![]()
做完笔记后,可以用TRAE辅助梳理知识框架、制作流程图、思维导图、检查知识是否有误、是否有点内容遗漏需要补充。
需求1:将文件夹内容梳理一下,拆分成一个一个小知识节点。利用Obsidian的双向链接等功能,还可以拆分后制作白板生成思维导图,便于学习。
整理好后的笔记内容
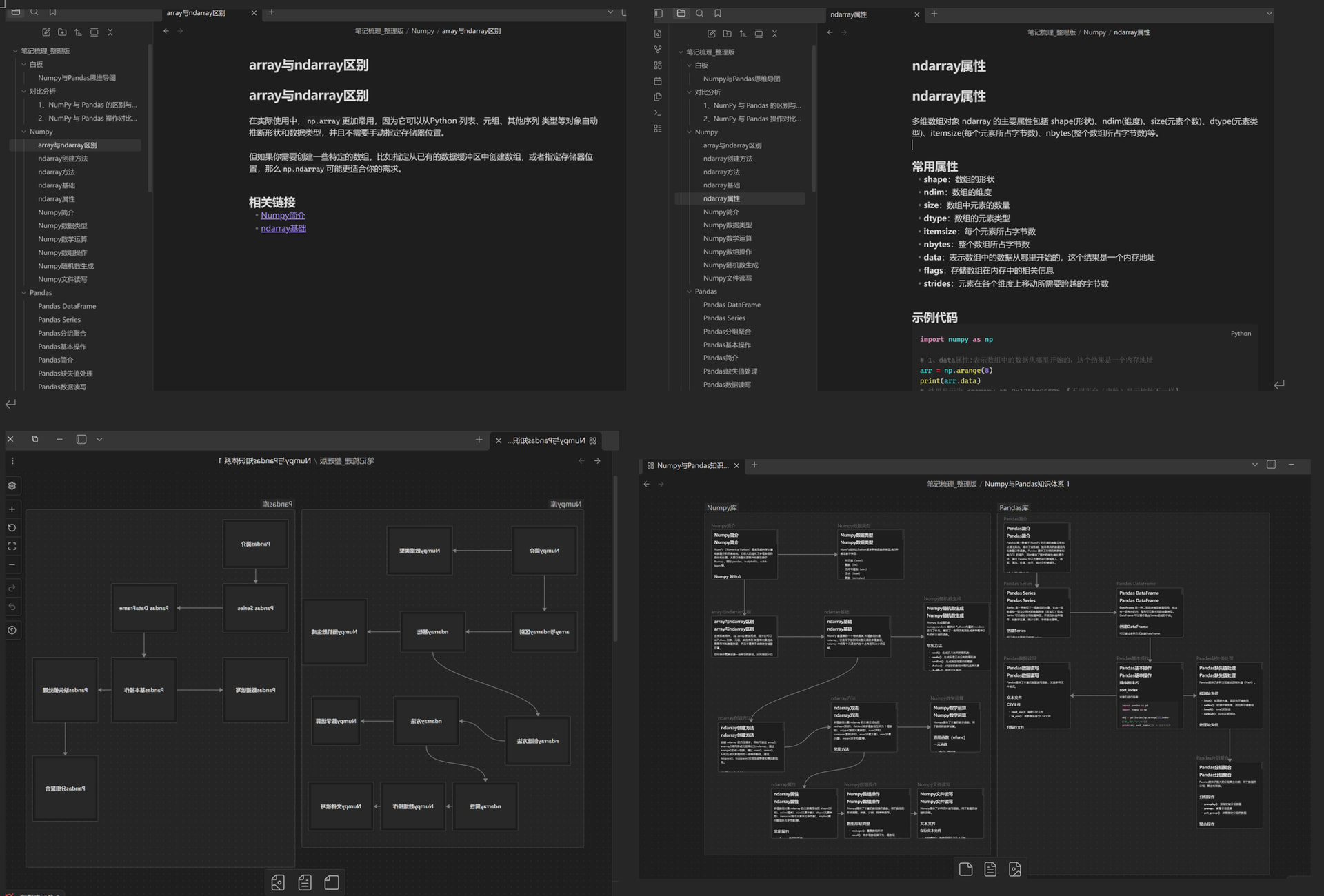
Numpy与Pandas思维导图
Numpy
-
Numpy简介
-
特点
-
核心概念
-
-
Numpy数据类型
-
基本数据类型
-
详细数据类型
-
-
array与ndarray区别
-
ndarray基础
-
核心概念
-
相关链接
-
-
ndarray创建方法
-
常用创建方法
-
示例代码
-
-
ndarray方法
-
常用方法
-
astype操作
-
reshape操作
-
转置操作
-
-
ndarray属性
-
常用属性
-
示例代码
-
strides属性详解
-
Pandas
-
Pandas简介
-
核心数据结构
-
主要特点
-
-
Pandas Series
-
创建方法
-
操作示例
-
-
Pandas DataFrame
-
创建方法
-
操作示例
-
-
Pandas 基本操作
-
数据读取
-
数据处理
-
数据分析
-
————————————————————————————————————
————————————————————————————————————
需求2:对比Numpy及Pandas,分析区别与联系,并对操作进行对比。
输出内容如下:
————————————————————————————————————
NumPy 与 Pandas 的区别与联系
虽然 NumPy 和 Pandas 都可以处理表格数据并进行整行/列操作,但它们在设计理念、数据结构和功能上有显著区别:
核心区别
1. 数据结构
-
NumPy:核心是
ndarray(n维数组),是同质的多维数组,所有元素必须是相同数据类型 -
Pandas:核心是
Series(一维)和DataFrame(二维),支持异质数据类型,每列可以有不同类型
2. 功能定位
-
NumPy:专注于数值计算,提供高效的数学运算和数组操作
-
Pandas:专注于数据分析,提供数据清洗、处理、分析和可视化工具
3. 索引系统
-
NumPy:使用整数位置索引
-
Pandas:支持标签索引,更灵活的索引方式
4. 缺失值处理
-
NumPy:原生不支持缺失值(NaN)的高效处理
-
Pandas:内置强大的缺失值处理能力
联系与协作
-
Pandas 构建在 NumPy 之上:Pandas 的底层实现依赖 NumPy 的数组操作
-
数据转换:可以在 NumPy 数组和 Pandas 对象之间轻松转换
-
互补使用:通常在数据分析工作流中结合使用,NumPy 处理数值计算,Pandas 处理数据管理
适用场景
-
NumPy:适合需要高性能数值计算的场景,如科学计算、机器学习算法
-
Pandas:适合数据清洗、探索性分析、时间序列分析、数据可视化等场景
示例对比
NumPy 示例
import numpy as np
# 创建二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("NumPy数组:")
print(arr)
print("形状:", arr.shape)
print("按列求和:", arr.sum(axis=0))
print("按行求和:", arr.sum(axis=1))
Pandas 示例
import pandas as pd
# 创建DataFrame
df = pd.DataFrame({
'A': [1, 4],
'B': [2, 5],
'C': [3, 6]
})
print("Pandas DataFrame:")
print(df)
print("形状:", df.shape)
print("按列求和:")
print(df.sum())
print("按行求和:")
print(df.sum(axis=1))
总结:虽然两者都能处理表格数据,但 Pandas 提供了更高级、更灵活的数据处理能力,特别适合数据分析任务,而 NumPy 则在数值计算性能上更具优势。
————————————————————————————————————
NumPy 与 Pandas 操作对比分析
本文档对 NumPy 和 Pandas 的核心操作进行详细对比,帮助理解两者的异同点和适用场景。
一、数据结构对比
| 特性 | NumPy | Pandas |
|---|---|---|
| 核心数据结构 | ndarray (n维数组) | Series (一维)、DataFrame (二维) |
| 数据类型 | 同质,所有元素类型相同 | 异质,每列可以有不同类型 |
| 索引方式 | 整数位置索引 | 标签索引 + 位置索引 |
| 内存占用 | 较低 | 较高 |
| 灵活性 | 较低 | 较高 |
二、基本操作对比
1. 创建数据
| 操作 | NumPy | Pandas |
|---|---|---|
| 从列表创建 | np.array([1, 2, 3]) |
pd.Series([1, 2, 3]) |
pd.DataFrame({'a': [1, 2], 'b': [3, 4]}) |
||
| 零矩阵 | np.zeros((2, 3)) |
pd.DataFrame(0, index=[0, 1], columns=['a', 'b', 'c']) |
| 单位矩阵 | np.eye(3) |
pd.DataFrame(np.eye(3)) |
| 随机数 | np.random.rand(2, 3) |
pd.DataFrame(np.random.rand(2, 3)) |
| 等差数列 | np.arange(0, 10, 2) |
pd.Series(np.arange(0, 10, 2)) |
2. 索引与切片
| 操作 | NumPy | Pandas |
|---|---|---|
| 按位置索引 | arr[0, 1] |
df.iloc[0, 1] |
| 按标签索引 | 不支持 | df.loc[0, 'column'] |
| 切片 | arr[1:3, 0:2] |
df.iloc[1:3, 0:2] |
df.loc[1:3, 'col1':'col3'] |
||
| 布尔索引 | arr[arr > 5] |
df[df['column'] > 5] |
| 花式索引 | arr[[0, 2], [1, 3]] |
df.iloc[[0, 2], [1, 3]] |
3. 数据操作
| 操作 | NumPy | Pandas |
|---|---|---|
| 按列求和 | arr.sum(axis=0) |
df.sum() |
| 按行求和 | arr.sum(axis=1) |
df.sum(axis=1) |
| 均值 | arr.mean() |
df.mean() |
| 最大值 | arr.max() |
df.max() |
| 最小值 | arr.min() |
df.min() |
| 标准差 | arr.std() |
df.std() |
| 排序 | np.sort(arr) |
df.sort_values(by='column') |
| 转置 | arr.T |
df.T |
4. 数据清洗
| 操作 | NumPy | Pandas |
|---|---|---|
| 缺失值检测 | np.isnan(arr) |
df.isna() |
| 缺失值处理 | 有限支持 | df.dropna() |
df.fillna(value) |
||
| 重复值检测 | 不直接支持 | df.duplicated() |
| 重复值删除 | 不直接支持 | df.drop_duplicates() |
| 数据类型转换 | arr.astype(float) |
df.astype({'col': float}) |
5. 文件操作
| 操作 | NumPy | Pandas |
|---|---|---|
| 读取CSV | np.genfromtxt('file.csv', delimiter=',') |
pd.read_csv('file.csv') |
| 读取Excel | 不直接支持 | pd.read_excel('file.xlsx') |
| 写入CSV | np.savetxt('file.csv', arr, delimiter=',') |
df.to_csv('file.csv', index=False) |
| 写入Excel | 不直接支持 | df.to_excel('file.xlsx', index=False) |
6. 高级操作
| 操作 | NumPy | Pandas |
|---|---|---|
| 合并数据 | np.concatenate([arr1, arr2]) |
pd.concat([df1, df2]) |
pd.merge(df1, df2, on='key') |
||
| 分组聚合 | 不直接支持 | df.groupby('column').agg({'value': 'sum'}) |
| 时间序列 | 有限支持 | pd.date_range('2020-01-01', periods=7) |
df.resample('D').sum() |
||
| 应用函数 | np.vectorize(func)(arr) |
df.apply(func, axis=1) |
| 滚动窗口 | 有限支持 | df.rolling(window=3).mean() |
三、性能对比
| 场景 | NumPy | Pandas |
|---|---|---|
| 数值计算 | 非常快 | 较快 |
| 数据处理 | 较快 | 灵活但较慢 |
| 内存使用 | 高效 | 较高 |
| 大规模数据 | 适合 | 适合但需要优化 |
四、适用场景对比
| 场景 | NumPy | Pandas |
|---|---|---|
| 科学计算 | ||
| 机器学习 | ||
| 数据分析 | ||
| 数据可视化 | ||
| 时间序列分析 | ||
| 数据清洗 |
五、代码示例对比
1. 基本操作示例
NumPy 示例:
import numpy as np
# 创建数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("原始数组:")
print(arr)
# 索引和切片
print("\n索引 arr[1, 2]:", arr[1, 2])
print("切片 arr[0:2, 1:3]:")
print(arr[0:2, 1:3])
# 数学运算
print("\n按列求和:", arr.sum(axis=0))
print("按行求和:", arr.sum(axis=1))
print("平均值:", arr.mean())
# 布尔索引
print("\n大于5的元素:", arr[arr > 5])
Pandas 示例:
import pandas as pd
# 创建DataFrame
df = pd.DataFrame({
'A': [1, 4, 7],
'B': [2, 5, 8],
'C': [3, 6, 9]
}, index=['X', 'Y', 'Z'])
print("原始DataFrame:")
print(df)
# 索引和切片
print("\n按标签索引 df.loc['Y', 'B']:", df.loc['Y', 'B'])
print("按位置索引 df.iloc[1, 1]:", df.iloc[1, 1])
print("切片 df.loc['X':'Y', 'A':'B']:")
print(df.loc['X':'Y', 'A':'B'])
# 数学运算
print("\n按列求和:")
print(df.sum())
print("按行求和:")
print(df.sum(axis=1))
print("平均值:")
print(df.mean())
# 布尔索引
print("\n大于5的元素:")
print(df[df > 5])
2. 数据处理示例
NumPy 示例:
import numpy as np
# 处理缺失值
arr = np.array([[1, np.nan, 3], [4, 5, np.nan]])
print("含有缺失值的数组:")
print(arr)
# 替换缺失值
arr_filled = np.where(np.isnan(arr), 0, arr)
print("\n替换缺失值后:")
print(arr_filled)
# 数组操作
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
print("\n数组连接:", np.concatenate([arr1, arr2]))
print("数组形状调整:", arr1.reshape(3, 1))
Pandas 示例:
import pandas as pd
import numpy as np
# 处理缺失值
df = pd.DataFrame({
'A': [1, 4, 7],
'B': [2, np.nan, 8],
'C': [np.nan, 6, 9]
})
print("含有缺失值的DataFrame:")
print(df)
# 替换缺失值
df_filled = df.fillna(0)
print("\n替换缺失值后:")
print(df_filled)
# 删除缺失值
df_dropped = df.dropna()
print("\n删除缺失值后:")
print(df_dropped)
# 数据操作
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
print("\nDataFrame连接:")
print(pd.concat([df1, df2]))
# 分组聚合
df_group = pd.DataFrame({
'Group': ['A', 'A', 'B', 'B'],
'Value': [10, 20, 30, 40]
})
print("\n分组聚合:")
print(df_group.groupby('Group').sum())
六、总结
-
NumPy 是数值计算的基础库,提供高效的数组操作和数学函数,适合科学计算和机器学习的底层实现。
-
Pandas 是构建在 NumPy 之上的数据分析库,提供更高级的数据结构和操作,适合数据清洗、分析和处理。
-
选择建议:
-
对于纯数值计算,优先使用 NumPy
-
对于数据分析任务,优先使用 Pandas
-
在实际应用中,两者通常结合使用,发挥各自优势
-
-
性能考虑:
-
当处理大规模数值数据时,NumPy 通常比 Pandas 更快
-
当需要灵活的数据处理和分析功能时,Pandas 的便利性超过性能差异
-
通过理解两者的差异和适用场景,可以更有效地选择合适的工具来完成数据相关任务。