1.摘要:
使用TRAE SOLO 从无到有,近乎傻瓜式编写出一个智能文档审核协作系统,即能阅读制度理解文件规定,又能自动选择合适规定对指定的一个或多个文件进行初审,还能快速执行大量表格的汇总、计算、分析,操作人员只需要进行最后的人工核对,即可轻松完成从审阅、审核、分析乃至报告的编写,甚至该系统还支持局域网内多用户协作,可以与办公室同事一起指挥AI助手,大幅减轻工作强度。
2.背景:
我是一个普通工作人员,完全没有软件开发经验,日常工作很多都需要和各种申请、报告打交道,经常需要参考对照各种文件、制度等,逐条确认各类事项的完整性、合规性审查,或者大量报表的汇总、计算、分析等,自从AI智能体开始变的火爆,于是萌生了构建一个能帮助自己减轻负担的AI助手,恰好此时接触到TRAE SOLO,于是尝试自己动手。
3.实践过程:
在此次构建过程中,我选择了了使用TRAE SOLO的GLM-5V-Turbo来协助完成该系统的编写
首先告知TRAE SOLO我想要实现的功能,以及大致的工作流程,于是TRAE SOLO开始自动创建任务,并向我提出了三个问题,我作出了以下回复:

于是TRAE SOLO推荐并使用了Python (FastAPI) + Vue.js + SQLite + 多模型AI支持的方案,仅花了数秒就构建出了智能文档审核协作系统,不过虽然样子做出来来,但是实际进行测试时发现部分内容并未完整实现或者实现的方式和我设想的有所出入,于是就开始了一边测试一边修BUG的过程。
在整个构建过程中,所有的代码编写都由TRAE SOLO完成,当需要环境或功能支持时,TRAE SOLO自动下载并搭建环境,我只负责通过对话和图片向TRAE SOLO反馈遇到的问题、错误信息以及我设想的修改方向
关键 Prompt
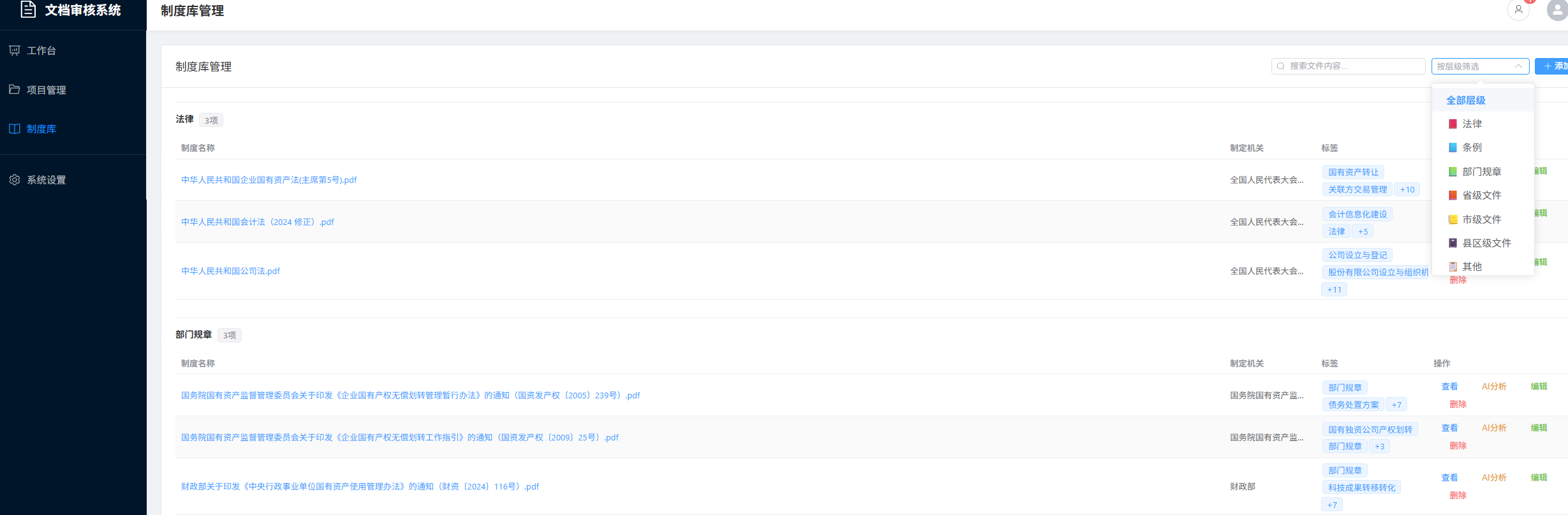
- 1、识别office文档、PDF、图片、txt文档内容,如果有压缩包,可以执行解压缩后再执行识别;2、上传文件进入制度库的 ,理解是用于哪些方面和如何使用;上传文件进入项目文档,先分析是什么事项,然后结合制度库相关内容进行分析,分析内容包括是否合规、材料是否齐全、流程是否正确等、并给出参考意见;3、用户可以对参考意见进行修改,并选择生成审核意见或批复,文件的格式和排版可以参考《中华人民共和国国家标准《党政机关公文格式》(GBT 9704-2012)》;4、需要有UI以便于用户交互;5、UI具备局域网或内网联机功能,以便多人协作,用户首次访问后可以自定义昵称,且昵称不能与现有其他人昵称重复,昵称可以随时修改;
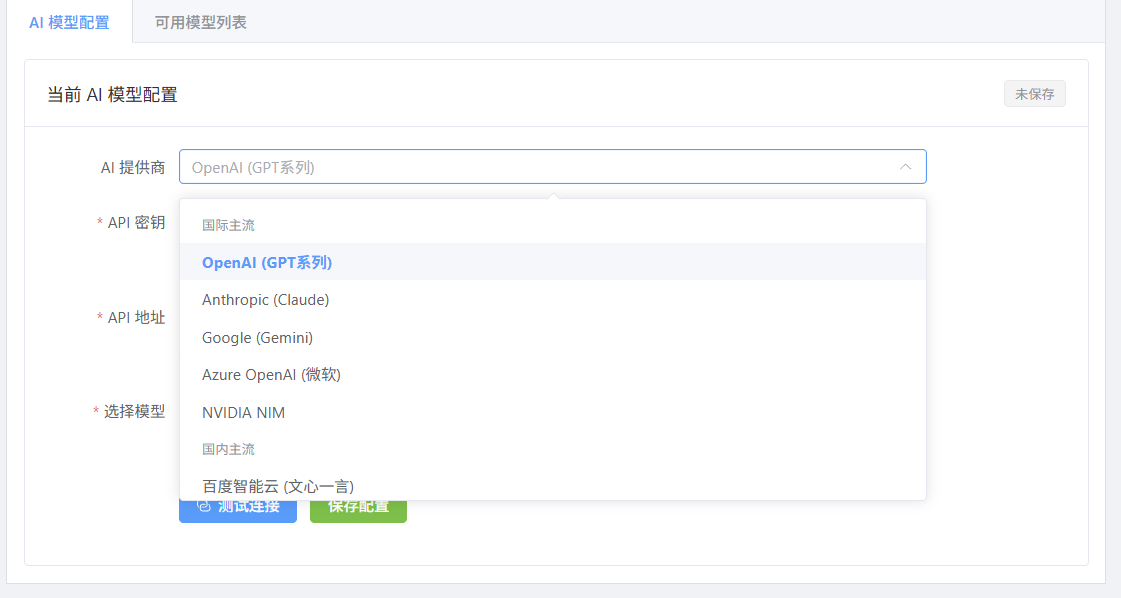
- 1、上传文件后显示(待AI详细分析),未能识别要点;2、配置模型中需要增加手动添加模型和保存功能,以适应自定义需求
- 1、制度库AI分析显示“分析失败:”,建议检查AI分析逻辑,应当将文件传递给模型后由模型识别,判断文件类型,所属层级、生效时间、规定范围、涉及事项、程序流程、所需材料、内容要求、审批权限要求、禁止事项等,并根据件类型,所属层级、涉及事项为文件添加标签,以便审核文件时快速查找;2、搜索、筛选功能有问题,提示"搜索失败"
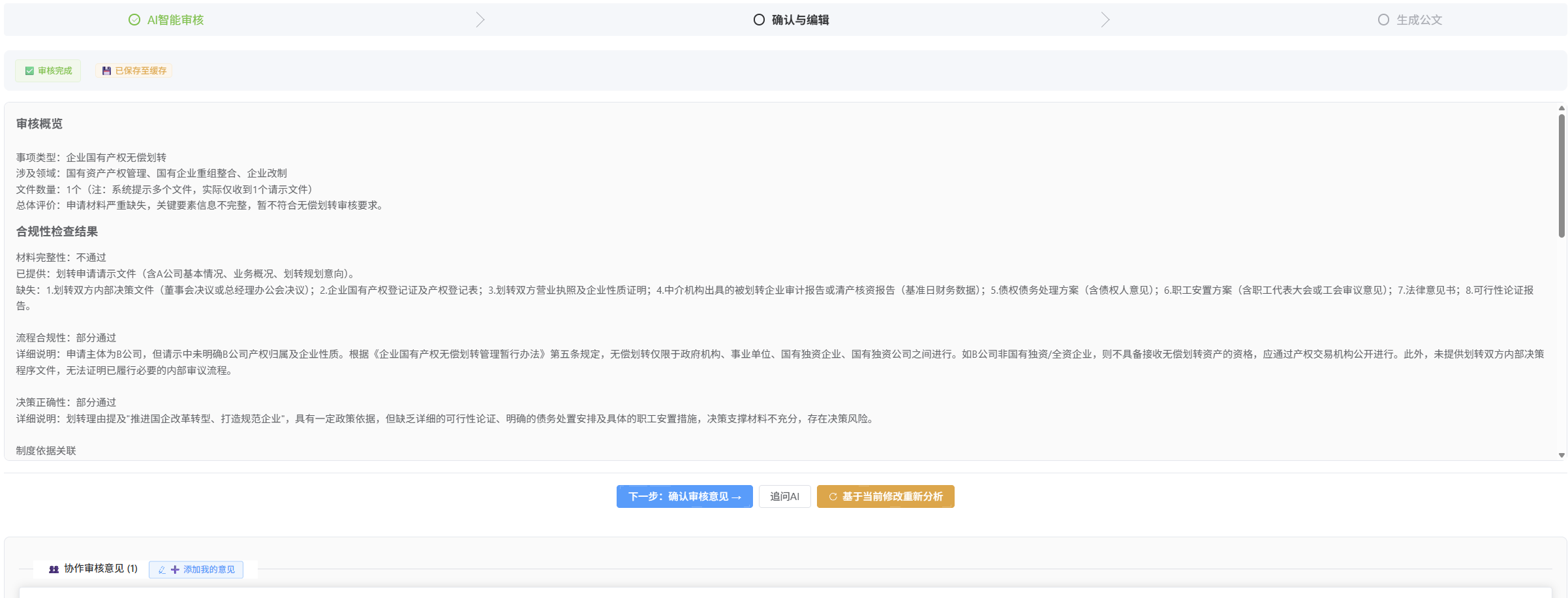
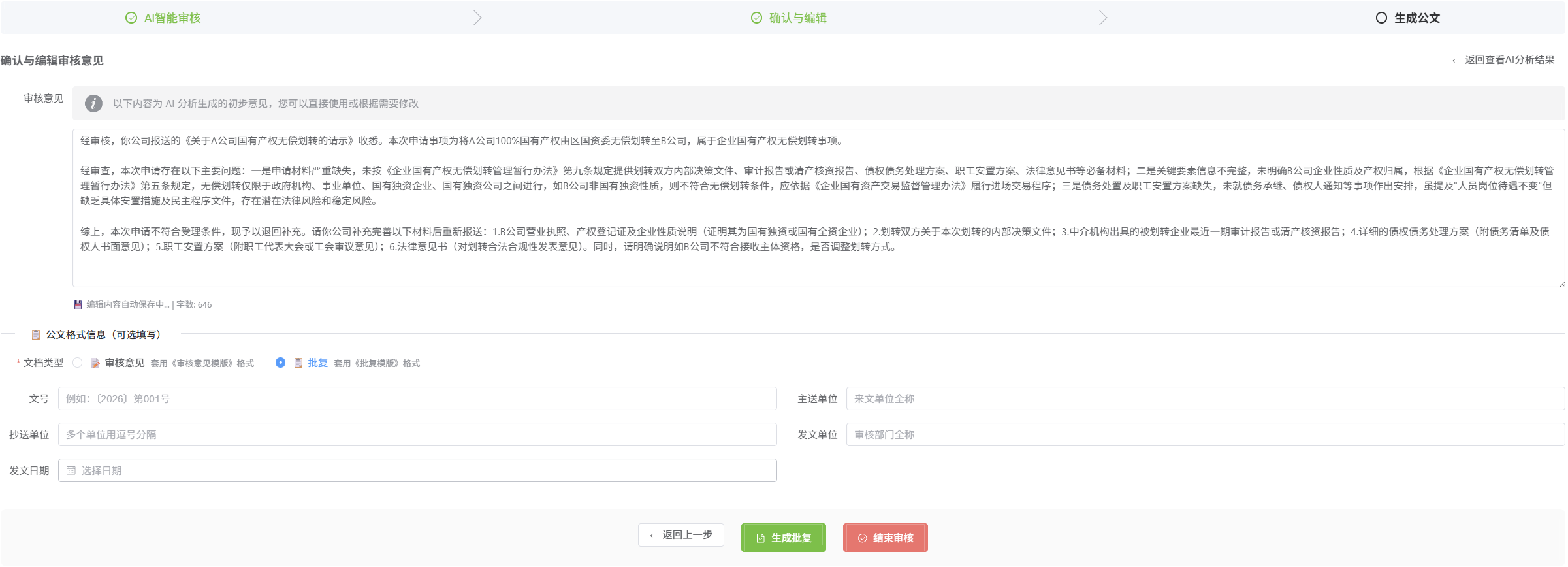
- 1、项目管理中,审核过程同样需要上传文件,和制度库文件上传方式一样提交给模型;2、审核时无需再选择需要审核的文档,而是将整个项目内涉及的所有文件都作为该事项的相关材料提交给模型;3、如果审核过程中发现相应制度缺失的,可以提出疑问,以便用户补充相关制度,确实未出台制度的,经用户确认后,以上位文件为依据执行;4、用户确认审核结果前,AI分析结果保存在缓存中随时可以查看,并且用户可以随时对分析结果进行修改,之后用户可以选择生成相应反馈意见、审核意见、或批复,生成时可以参照模版(如反馈审核意见模版.docx、批复模版.docx)生成并预览、修改,确认无误后点击生成按钮生成相应文档。
- 项目管理中的审核事项最后一步生成公文阶段,在生成公文右侧增加一个按钮,按钮文字为“结束审核”,点击后保存并锁定该事项此前的所有内容,包括上传的文件,AI审核的内容、协作审核意见、审核意见、公文格式信息,均不能再修改,同时该项目的状态更改为已审核,开始智能审核按钮改成查看
- 统计事项中上传的Excel表格中有部分单元格是公式,但是AI分析时提示数据缺失,说明未能识别公式所在单元格的数值
中间踩过的坑:
(1)、一开始的时候,根本没考虑到我所看到的前端与TRAE SOLO看到的后端是有差异的,在我为制度库增加了编辑按钮后,我在前端发现制度库并未增加该按钮,于是反馈给TRAE SOLO后,TRAE SOLO经过检查告诉我功能一切正常并输出了正确的流程和结果,直到我截图并发送给TRAE SOLO后才发现,原来TRAE SOLO将编辑按钮放在了筛选后的页面,导致我在筛选前始终找不到;
(2)、环境和兼容性问题,在完成基本构建并正常运行之后,为了测试该系统的通用性,我将该系统复制到了另外一台设备上进行测试,结果疯狂报错,经TRAE SOLO分析后发现原来是另一台设备上安装的python版本过高导致不兼容,于是在启动脚本中又增加了兼容性检查和提示;
(3)、最大的一个坑是PDF的识别和上传问题,由于我是通过网页打印成PDF文件进行的测试,且我确认可以通过我测试使用的模型来直接识别PDF内容,但是每次上传PDF都会出现要么文字重复,要么内容阶段,要么干脆就是识别不到内容,尝试了PyMuPDF、pikepdf、pdfminer、OCR等多个方案都未能解决,让我相当崩溃,经过多次尝试失败后,通过提示,TRAE SOLO在GitHub上找到了解决方案,通过PDF转换成Base64编码并构造FilePart对象的方式成功向模型传递了正确内容,这时候我才了解到这是因为网页打印PDF使用了 Skia/PDF渲染引擎,这种PDF在某些环境下不能正常被解析。
4.成果展示:
由于仅是测试使用,所有制度文件仅使用了公开的法律法规和中央部委文件,测试用的报告和报表等也仅是简单填写的内容,要使用基于AI的分析功能的话需要自行配置相应API,我进行测试时使用的模型是KIMI2.5。


5.效果与总结:
目前这个系统还是比较粗糙,还有较大的优化空间,但是起码实现了基本功能。未来的设想是能够部署在云端,根据自身信息安全要求考虑使用本地模型或配置在线模型,以及进行针对性的优化和调校