 摘要
摘要
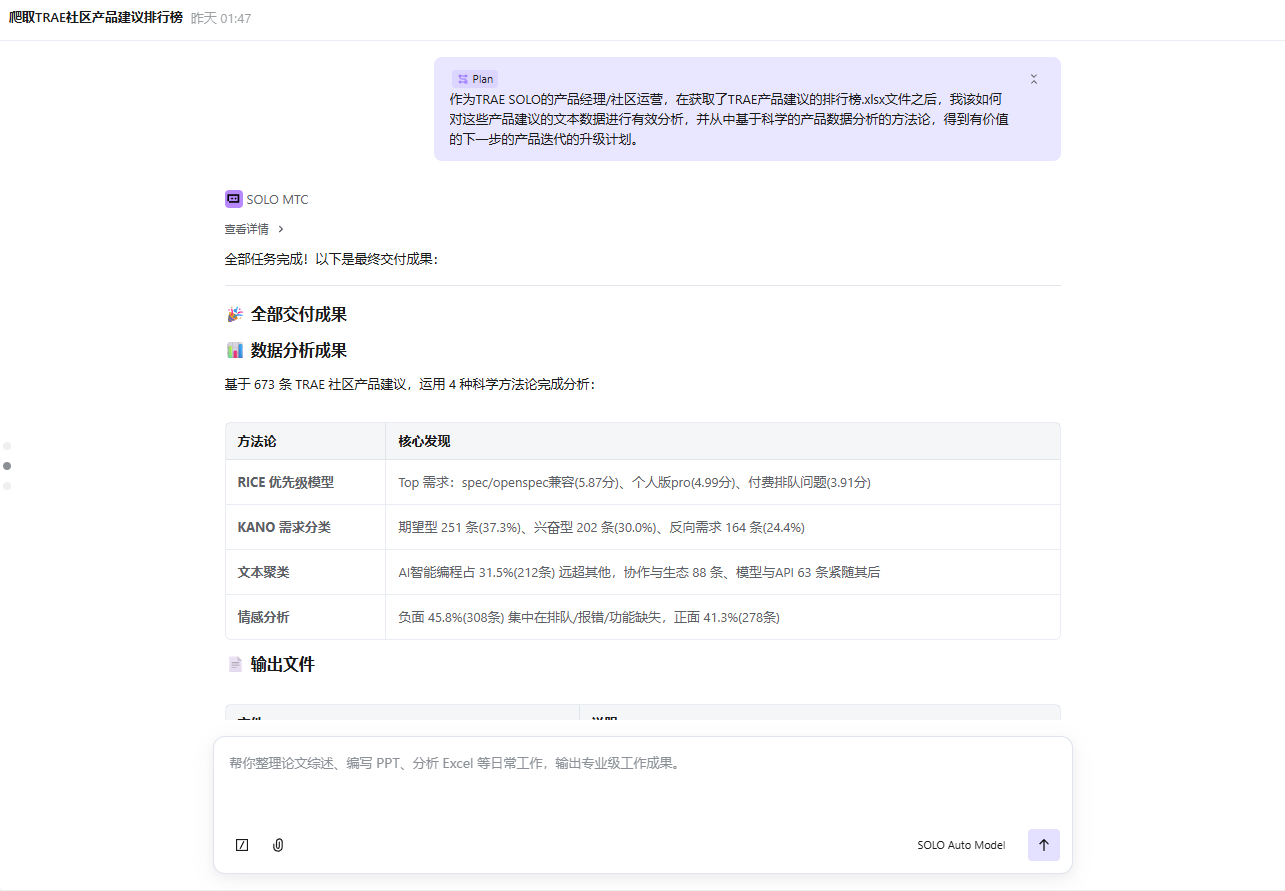
用 TRAE SOLO 完成了从数据采集到深度分析再到多格式报告输出的全链路工作。爬取了 TRAE 中文社区 673 条产品建议话题,运用 RICE 优先级模型、KANO 需求分类、SnowNLP 情感分析、jieba 文本聚类 4 种科学方法论进行深度分析,最终输出 Word 分析报告(9 章)、PPT 汇报演示文稿(18 页)、Excel 数据看板(6 个 Sheet)三份专业交付物。
成品三件套: 夸克网盘分享
 背景
背景
【假装】我是一名产品经理/社区运营,日常工作中需要定期分析 TRAE 社区用户的产品反馈,以数据驱动产品迭代决策。
面临的挑战:
-
社区积累了大量用户反馈帖子,手动阅读效率极低
-
需要科学的方法论(而非拍脑袋)来排列需求优先级
-
分析结果需要以多种格式呈现给不同受众(报告给管理层、PPT 给团队、Excel 给数据团队)
-
传统方式需要数据工程师 + 分析师 + 报告撰写多人协作,周期 1-2 周
我的目标: 用 TRAE SOLO 独立完成「数据爬取 → 科学分析 → 可视化 → 多格式报告输出」的全链路工作。
 实践过程
实践过程
Step 1:数据爬取 — 发现 Discourse API 的秘密
任务拆解: 爬取 TRAE 论坛产品建议分类下的全量排行榜话题及详情。
关键发现: TRAE 中文社区(forum.trae.cn)基于 Discourse 开源论坛平台构建。Discourse 有一个隐藏特性 —— 在任何页面 URL 后加 .json 即可获取结构化 JSON 数据!
我让 SOLO 帮我:
-
先用 WebFetch 访问
https://forum.trae.cn/c/8-category/8/l/top,分析页面结构 -
验证 JSON API 端点
https://forum.trae.cn/c/8-category/8/l/top.json是否可用 -
编写 Python 爬虫脚本,自动分页获取全量数据
关键 Prompt:
“帮我研究如何爬取 TRAE 中文社区的产品建议话题排行榜 https://forum.trae.cn/c/8-category/8/l/top ,使用 Discourse JSON API,输出为 Excel 格式,包含全量数据和话题详情”
爬取结果:
-
自动翻页 14 页,获取 673 条产品建议话题
-
每条话题包含:标题、票数、回复数、浏览量、标签、发帖人、正文内容、创建时间等完整字段
-
输出为格式化的 Excel 文件(3 个 Sheet:排行榜概览、话题详情、统计摘要)
踩坑记录:
-
报告分析阶段只对第一个sheet的话题标题做了分析,而没有对第二个sheet的内容正文进行分析。
-
Discourse API 的
tags字段有时返回字典列表(dict)而非字符串列表,需要做类型判断处理 -
时间戳字段混合了 ISO 8601 字符串和 Unix 时间戳两种格式,需要统一转换
-
每个话题的详情需要单独请求
/t/{topic_id}.json,673 条话题需要控制请求频率(1-3 秒间隔)避免被限流
Step 2:科学分析 — 4 种方法论并行
任务拆解: 对 673 条产品建议进行多维度科学分析。
我让 SOLO 设计了完整的分析框架,运用 4 种产品数据分析方法论:
 方法一:RICE 优先级模型
方法一:RICE 优先级模型
RICE = (Reach × Impact × Confidence) / Effort
由于社区数据无法直接获取真实业务指标,SOLO 巧妙地构建了代理变量:
| 维度 | 代理变量 | 逻辑 |
|---|---|---|
| Reach(覆盖用户数) | 浏览量 | 浏览量越高 = 被越多用户关注 |
| Impact(影响深度) | 回复数×2 + 票数 | 回复代表深度讨论,票数代表认可度 |
| Confidence(置信度) | 参与率 = (票+回复)/浏览 | 高参与率 = 用户真正关心 |
| Effort(实现难度) | 主题预设难度 | AI/协作类需求工程量更大 |
 方法二:KANO 需求分类
方法二:KANO 需求分类
采用改良版 KANO 模型(基于社区数据特点适配):
-
基本型需求:高关注度 + 负面情感 → 不解决会严重不满
-
期望型需求:高关注度 + 正面/中性 → 越做越好
-
兴奋型需求:低关注度但描述创新功能 → 超出预期的惊喜
-
无差异型需求:低关注度 + 低讨论度 → 暂不优先
 方法三:jieba 文本聚类
方法三:jieba 文本聚类
定义了 12 类需求主题分类体系(AI 智能编程、编辑器体验、模型与 API、协作与生态等),通过 jieba 关键词匹配将 673 条话题自动归类。
 方法四:SnowNLP 情感分析
方法四:SnowNLP 情感分析
对每条话题的正文进行情感打分(0-1),>0.6 正面、<0.4 负面、0.4-0.6 中性。
Step 3:可视化 — 8 张专业图表
用 matplotlib 生成 8 张分析图表(300 DPI,TRAE 品牌色系):
| 图表 | 类型 | 展示内容 |
|---|---|---|
| 需求主题分布 | 饼图 | 12 类主题的占比 |
| RICE Top20 | 水平条形图 | 优先级最高的 20 个需求 |
| KANO 分类分布 | 堆叠条形图 | 五类需求的数量对比 |
| 情感分析分布 | 环形图 | 正面/负面/中性占比 |
| 月度需求趋势 | 折线图 | 3 个月的话题增长趋势 |
| 标签热力图 | 热力图 | 标签 × 主题的交叉分布 |
| 票数 vs 回复 | 散点图 | 参与度的二维分布 |
| 迭代路线图 | 甘特图 | P0-P3 四阶段规划 |
Step 4:多格式报告输出 — 一份数据,三种呈现
任务拆解: 将分析结果输出为 Word + PPT + Excel 三种格式,满足不同受众需求。
SOLO 分别生成了:
![]() Word 分析报告(9 章,约 15 页)
Word 分析报告(9 章,约 15 页)
-
封面 → 执行摘要 → 方法论 → 主题分析 → 优先级排序 → KANO 分类 → 情感分析 → 趋势分析 → 迭代路线图 → 附录
-
内嵌 8 张图表、7 个数据表格
![]() PPT 汇报演示文稿(18 页)【Failed】
PPT 汇报演示文稿(18 页)【Failed】
-
封面 → 目录 → 7 个章节(章节页 + 内容页交替)→ 结尾
-
品牌色系设计,KPI 大数字卡片 + 图表 + 表格
![]() Excel 数据看板(6 个 Sheet)
Excel 数据看板(6 个 Sheet)
-
KPI 总览、需求主题分析、RICE 优先级排名、KANO 分类明细、情感分析、月度趋势
-
全部使用 Excel 公式(非硬编码),支持动态更新
踩坑记录:
-
PPT 生成时,自定义的虚拟节点容器系统(Container System)与 pptxgenjs 内部序列化不兼容,导致所有幻灯片内容丢失。最终改用原生 API 直接调用才解决【不过依然效果不佳】
-
Word 文档的 CJK 字体需要同时配置 ascii、hAnsi、eastAsia、cs 四个字体槽位,否则中文会显示为方框
-
Excel 公式需要用 recalc.py 验证,确保 100% 可计算
 成果展示
成果展示
核心数据发现
![]() 发现一:AI 智能编程是用户最关注的领域
发现一:AI 智能编程是用户最关注的领域
-
占比 31.5%(212 条),远超其他类别
-
反映用户对 AI 辅助编程功能的高度期待
![]() 发现二:负面情绪集中在三个痛点
发现二:负面情绪集中在三个痛点
-
负面情感占比 45.8%(308 条)
-
排队等待、模型报错、功能缺失是三大负面热点
![]() 发现三:用户强烈要求开放生态
发现三:用户强烈要求开放生态
-
多个「自定义模型接入」「第三方 API」相关话题进入 RICE Top20
-
反映开放生态的战略重要性
![]() 发现四:期望型 + 兴奋型需求占 67.4%
发现四:期望型 + 兴奋型需求占 67.4%
- 用户既关注基础功能完善(期望型 251 条),也期待创新特性(兴奋型 202 条)
![]() 发现五:需求增长迅猛
发现五:需求增长迅猛
- 3 月仅 249 条,4 月飙升至 423 条,月增长 70%
产品迭代路线图建议
| 阶段 | 优先级 | 重点方向 |
|---|---|---|
| P0 立即处理 | 性能与稳定性(排队/卡顿)+ 模型与 API(自定义模型接入) | |
| P1 短期优化 | 快捷键与效率 + 终端与命令行体验 | |
| P2 中期规划 | 多平台适配(Linux/ARM/鸿蒙)+ AI 智能编程增强 | |
| P3 长期探索 | 编辑器体验优化 + 创新功能探索 |
交付物清单
| 文件 | 说明 |
|---|---|
TRAE产品建议排行榜.xlsx |
673 条产品建议原始数据(3 个 Sheet) |
TRAE_SOLO_产品建议数据看板.xlsx |
数据分析看板(6 个 Sheet,104 个公式) |
TRAE_SOLO_产品建议分析报告.docx |
完整分析报告(9 章,8 张图表) |
TRAE_SOLO_产品建议分析汇报.pptx |
汇报演示文稿(18 页) |
trae_forum_scraper.py |
可复用的论坛爬虫脚本 |
analyze_trae.py |
可复用的数据分析脚本 |
 效果与总结
效果与总结
提效数据
-
传统方式:需要数据工程师爬取(2-3 天)+ 数据分析师建模(3-5 天)+ 报告撰写(2-3 天)= 约 1-2 周
-
SOLO 辅助:全链路独立完成,从需求提出到三份交付物输出 = 约 1 天
-
提效约 10 倍
SOLO 在流程中的核心作用
-
技术调研:快速发现 Discourse JSON API,省去大量研究时间
-
代码生成:自动生成爬虫脚本和分析脚本,无需手动编写
-
方案设计:主动提出 RICE + KANO + 情感分析 + 文本聚类的组合方法论
-
多格式输出:同时生成 Word/PPT/Excel 三种格式,满足不同场景需求
-
问题排查:遇到 tags 字段类型错误、PPT 兼容性等问题时快速定位并修复
可复用的方法
-
Discourse 论坛爬取框架:
trae_forum_scraper.py可直接复用于任何 Discourse 论坛 -
产品反馈分析框架:RICE + KANO + 情感分析 + 文本聚类的组合方法论,适用于任何产品的用户反馈分析
-
全链路分析流程:数据采集 → 清洗 → 分析 → 可视化 → 多格式报告输出的 SOP