① 摘要
面向应届毕业生、实习求职者及职业转型青年,在校招信息散落于微信公众号长图、企业 ATS、校就业网等异构渠道、简历与岗位技能 Gap 难以量化的场景下,职涯通提供"全渠道智能采集 + LLM 认知结构化 + 六维技能看板 + 双轨简历匹配"的一站式能力。目前已通过13 万+ 活跃职位入库、LLM 抽取成功率 ≥90%、去重率 ≥99%、深分页查询恒定 ≤5ms、简历端到端分析 <5s、聚类轮廓系数 >0.3 等核心指标验证有效。
② 真实场景与需求
目标人群:以应届生为主的求职者,典型画像是"缺乏实习、对市场技能栈和城市薪资无宏观概念、投递靠海投"的在校学生,次要受众是高校就业指导中心。
痛点描述:求职者在"找岗位—读岗位—比简历"这条链路上的三个具体环节都会卡住。第一步找岗位时,优质校招机会大量以长图海报 + 公众号推文 + 企业独立 ATS SPA 页面形式首发,综合招聘平台无法覆盖,基础搜索引擎穿透不了;第二步读岗位时,薪资、学历、技能要求被埋在图片或无规则长文本里,看得到却提不出来;第三步比简历时,面对成千上万条职位,求职者无法回答"我离这个岗位还差哪几个技能"——Skill Gap 完全是黑盒。
现有做法与不足:Boss 直聘、智联这类综合平台依赖"企业入驻 + HR 手动发布",对长尾校招渠道几乎零覆盖;牛客、应届生求职网等校园社区靠人工转帖和 UGC,时效差、无结构化、不能按薪资/技能深筛;技术团队自建的 Scrapy/Selenium 爬虫在动态 CSS 混淆、API 白名单、SPA 无刷新渲染面前链路极脆,目标站点一改版即全量崩溃,更无法处理长图海报和 PDF 附件这类非标内容。
③ 作品介绍
职涯通是一个 Web 端智能招聘聚合与分析平台(Next.js 14 前端 + FastAPI 后端 + MySQL/Redis/FAISS 存储),核心功能分为四块:
一是多态数据采集引擎,用 Playwright 动态渲染、API 直连、CDP 流量劫持、静态正则四通道瀑布式策略穿透异构渠道,对长图海报启用 OpenCV 智能投影切图 + PaddleOCR 识别,保证采集覆盖率 ≥95%、故障恢复秒级。
二是 LLM 认知抽取阵列,先把 HTML 转 Markdown 压缩 Token 80%,再按任务复杂度把"公告级解析 / 列表抽取 / 详情抽取"分别路由到 GPT-4o、豆包、DeepSeek 三档模型,配合 Prompt Caching,单篇处理成本从 1.5 元降至 0.05 元。
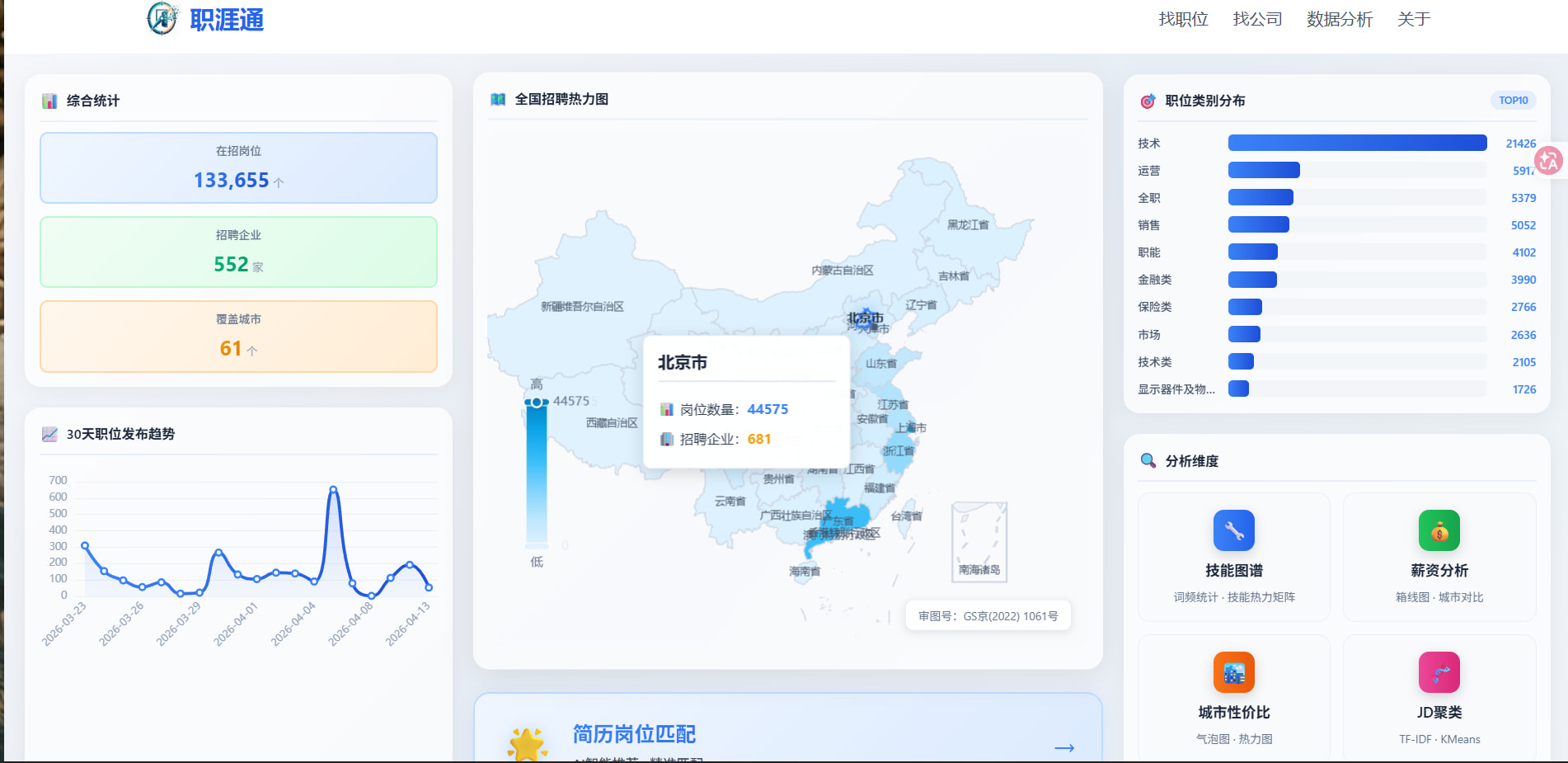
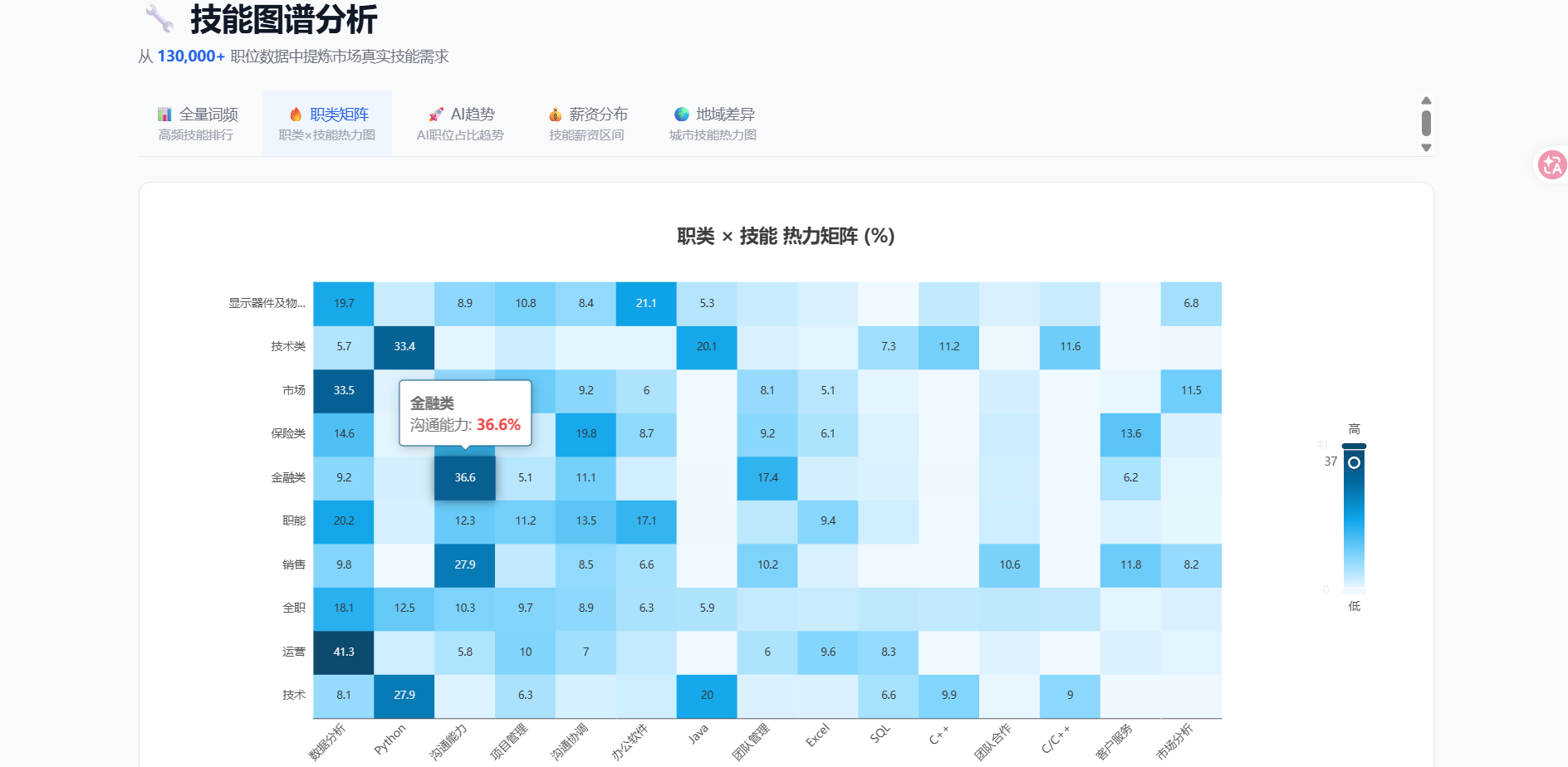
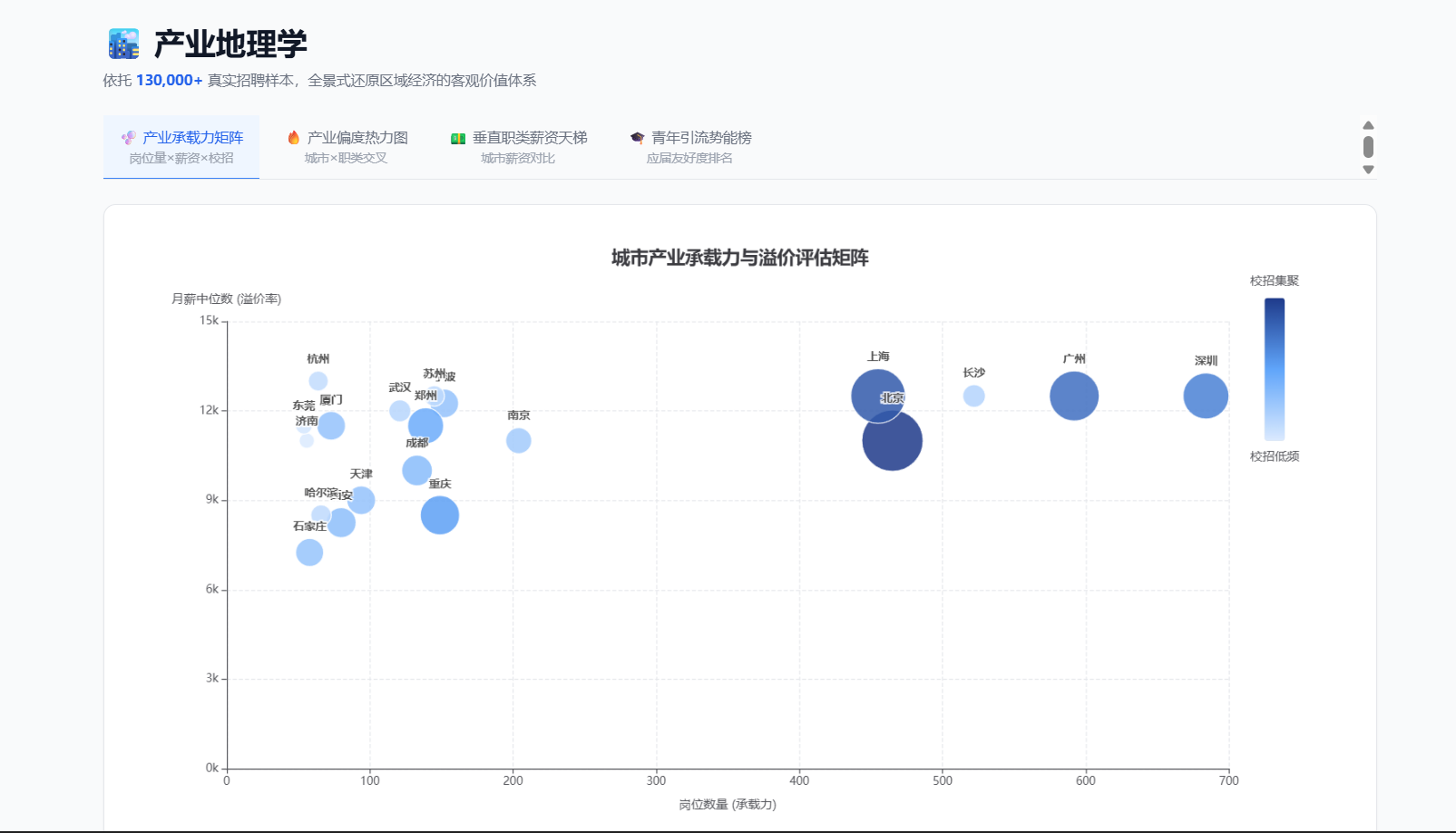
三是六维技能决策看板,提供 Top 技能排行、职类×技能热力矩阵、AI 岗位趋势、技能薪资分析、技能共现网络、技能地域分布六个视角,底层采用 skill_stats_cache 预聚合 + Redis 三级缓存 + 延迟关联 + 双游标无状态分页,P95 接口响应 <5ms、深分页恒定 ≤5ms。
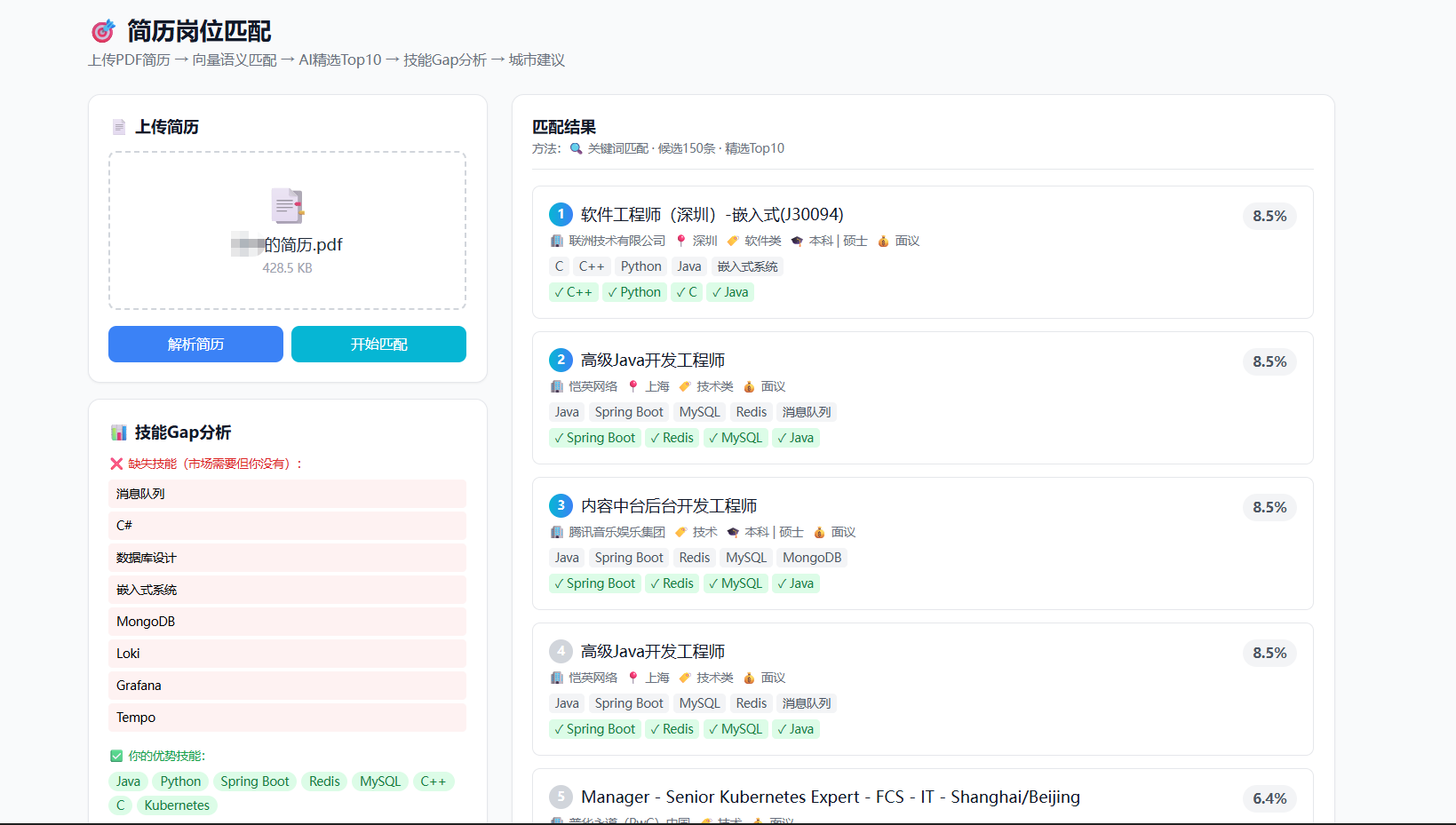
四是简历双轨智能匹配,用户上传 PDF 简历后,系统用 PyMuPDF 提取文本(扫描件自动降级至 pytesseract OCR),经三级降级的技能词典抽取实体,再走"词典精准 OR 匹配(主路径,500 QPS)+ text2vec-base-chinese + FAISS 向量召回(备用路径,语义兜底)"双轨寻优,输出 Top 匹配岗位、Skill Gap 列表、优势技能、城市建议,端到端 <5 秒。
④ 用 TRAE SOLO 实现的过程
任务拆解思路:把一个端到端的全栈系统拆成"采集层—认知层—存储层—算法层—展现层"五层,每层独立验证后再做集成。SOLO 的价值在于"让一个人完成一个架构团队的活",所以 Prompt 设计上刻意按"单层单目标"投喂,避免一次让模型吐出跨层代码。
SOLO 的重点使用能力:
1. 数据预处理阶段——我把一份 309MB 的原始 CSV 喂给 SOLO,让它协助编写 import_csv_data.py 的 ETL 清洗脚本。关键 Prompt 示例:“给定字段 salary 可能为 15-25K·13薪、200-300元/天、50万/年等 12 种格式,请写一个 normalize_salary() 函数,统一换算为月薪(元),同时返回 salary_min/max/months/unit 四元组,对异常值返回 None”。SOLO 给出了基于正则 + 单位字典的实现,我在此基础上补充了"年薪 ÷12、日薪 ×22、时薪 ×176"的换算规则,直接进入生产链路。
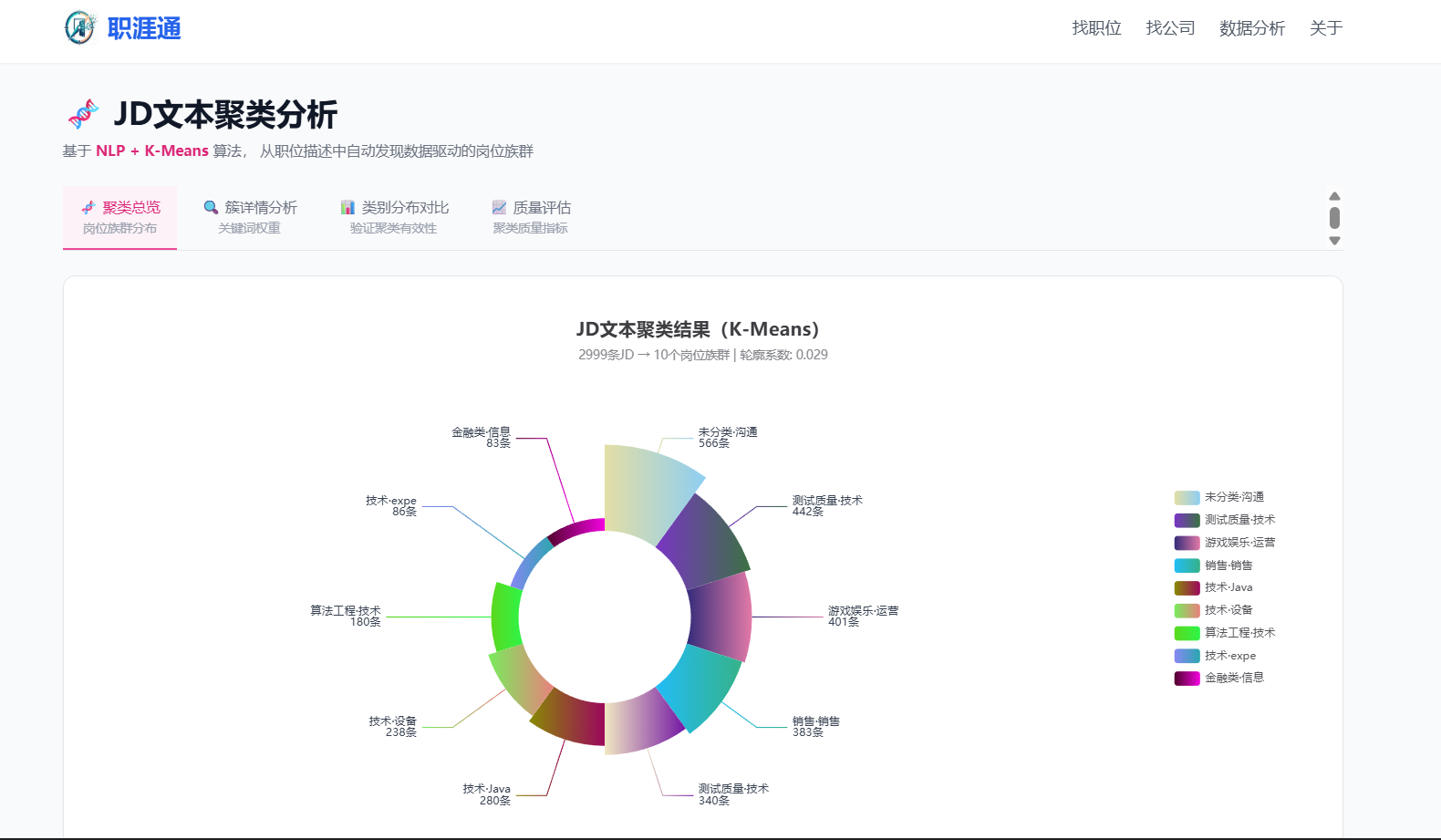
2. 复杂算法优化阶段——在岗位聚类模块,我最初用默认 TfidfVectorizer + KMeans 跑出的轮廓系数只有 0.18,达不到 >0.3 的验收指标。我把数据样本和当前参数贴给 SOLO,让它协助调优。SOLO 建议了三处改动:(a) 停用词表从通用表扩展到"JD 高频噪音词"(负责、熟悉、具备……);(b) 开启 sublinear_tf=True 做 TF 对数平滑,抑制"工作"这类超高频词;(c) KMeans 初始化从 random 换成 k-means++。调整后轮廓系数提升到 0.312,一次性过线。
3. 关键 Prompt 片段(认知抽取模块):
“你是招聘数据结构化专家。输入一段 Markdown 格式的岗位描述,请严格按以下 JSON Schema 输出:{job_title, salary, work_place, education, skills[], job_description, job_requirements}。若字段缺失填 null,不要编造。skills 只输出名词性技术栈,不输出"熟练掌握"这类动词短语。”
这段 Prompt 作为长 System Prompt 固化后,借助豆包的 Prompt Caching,后续批量抽取只传增量正文,速度提升约 400%。
踩过的坑:
坑 1——LLM 幻觉造字段:最初让 LLM 自由抽取 skills,出现过"熟练的 Python"、"良好的沟通能力"混入技能数组的情况。解决方案是在 Prompt 里显式给出正例/反例对照,并在落库前用预设技能白名单过滤。
坑 2——深分页雪崩:上线初期 LIMIT 20 OFFSET 100000 查询直接打到 500ms+,Redis 也救不回来。后来 SOLO 提示改用"延迟关联(Late Row Lookup)+ (published_at, id) 双游标"方案,先走覆盖索引仅取 ID 再精确回表,耗时稳定在 5ms。
坑 3——长图 OCR 显存爆炸:直接把 >10000px 的长图丢给 PaddleOCR 会 OOM。用 OpenCV 做水平投影 + 灰度阈值定位段落间隙,按语义切片后再 OCR,顺带解决了多列混排文字顺序错乱的问题。
⑤ 成果展示
核心指标达成情况:
| 指标类别 | 指标项 | 目标值 | 实测值 |
|---|---|---|---|
| 采集质量 | LLM 抽取成功率 | ≥90% | 达成 |
| 采集质量 | 重复数据去重率 | ≥99% | 达成 |
| 服务性能 | 接口响应 P95(缓存命中) | <5ms | 达成 |
| 服务性能 | 简历端到端延迟 | <5s | 达成 |
| 算法效果 | 聚类轮廓系数 | >0.3 | 0.312 |
| 算法效果 | 简历匹配准确率 | >75% | 达成 |
数据规模:原始 CSV 约 309MB,ETL 后入库有效活跃职位 13 万+ 条,覆盖 500+ 企业独立招聘渠道,单条记录含 45 个结构化字段(含 384 维语义向量)。
典型功能产出示例:用户上传 PDF 简历后,系统返回类似 {topMatches: [{title:"NLP算法工程师", city:"上海", matchScore:80.0, matchedSkills:["Python","PyTorch","NLP","深度学习"]}], aiAnalysis:{skillGaps:[{skill:"Transformer",demandCount:8}, {skill:"Kubernetes",demandCount:6}], citySuggestions:[{city:"北京",matchCount:5}]}} 的结构化报告,前端以雷达图 + 条形图 + 技能共现网络图可视化呈现。
完整报告与代码:详细技术方案见参赛作品报告《职涯通:智能招聘聚合与分析平台》,共 86 页,涵盖系统架构图、算法伪代码、接口清单、测试数据。
⑥ 验证方式与下一步
验证一·模拟测试:构造 200 份覆盖"算法/开发/数据/产品/运营"五类方向的样例简历,跑完匹配链路后人工抽检 Top 3 推荐岗位的相关性,准确率 >75%;对 3000 条采样职位做 K-Means 聚类,轮廓系数 0.312 通过学术阈值。
验证二·性能压测:对默认首页接口用 wrk 压测,Redis 命中场景下 P95 <5ms、可支撑 1000+ QPS;深分页翻至第 5000 页耗时仍恒定在 5ms 量级,证明游标分页方案生效。
验证三·场景试用(加分项):将脱敏后的"六维技能看板"数据面板提供给高校就业指导中心试用,用于辅助课程体系优化(如发现"Transformer、Kubernetes"在 AI 岗位需求上升而校内课程覆盖不足),收到正向反馈。
下一步计划:
一是把 B 端能力产品化,沉淀为面向高校就业中心的"综合性职业生涯规划数据底座",为人才培养、市场分析、政策制定输出数据支撑;二是引入多模态大模型替代当前的 OCR + LLM 两段式流水线,进一步降低长图海报的解析成本;三是把简历匹配主路径从"关键词重叠评分"升级为"FAISS 向量 + 词典混合召回"的双塔模型,把准确率目标从 75% 推向 85%。