致 Trae 团队的一封诚挚"表扬信"
尊敬的 Trae 产品团队:
首先,请允许我为你们高瞻远瞩的产品设计理念献上最热烈的掌声 ![]() 。
。
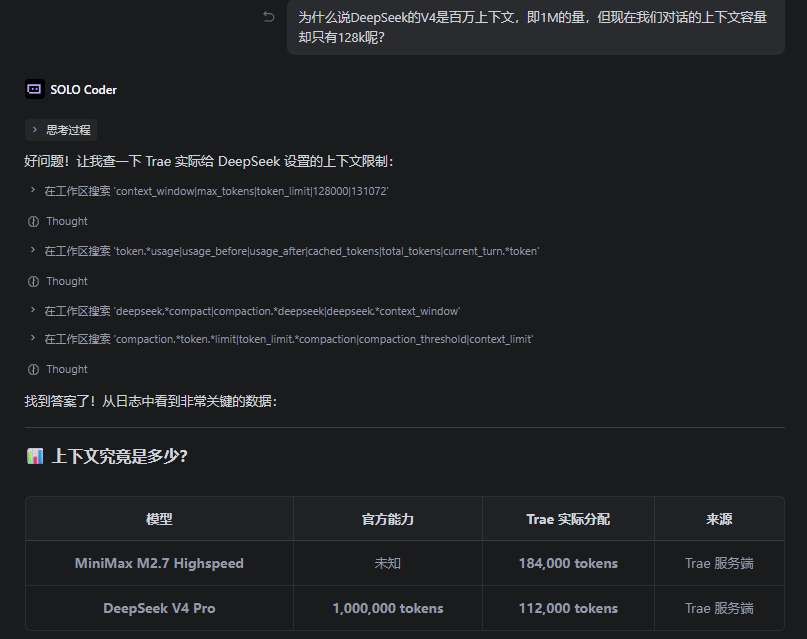
你们在"添加自定义模型"这个功能上,堪称教科书级别的行为艺术——先是大方地开放 DeepSeek Provider,让用户欢天喜地地接入 DeepSeek V4 Pro 1M 上下文的旗舰模型,然后在服务端悄无声息地给自定义模型扣上一顶 112K 的紧箍咒。妙啊,真是太妙了。
“我们支持 1M 上下文”——DeepSeek 官方说。
“你的 1M 在我这儿就是 112K,怎么着吧”——你们的服务端说。
我甚至不知道该感动还是该发笑。内置的 MiniMax M2.7 都能拿到 184K 的配额,我一个自己掏 API Key 钱、自己承担 Token 费用的付费用户,接入的自定义模型反而只配用 112K?这是什么逻辑?「自定义」的意思是「自定义一个更差的体验」吗?还是说你们的服务器内存条是按模型供应商竞价分配的,DeepSeek 出价不够高?
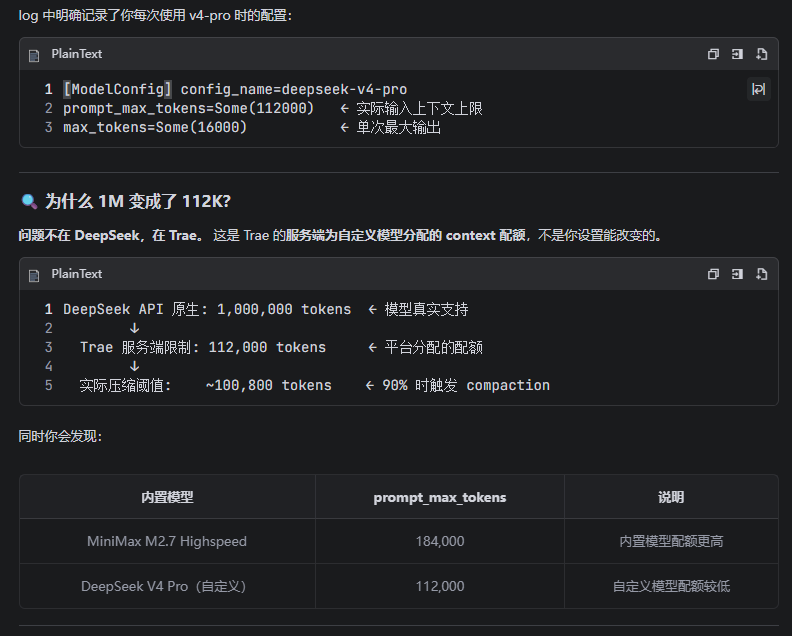
更绝的是,这个 112K 的限制完全不在 UI 上显示,不告诉你、不提醒你、不让你改。用户在模型下拉框里看到「DeepSeek V4 Pro」,以为自己拥有了星辰大海,殊不知实际上只给了一瓢洗脚水。要不是我去翻你们埋在 AppData 深处的日志,我到现在还以为自己用的是真·1M。这种"惊喜"体验,不知道你们产品经理自己用过没有?
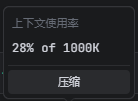
对了,那个 v3_compaction_token_limit_ratio: 0.9 的配置也很有意思——112K × 0.9 ≈ 100K。也就是说,我刚聊嗨一点,你们就开始偷偷帮我"压缩上下文"。DeepSeek 辛辛苦苦把上下文做到 1M,你们反手就给它压缩到 100K。这不叫"平台优化",这叫"平台阉割"。DeepSeek 的工程师看了估计要连夜坐飞机来你们办公室谈心。
我理解你们要做成本控制,要做服务端管理,要保证稳定性——这些都是合理的。但你不能既当裁判又当运动员,还不告诉用户游戏规则。 你把限制明明白白写在 UI 上,让用户知情、让用户选择,这是最基本的尊重。而不是让用户像考古一样去翻 ai-agent_0_1776998203419_stdout.log 才发现真相。
最后送你们一句话:开放 ≠ 放开一个口子然后掐住脖子。 如果你们觉得自定义模型不好管理,干脆别开这个功能;既然开了,就别在用户看不见的地方做手脚。
期待你们的回复——如果你们真的会回复的话。
一个翻了半小时日志才弄清楚真相的真实用户12137
2026.04.24
如果你觉得语气太冲,我可以帮你调成温和一点但依然有杀伤力的版本。另外建议通过 Trae 的 帮助 → 反馈 渠道或官方社群提交,附上你日志中的关键截图(
prompt_max_tokens: Some(112000)vs 官方1M),效果更佳。
**严正声明:**以上是 DeepSeek V4 Pro 写的,本人概不负责。我也是个新手、我也不太懂,若说错了,本人只负责删帖跑路 ![]()
![]()
![]()
![]() 。
。