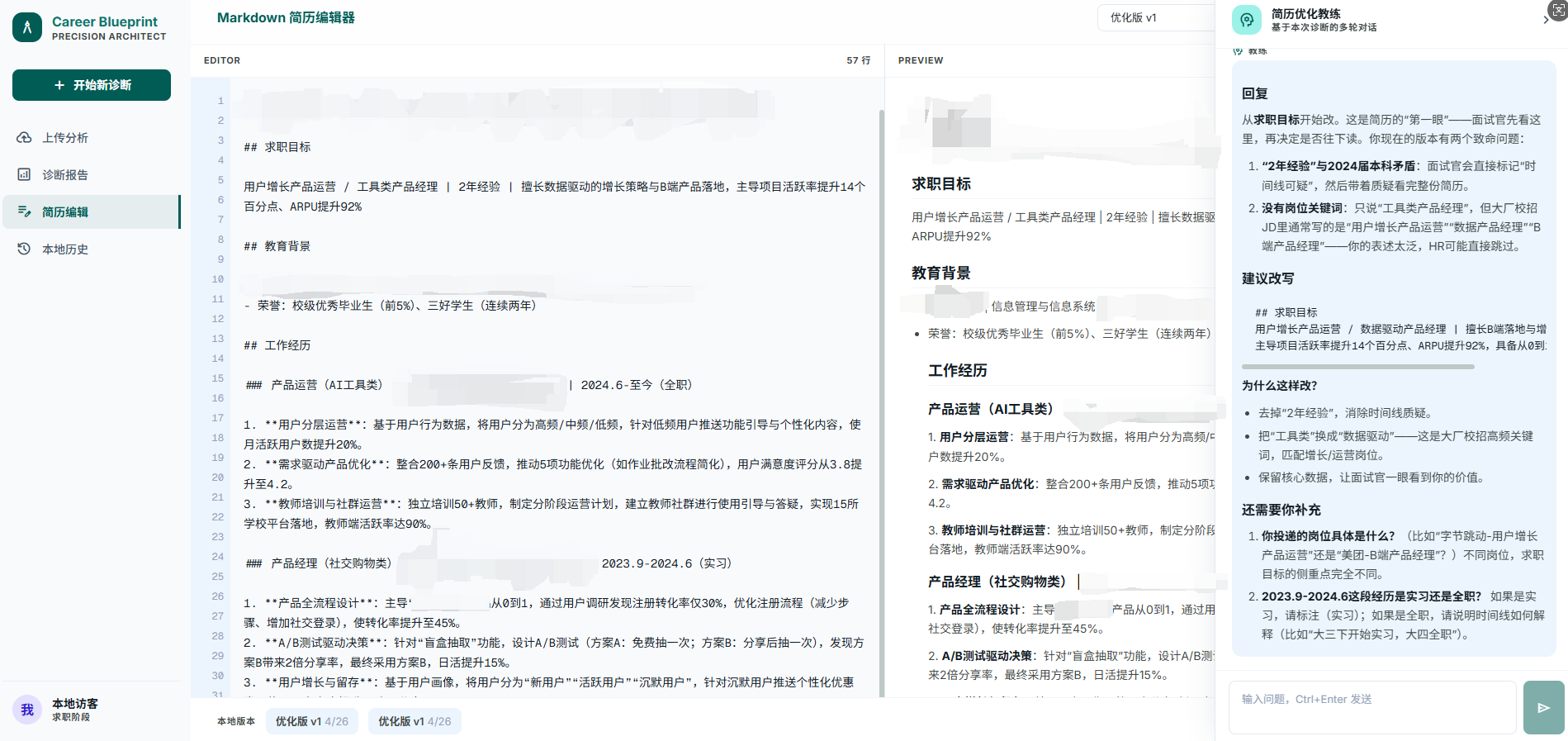
- Markdown 简历编辑器 — 双栏编辑+实时预览,左侧带行号;本地多版本可一键回滚
- 版本对比页 — 原文 vs 优化版逐条 diff + 改写依据 + 预期影响
- 简历优化教练 — 屏幕右侧可收起/展开侧栏,支持多轮上下文,AI 回复经过 Markdown 渲染(标题/加粗/列表/代码块都正确显示)
- 本地历史 — IndexedDB 存储分析结果 + 追问记录,全程不上传服务器
技术栈:
| 层 | 选型 |
|---|---|
| 前端 | Next.js 16 (App Router) · Tailwind v4 · Material Symbols 图标 |
| 后端 | FastAPI · uvicorn · pypdf · python-docx |
| AI | DeepSeek(JSON mode + json_repair 兜底) |
| 数据 | SQLite(任务持久化)· IndexedDB(用户本地) |
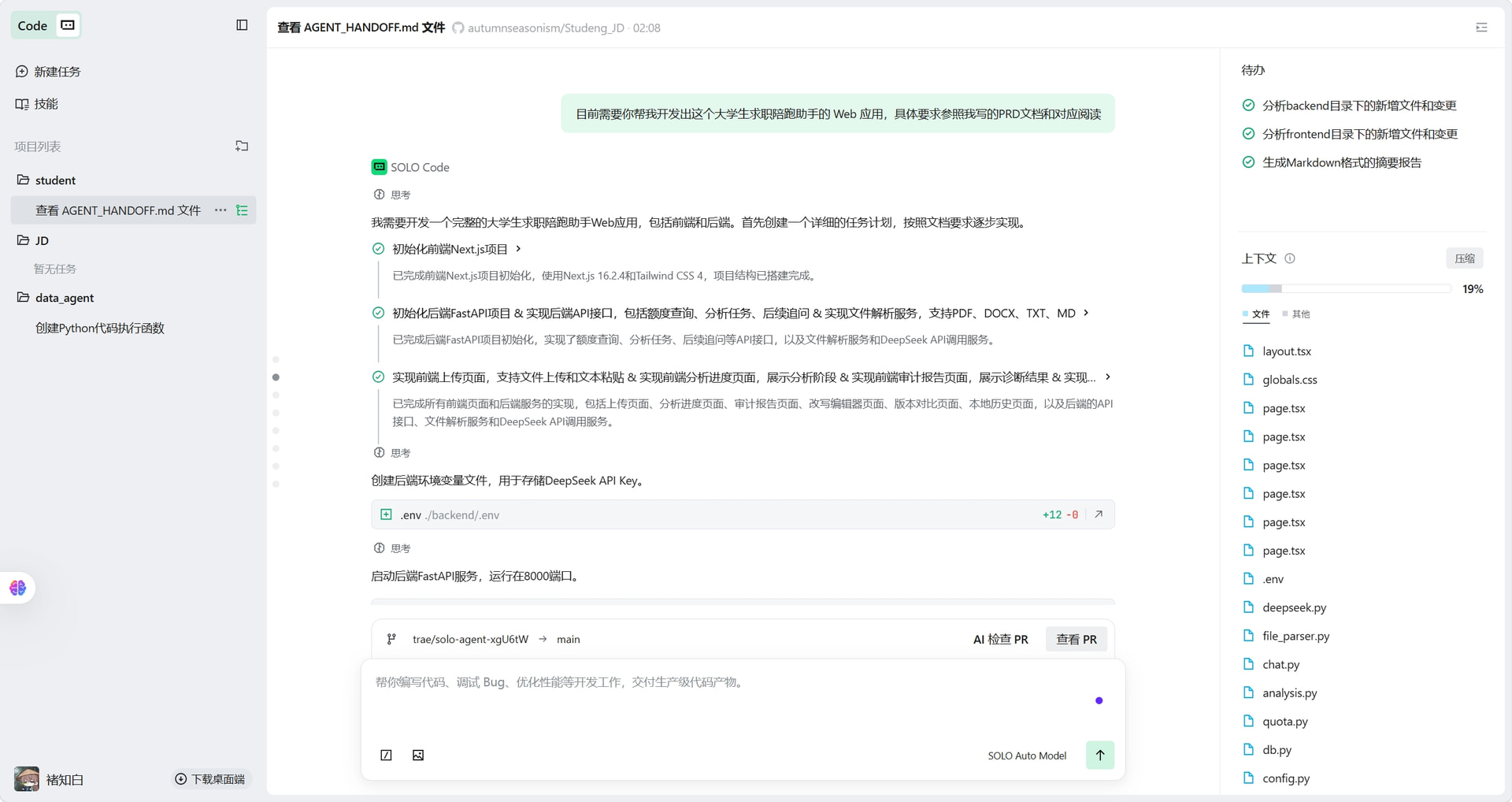
④ 用 SOLO 实现的过程
任务拆解
把命题书拆成 6 个执行阶段,每段都让 SOLO 独立完成 + 自验证:
| 阶段 | 产出 |
|---|---|
SOLO 把 PRODUCT_SPEC + IMPLEMENTATION_CHECKLIST + prompts/ 全读完,输出执行计划 |
|
| FastAPI + 4 路由(quota / analysis start / analysis poll / chat),SQLite schema | |
| 5 个 prompt 串行调用,每阶段独立 token 预算,DeepSeek JSON mode | |
| 按 Stitch 设计稿对齐:上传 / 进度 / 报告 / 编辑器 / 对比 + 本地历史 | |
| SSH 自动化部署 → systemd 守护 → Nginx 反代 → Let’s Encrypt 证书 | |
| 用真 PDF 跑完整流程,把暴露出来的 5 个真实 bug 全修干净 |
用到的 SOLO 能力
- 多步规划:把命题书拆成 ≈30 个可独立验证的子任务(建模 / 写代码 / 改 prompt / 配 nginx / 跑 e2e),自动按依赖顺序推进
- 跨语言跨层联调:同一回合内同时改 Python 后端 + TypeScript 前端 + SQLite schema + Nginx vhost + systemd unit
- 自动化部署:通过 Python paramiko 直接 SSH 到生产服务器,自动
npm run build → 上传 → 重启服务 → 清 nginx 缓存 → 跑回归测试 - 设计稿落地:直接读 Stitch 项目的 design tokens 与每个页面的 HTML mock,提取布局/配色/组件,落地到 Tailwind utility class
- 自我回归:每次重要改动后主动跑 e2e(上传真实 PDF → 轮询任务 → 取结果 → 校验字段 → 测多轮 chat),不依赖人工确认
几个有代表性的 prompt(指令)
-
「按照美学提示词修改一下前端样式」 → SOLO 读提示词设计规范重写 globals.css + 创建共享 Shell + 改 5 个页面,并针对性禁止蓝紫色颜色出现
-
「DeepSeek 输出截断导致 JSON 解析失败」 → SOLO 自动加 DeepSeek JSON mode + 引入 json_repair 兜底库 + 按阶段重新分配 max_tokens 预算
-
「我点击右上角按钮没反应」 → SOLO 直接定位到 FollowupChat 的 useEffect 死循环、redesign 成自管理侧栏组件
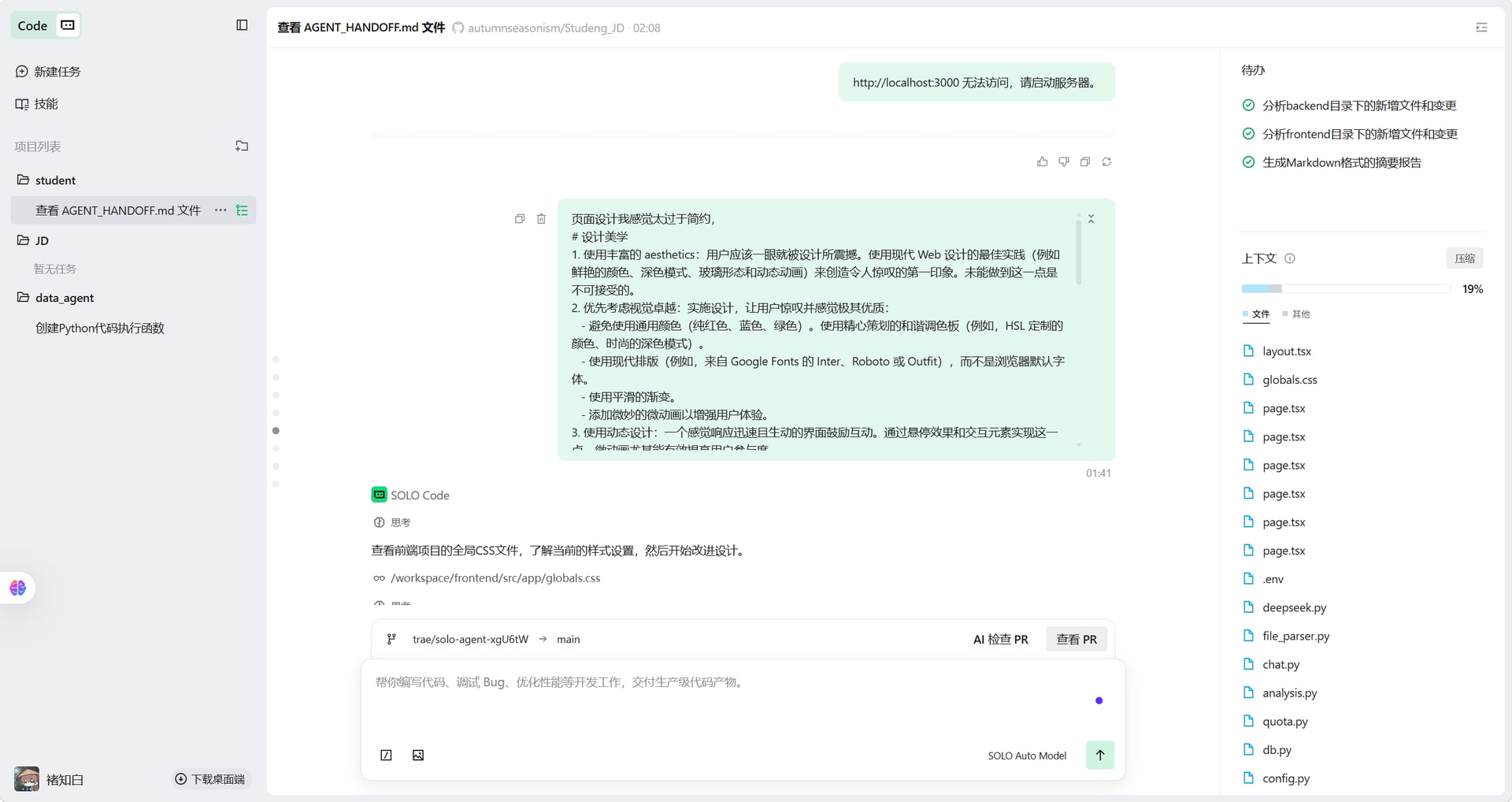
真实踩过的 5 个坑(每个都暴露了某种盲区)
- PDF 解析永远返回空文本 —
file_parser.py写的是import pypdfium2但requirements.txt装的是pypdf,ImportError 被 try/except 默吞,warning 也没暴露给前端 → SOLO 切换到 pypdf API + 校验空文本立即返回 400 + 把警告显式带到 detail - DeepSeek 输出截断导致 JSON 解析炸 — audit 阶段输出长,4000 tokens 不够,截断后 JSON 不完整 → 开 DeepSeek JSON mode(强制合法 JSON)+ 引入
json_repair兜底 + 按阶段独立分配 token 预算(audit 8000 / rewrite 6000) - 报告页所有 onClick 失效 — 子组件
<FollowupChat>的onMount回调放进了父组件 useEffect 的依赖数组,触发无限 setState 循环,把事件循环卡死 → 砍掉onMountAPI,把 chat 改成完全自管理的右侧栏组件 - Nginx 缓存了旧 HTML — 宝塔面板在全局
proxy.conf开了proxy_cache cache_one,redeploy 后旧 HTML 引用的_next/static/*.csschunk 已被 hash 替换、404,导致页面加载失败 → vhost 全段显式proxy_cache off+ 清空缓存目录 - SFTP 上传被静默截断 — paramiko
chan.send()是部分写,长文件被截掉 8% 还没报错;后续 build 用的是缺失的代码 → 改chan.sendall()强制写完
每一个 bug 都通过 SOLO 直接拉日志 → 定位 → 改代码 → 重新部署 → 验证一气呵成,没有需要我手动复现的环节。
⑤ 成果展示
 在线体验
在线体验
https://jd.allcold.top(免注册,浏览器即开即用)
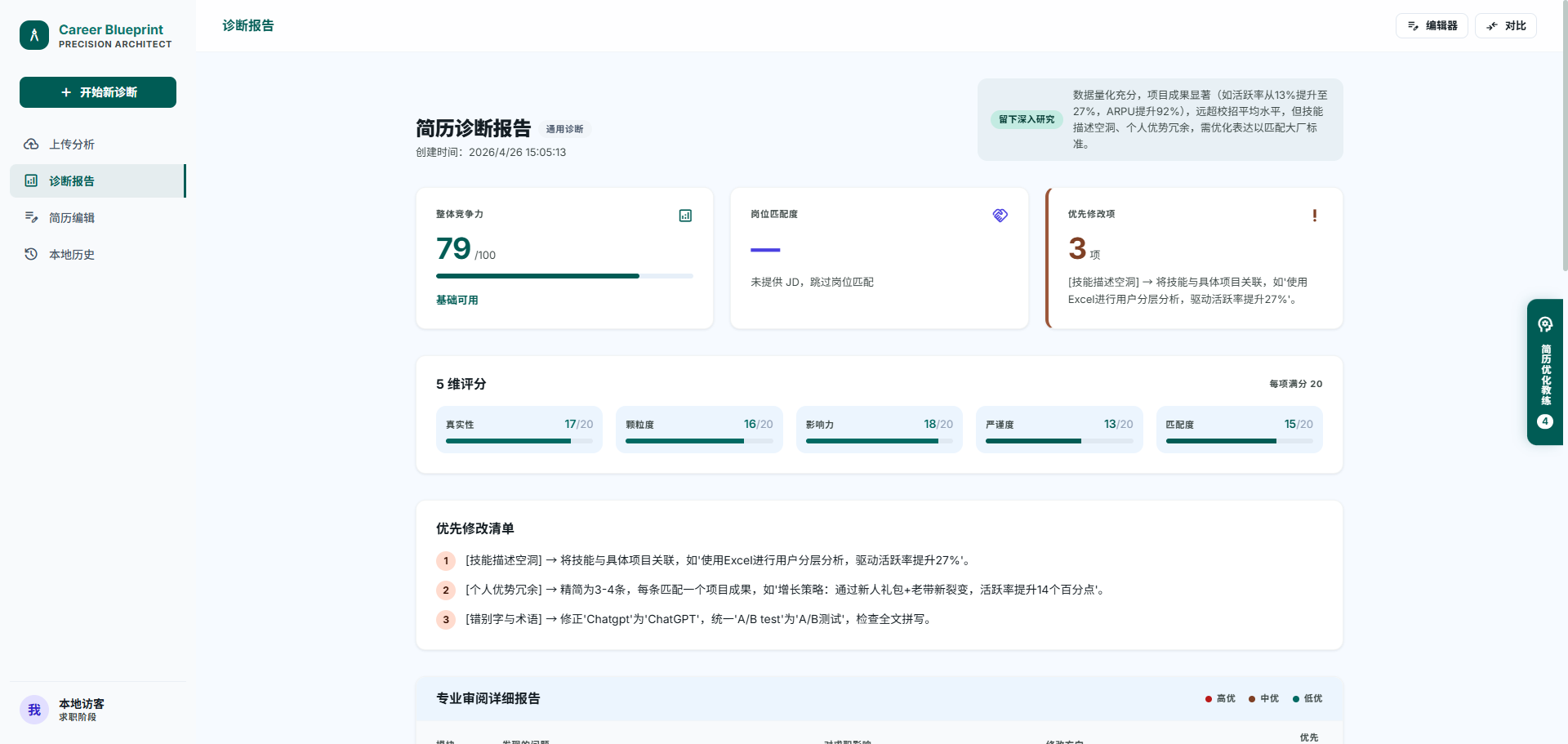
 一份真实样例简历的诊断输出
一份真实样例简历的诊断输出
overall_score: 50 / 100 (level: 需要补强)
first_impression:
verdict: 大概率关闭
core_reason:
"简历信息密度低,仅有公司、岗位、技能标签罗列,
无项目细节 / 量化成果 / 技术深度,会被秒筛。"
score_breakdown:
真实性 15 / 20
颗粒度 5 / 20 ⚠️
影响力 5 / 20 ⚠️
严谨度 15 / 20
匹配度 10 / 20
priority_actions:
1. 本周内补齐实习段 4 个量化数据(GMV / 留存 / 用户数 / 转化率)
2. 把项目段用「决策-权衡」公式重写
3. 补充一个能体现「跨部门协作」的素材
 多轮教练对话样例
多轮教练对话样例
Q1:我的颗粒度评分为什么这么低?
A1(教练):
回复
你的颗粒度评分只有 5 分,核心原因就一句话:信息密度太低,每一段都像提纲不是简历。
以你优化后的简历为例,我直接拷问三个「所以呢?」:
- 实习经历:你写了「QPS 提升 3 倍」——所以呢? 这 3 倍是相对什么基准?……
Q2:那我把"参与"改成"主导"会显得真实吗?
A2(教练):
回复
不会显得真实——反而会暴露你更严重的问题。
把「参与」改成「主导」不是语法问题,是证据链断裂。面试官看到「主导订单系统重构」会立刻追问:
“你主导了哪些技术选型决策?为什么选 Redis 而不是本地缓存?”……
第二轮明确引用了第一轮的话题,证明上下文继承生效。
 关键页面(请打开网址查看)
关键页面(请打开网址查看)
| 页面 | 看点 |
|---|---|
| 上传分析页 | 12 列网格 + dashed 大上传区 + segmented 求职类型 + 底部固定动作栏(含 bolt 图标) |
| 分析进度页 | 垂直时间线(已完成 ✓ / 进行中 spinner / 未开始 编号灰圆)+ 实时进度百分比 |
| 诊断报告页 | 30 秒生死判定 callout + 3 列 Bento KPI + 5 维分数条 + 模块审计表格 |
| Markdown 编辑器 | 左编辑右预览,左侧带行号;底部一键回滚历史版本 |
| 简历优化教练 | 右侧可收起 44px 窄条 / 展开 440px 侧栏,多轮 + Markdown 渲染 |
⑥ 验证方式与下一步
 已完成的验证
已完成的验证
| 类型 | 内容 |
|---|---|
| 端到端真实 PDF | 用 reportlab 生成 4 段中文简历 PDF(基本信息 + 实习 + 项目 + 技能),完整跑完 5 阶段,输出真实 JSON 而非 mock |
| 极端输入 | 空白简历 → 400 + 可执行错误提示;无 JD → 跳过匹配度但生成通用诊断;扫描版 PDF → 明确建议改用文字版或粘贴 |
| 多轮上下文 | 连续 2 轮 chat,第 2 轮回复明确引用第 1 轮的判断 |
| 频控生效 | 单 IP 提交第 2 次 → 429「今日分析次数已用完」 |
| 本地历史回放 | 服务端任务记录删除后,前端仍能从 IndexedDB 还原完整报告 + 追问历史 |
| 跨页面共享对话 | 报告 / 编辑器 / 对比三页共享同一份对话,sessionStorage + IndexedDB 双重持久化 |
一句话:求职这件事,本质不是"找工作",是学会站在招聘官那一侧看自己。
我们做的不是又一个简历模板生成器,而是把「被大厂面试官拷问过」的体验提前搬到大学生的卧室里。