① 摘要
相信所有刚刚参建工作的人,在第一次看到岗位JD的时候,都免不了一头雾水,抓不住重点。难免怀疑自己的技术能力是否匹配岗位需求。
本系统面向应届毕业生群体,在求职过程中面对充满“黑话”和虚词的招聘描述(JD)时,提供一键“翻译”成大白话的真实工作内容解读服务,并自动生成针对性的面试准备清单与能力补齐计划。目前通过模拟测试验证,系统能准确识别并翻译常见的互联网黑话(如“私域流量池”“闭环转化”“主人翁意识”等),生成结构化的日常任务拆解(含时间占比)、隐藏门槛提示、避坑预警以及30天分阶段行动清单。
② 真实场景与需求
目标人群:应届毕业生(大三、大四学生及毕业1年内的求职者),尤其是非985/211院校、缺乏职场信息渠道的学生。
痛点描述:学生在Boss直聘、拉勾等平台看到“负责私域流量池的搭建与闭环转化”“具备较强的抗压能力和主人翁意识”“沉淀方法论,赋能团队成长”等JD描述时,完全不知道进去了具体是干什么的。他们无法判断岗位的真实工作内容、是否适合自己、需要准备什么,导致盲目投递、面试表现差、入职后落差大。
现有做法:目前学生主要依赖知乎经验帖、学长学姐口口相传、或者付费求职辅导。但这些方式存在信息碎片化、更新不及时、个性化不足的问题。一个双非院校的学生很难获得针对自己背景的精准岗位分析。
③ 作品介绍
JD破壁机是一个Web应用工具,用户只需将招聘描述(JD)粘贴到输入框,系统即可自动完成三大核心分析:
模块一:“说人话”翻译器 —— 将JD拆解为真实日常(每天具体干什么,含时间占比百分比)、隐藏门槛(没写但会卡你的要求)、避坑指南(哪些是画大饼)。
模块二:“照镜子”匹配度 —— 用户输入自己的简单背景(学校、专业、实习经历等),AI对比JD要求,指出匹配项和缺失项,给出0-100的匹配度评分。
模块三:“下一步干嘛”行动雷达 —— 生成30天冲刺清单,按天/周拆解具体任务,每个任务包含明确的行动指令和推荐资源链接。
技术栈:React + Vite(前端)、Python FastAPI(后端)、LLM API(AI分析引擎)。
④ 用 SOLO 实现的过程
4.1 任务拆解
将整个项目拆解为5个子任务:系统架构设计、后端开发(FastAPI + LLM调用)、前端开发(React + Vite)、核心功能实现(三大模块)、集成联调与测试验证。
4.2 使用的 SOLO 能力
• 代码生成:通过 SOLO 的 general_purpose_task 子代理并行生成后端和前端代码
• 代码审查:通过 Explore 子代理对项目进行全面的完整性检查,发现了前后端字段命名不一致等6个严重问题
• 浏览器调试:使用 SOLO 的浏览器工具进行页面交互测试、截图验证
• 文件管理:使用 SearchReplace 工具精确修复代码问题
4.3 关键 Prompt 设计
系统核心是3个精心设计的Prompt模板:
• JD翻译Prompt:设定“资深互联网HR”角色,要求输出真实日常(含时间占比)、隐藏门槛、避坑指南,强制使用JSON格式
• 能力匹配Prompt:设定“技术面试官+职业导师”角色,要求客观对比用户背景与JD要求
• 行动计划Prompt:设定“求职教练”角色,要求任务具体到“去哪个网站做什么”
4.4 踩过的坑
• 前后端字段命名不一致:前端组件期望的字段名(如daily_routine)与后端Schema定义的字段名(如daily_work)不匹配,导致结果卡片显示为空。通过Explore子代理的全面检查发现并修复。
• CORS跨域问题:前端直接请求后端8000端口被浏览器阻止。解决方案是将API_BASE改为空字符串,利用Vite的proxy代理转发请求。
• API Key缺失导致启动失败:后端在启动时强制校验API_KEY,未配置时直接崩溃。改为警告模式,未配置时返回模拟数据,保证系统可体验。
• Pydantic数据类型不匹配:模拟数据中daily_work用了dict类型,但Schema定义为list[str],导致验证错误。
⑤ 成果展示
以下是系统的实际运行效果截图:

图1:JD破壁机首页
图2:说人话翻译 - 真实日常、隐藏门槛、避坑指南
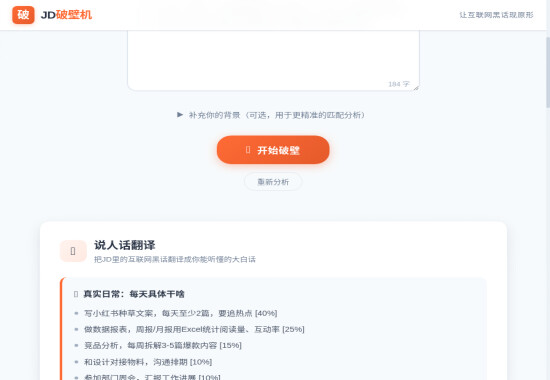
图3:照镜子匹配度 + 30天冲刺清单
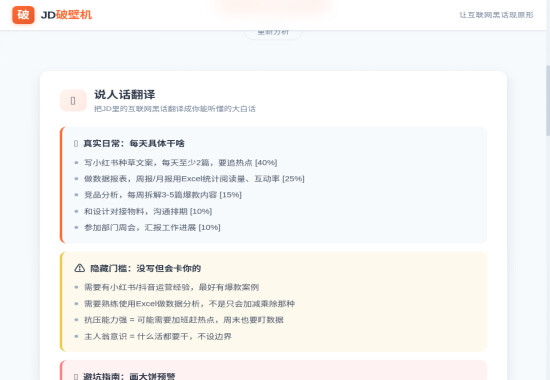
图4:30天冲刺清单详情与关键里程碑
⑥ 验证案例
下面是一个验证案例,系统直接面向JD说明了具体岗位职责,以及应聘注意事项:
一、输入:原始 JD 与用户背景
1.1 原始 JD(岗位:新媒体运营)
【岗位职责】
- 负责私域流量池的搭建与闭环转化,提升用户全生命周期价值
- 深度参与产品需求评审,从用户视角驱动产品体验升级
- 负责新媒体矩阵的内容策划与运营,包括小红书、抖音、视频号等平台
- 具备较强的抗压能力和主人翁意识,能在快节奏环境中高效产出
- 沉淀内容方法论,赋能团队成长,推动内容体系化建设
【任职要求】 - 本科及以上学历,新闻、传播、市场营销相关专业优先
- 1 年以上新媒体运营经验,有从 0 到 1 搭建账号经验者优先
- 具备优秀的文案能力和网感,能产出高传播度内容
- 数据驱动,善于通过数据分析优化内容策略
- 有爆款内容案例者优先
- 具备良好的沟通能力和团队协作精神
1.2 用户背景
学校:某双非一本
专业:新闻学
学历:本科
实习经历:校公众号运营 2 年,100+篇推文,最高单篇阅读 5000+
技能:秀米排版、基础 PS、Office 办公软件
二、输出:JD 大白话翻译
2.1 真实日常:每天具体干啥
● 写小红书种草文案,每天至少 2 篇,要追热点(占比 40%)
● 做数据报表,周报/月报用 Excel 统计阅读量、互动率(占比 25%)
● 竞品分析,每周拆解 3-5 篇爆款内容(占比 15%)
● 和设计对接物料,沟通排期(占比 10%)
● 参加部门周会,汇报工作进展(占比 10%)
一句话总结:这个岗位本质上是小红书内容运营,80%的时间在写文案和做数据报表。不需
要你拍视频剪片子,但要求你有网感、能追热点、会做数据分析。加班是常态,KPI 压力大。
2.2 隐藏门槛:没写但会卡你的
● 需要有小红书/抖音运营经验,最好有爆款案例
● 需要熟练使用 Excel 做数据分析,不是只会加减乘除那种
● “抗压能力强” = 可能需要加班赶热点,周末也要盯数据
● “主人翁意识” = 什么活都要干,不设边界
2.3 避坑指南:画大饼预警
● “具备较强的抗压能力” —— 翻译:加班多,且不一定是偶发的
● “主人翁意识” —— 翻译:岗位职责模糊,可能要干很多杂活
● “有竞争力的薪酬” —— 翻译:薪资不高,别期望太高
● “扁平化管理” —— 翻译:公司规模不大,晋升空间有限
● “闭环转化” —— 翻译:最终要背 KPI,转化不达标要背锅
⑦ 下一步计划
• 增加更多岗位类型的JD模板和黑话词典
• 支持批量JD对比分析功能
• 添加用户历史记录和收藏功能