说话人识别字幕转录工具
基于声纹识别的智能字幕提取解决方案
摘要
本项目是一个基于深度学习的字幕转录与说话人识别工具,支持从音频中自动转录文字、识别说话人、提取特定说话人的字幕内容。
界面展示
字幕转录工具主界面:
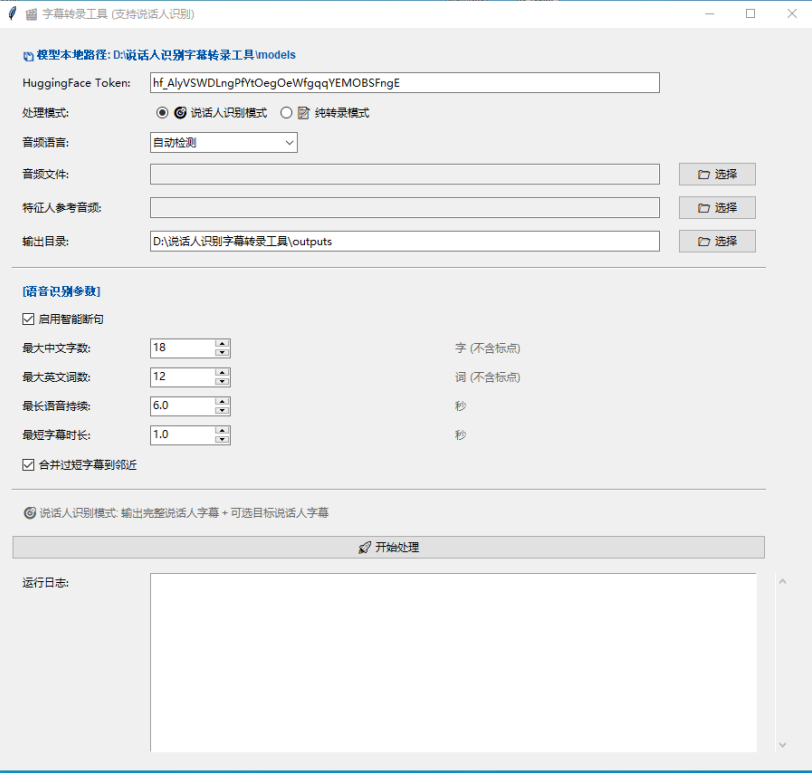
背景
在实际的视频制作、访谈记录、会议纪要等场景中,经常需要从音频中提取字幕并区分不同说话人。传统方式需要人工逐条标注,效率低下且容易出错。本工具通过集成多个先进的AI模型,实现了从音频到带说话人标签字幕的全自动化流程。
核心功能
说话人分离:自动识别音频中的不同说话人,标注每段语音的说话人
智能转录:支持多语言语音识别,自动生成字幕文件
VAD断句:结合语音活动检测实现自然断句,字幕阅读流畅
声纹匹配:通过声纹特征提取特定说话人内容
精确时间戳:单词级时间戳确保字幕与音频完美同步
技术架构
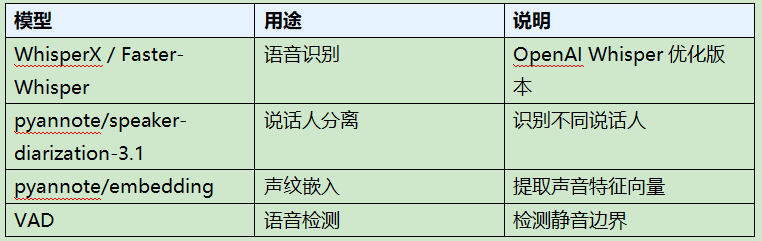
处理流程
1. Step 1: 音频加载 - 支持 WAV/MP3/M4A/FLAC 等格式
2. Step 2: 语音转录 - 使用 Faster-Whisper 进行语音识别
3. Step 3: 说话人分离 - 使用 pyannote 识别不同说话人
4. Step 4: 时间对齐 - 将转录结果与说话人时间轴对齐
5. Step 5: 智能断句 - 结合 VAD + 标点符号进行自然断句
6. Step 6: 字幕输出 - 生成 SRT 格式字幕文件
功能模块
模块一:字幕转录工具
支持两种模式:说话人识别模式 / 纯转录模式。可调节断句参数,输出完整说话人字幕和目标说话人字幕。
模块二:特征人字幕提取工具
从已有字幕中提取特定说话人内容。仅需几秒特征人音频样本即可识别,适用于访谈、纪录片等多人对话场景。
项目结构
说话人识别字幕转录工具/
├── gui_main.py # 主程序GUI
├── speaker_extract.py # 特征人字幕提取工具
├── speaker_service.py # 核心服务逻辑
├── requirements.txt # 依赖列表
├── 启动程序.bat # Windows启动脚本
├── venv/ # Python虚拟环境
├── models/ # 模型缓存目录
└── outputs/ # 输出目录
使用说明
环境准备
1. 安装 Python 3.10+
2. 创建虚拟环境:python -m venv venv
3. 激活虚拟环境:venv\Scripts\activate
4. 安装依赖:pip install -r requirements.txt
5. 获取 HuggingFace Token
运行方式
双击 启动程序.bat,选择要启动的工具。
技术亮点
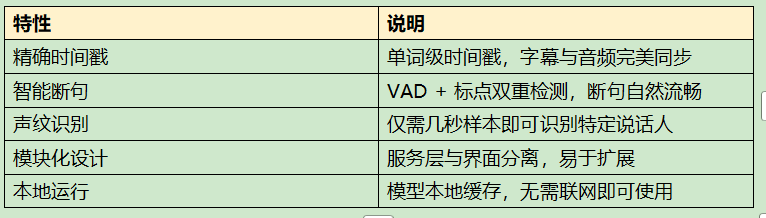
总结
本工具通过集成 WhisperX、pyannote.audio 等先进模型,实现了从音频到带说话人标签字幕的全自动化流程。适用于访谈节目字幕制作、会议记录整理、纪录片字幕提取、多人对话场景分析等场景。