1.摘要:
本系统基于TRAE SOLO从零构建,解决了HR手动筛选简历效率低、评估标准不统一的痛点。实现了多平台简历一键导入、大模型自动提取候选人信息并按岗位需求三维打分(权重为:核心能力60%+稳定性30%+软性素质10%)、基于硬性要求与总分的规则化分类,以及智能面试问题与评估报告生成,将传统数小时的简历筛选工作压缩至分钟级完成,显著提升招聘决策的效率与一致性。
2.背景:
我是一名学生,我曾担任人力资源实习生。在实习期间,我深刻体会到简历审阅与候选人评估筛选环节耗时较长、效率有限,因此希望借助TRAE SOLO平台搭建一套智能化的简历评估系统,以提升招聘筛选的工作效率与决策质量。
3.实践过程:
(1)任务拆解:
阶段一:需求分析与系统架构设计
系统架构采用单文件 HTML 应用,集成侧边栏导航、四栏看板式简历管理(有效/待定/通过/不通过)、候选人详情页、排名总览、数据统计和系统设置五大模块,无需后端服务即可在浏览器中独立运行。
阶段二:文件导入与解析
系统支持 PDF、DOCX、TXT、JPG/PNG 四类格式。通过引入 pdf.js 和 mammoth.js 在浏览器端提取 PDF 和 DOCX 中的文字内容,再交由大模型分析。图片简历仅显示云端原图,不占用本地内存。所有文件在导入时自动上传至 OSS 云存储,通过签名 URL 实现私有 Bucket 的安全访问。
阶段三:大模型集成
导入简历后,大模型自动提取候选人基本信息(姓名、学历、经验等),并根据目标岗位的名称、简介和需求,从核心能力(权重60%)、稳定性(权重30%)、软性素质(权重10%)三个维度进行量化打分。评分标准经过多轮迭代优化,明确了四个分档区间和详细的评分维度。简历分类采用规则引擎驱动,基于硬性要求(学历、年龄、应届)和总分阈值(≥60分为有效)进行确定性分类,避免 LLM 分类的不稳定性。此外,系统还能结合岗位需求生成针对性的面试问题和智能评估报告。
阶段四:数据持久化
通过 localStorage 实现,简历数据、评分、备注在页面刷新后完整保留。未打分的简历在页面加载时自动触发续打分,确保数据完整性。
(2)涉及SOLO能力
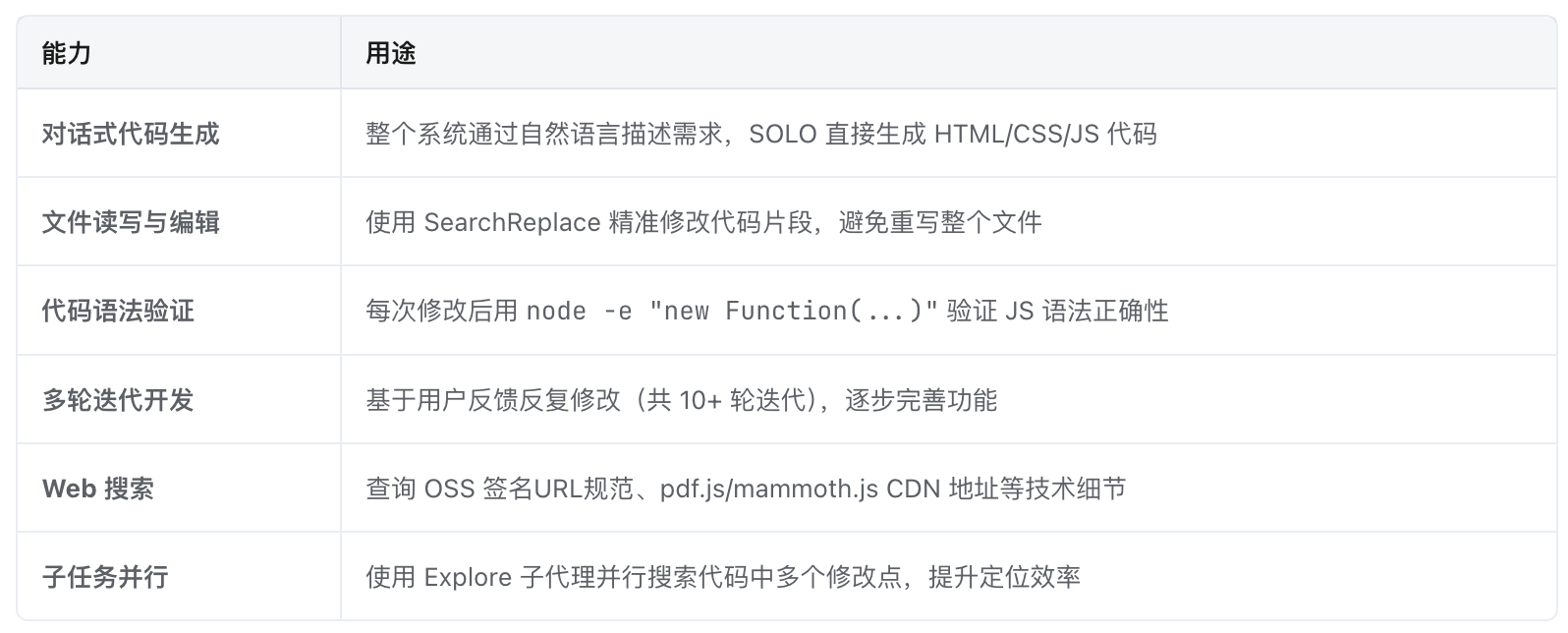
(3)关键prompt与操作过程
a.初始搭建
Prompt:“搭建一个智能简历评估系统,包含简历管理(有效/待定/通过/不通过四栏看板)、排名总览、数据统计、设置页面,支持多岗位管理、大模型自动打分和分类。”
操作:SOLO 一次性生成约 3000+ 行的单文件 HTML 应用,包含完整的侧边栏导航、四栏看板布局、卡片式简历展示、候选人详情页、评分系统、排名视图、统计图表和设置页面。
b.大模型集成
Prompt:“接入用户自定义的大模型API(兼容OpenAI格式),实现简历信息提取、三维打分、智能分类、面试问题生成和评估报告。”
操作:在设置页添加 LLM 配置表单(Base URL、API Key、模型名),封装 callLLM() 函数统一处理 API 调用,所有 AI 功能通过该函数与任意兼容 OpenAI 格式的大模型通信。
c.三维打分 Prompt
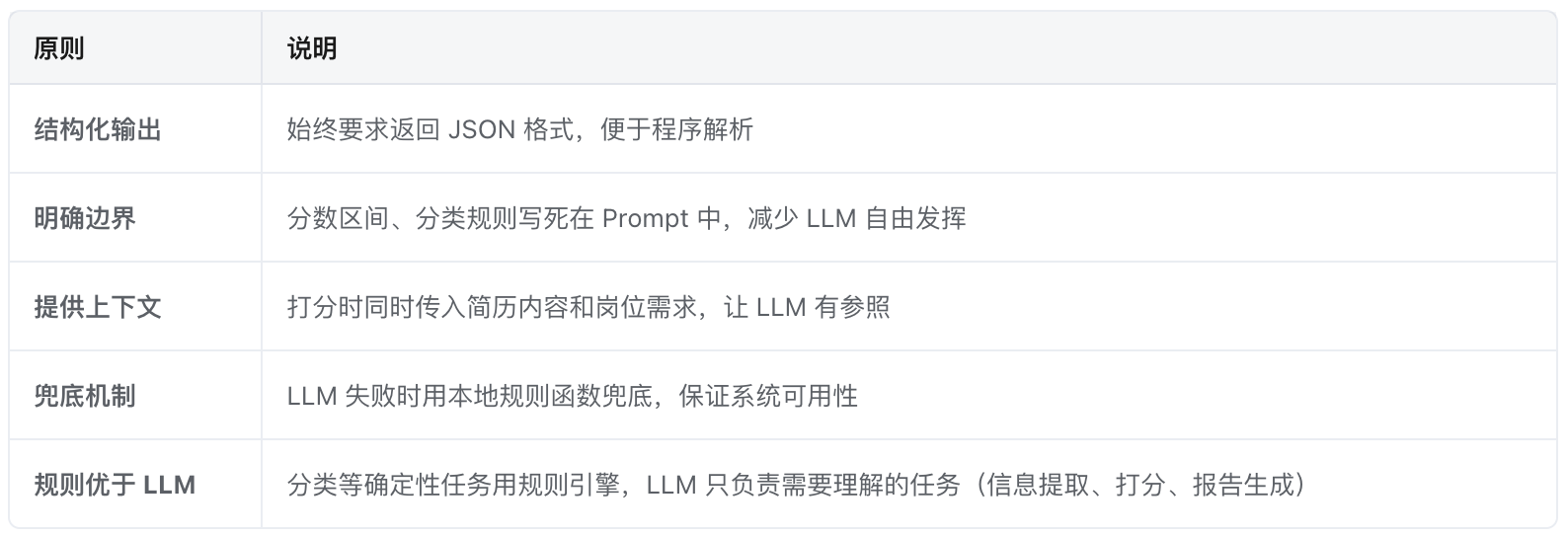
这是整个系统最核心的 Prompt,经过多轮反馈不断优化:
最终版:"请根据候选人简历和目标岗位需求,严格按照以下标准打分:
核心能力(满分100,权重60%):30-45分=完全无关 / 46-59分=有点关联 / 60-75分=较为相关 / 76-100分=高度匹配
稳定性(满分100,权重30%):6维度加权(任职时长40%、职业连贯性25%、空窗期15%、成长性10%、背景稳定性5%、第一份工作5%)
软性素质(满分100,权重10%):文字表达30%、逻辑结构30%、自我评价积极性25%、成果导向15% 只返回JSON:{“core”:分数,“stable”:分数,“soft”:分数}"
踩坑:早期版本 LLM 对不相关候选人也打高分,原因是 Prompt 没有强制对照岗位需求。加入详细分档标准和"不相关岗位不超过40分"的硬约束后才解决。
d.简历分类——从 LLM 到规则引擎
早期 Prompt:“根据岗位需求判断候选人是否符合条件,返回 valid 或 pending。”
踩坑:LLM 分类逻辑混乱,不满足硬性要求的简历被分到"有效",满足的反而被分到"待定"。
最终方案:完全放弃 LLM 分类,改用确定性规则:
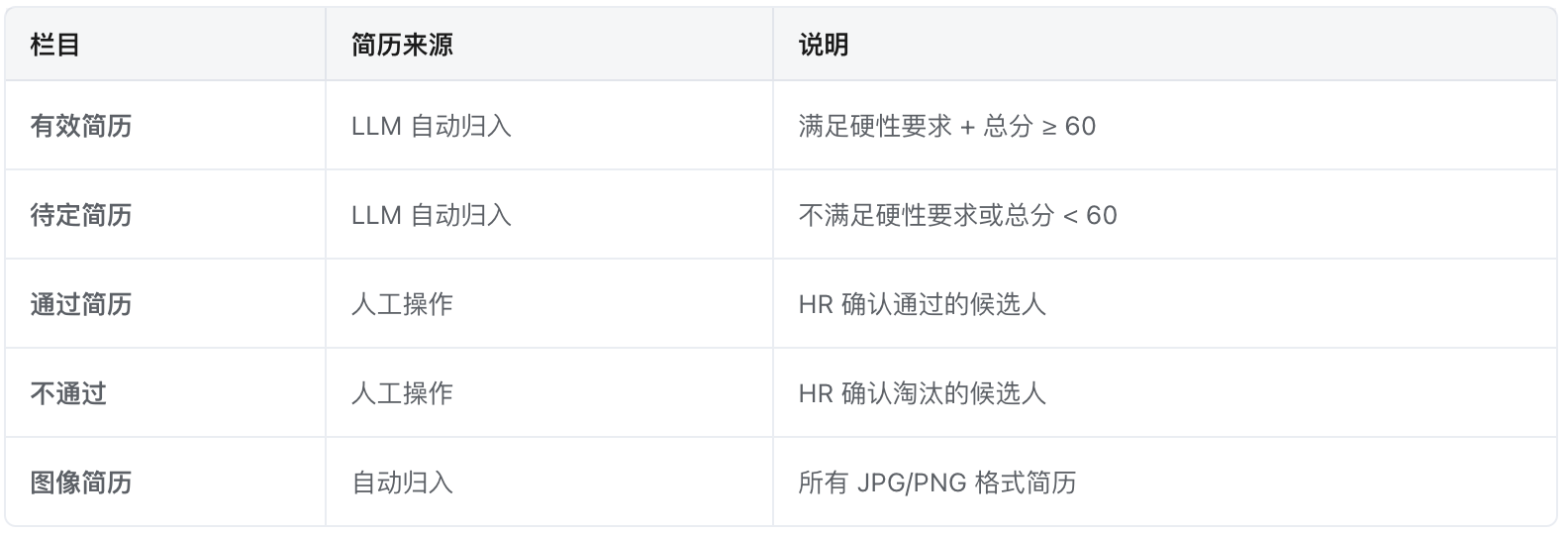
图片简历 → 直接有效
不满足硬性要求(学历/年龄/应届)→ 待定
总分 ≥ 60 → 有效
其余 → 待定
e.文件解析
Prompt:“引入 pdf.js 和 mammoth.js,在浏览器端提取 PDF 和 DOCX 的文字内容,发给大模型分析。不要存 base64 到内存,只存纯文本。”
操作:通过 CDN 引入两个库,导入文件时用 ArrayBuffer 读取 → 提取文字 → 存入 fileContent → 发给 LLM。图片简历跳过提取,只存文件类型标记。
f.OSS 云存储签名 URL
Prompt:“生成阿里云 OSS 签名 URL,解决私有 Bucket 的 AccessDenied 问题。”
踩坑:URL 签名中错误地包含了 x-oss-date 头,导致签名不匹配。OSS 返回的 StringToSign 显示格式应为 GET\n\n\nExpires\n/Resource,不能有 CanonicalizedOSSHeaders。
修复:移除 URL 签名中的 x-oss-date,并添加 response-content-disposition=inline 参数让浏览器直接显示图片而非下载。
g.数据持久化
Prompt:“页面刷新后简历数据不丢失,未打分的简历自动继续打分。”
操作:
新增 loadResumes()/saveResumes() 函数,使用 localStorage 存储
在列表渲染、备注保存、简历移动时自动调用 saveResumes()
保存时排除 fileDataUrl(base64)避免 localStorage 溢出
页面初始化时扫描未打分简历,自动触发 LLM 续打分
h.智能报告与面试问题
报告 Prompt:“结合候选人简历和目标岗位需求生成评估报告。优势/劣势分析必须结合岗位需求,评分与三维评分一致。”
面试问题 Prompt:“根据候选人简历和目标岗位需求生成8个面试问题:≥3个围绕岗位核心能力、≥2个挖掘潜力、≥2个深挖项目经验、≥1个考察岗位理解。”
(4)踩坑
坑1:LLM 打分严重偏高
现象:候选人之前做销售,应聘算法工程师,LLM 仍然给出 80+ 分。
原因:早期 Prompt 只写了"根据简历打分",没有强制 LLM 对照岗位需求。LLM 倾向于"看谁都好"——学历好就加分、公司好就加分,完全忽略岗位匹配度。
解决:经过 4 版 Prompt 迭代,最终在 Prompt 中写死四个分档区间(30-45/46-59/60-75/76-100),并加入硬约束"从事完全无关岗位不超过40分"。同时要求 LLM 同时接收简历内容和岗位需求作为输入,而非只看简历。
坑2:LLM 分类逻辑混乱
现象:不满足学历硬性要求的简历被分到"有效",满足要求的反而被分到"待定"。
原因:让 LLM 做分类判断,但 LLM 对"有效/待定"的理解每次都不一样,缺乏一致性。
解决:彻底放弃 LLM 做分类,改用确定性规则引擎:
图片简历 → 直接有效
不满足硬性要求(学历/年龄/应届)→ 待定
总分 ≥ 60 → 有效
其余 → 待定
LLM 只负责它擅长的事(信息提取、打分、报告生成),分类这种确定性任务交给代码逻辑。
坑3:OSS 签名 URL 签名不匹配
现象:访问图片时 OSS 返回 The request signature we calculated does not match the signature you provided。
原因:在 URL 签名中错误地加入了 x-oss-date 头。OSS 的 Header 签名和 URL 签名是两种不同格式:
Header 签名:VERB\nMD5\nType\nDate\nHeaders\nResource
URL 签名:VERB\n\n\nExpires\nResource(没有 Headers,没有 Date)
我们混用了两种格式。
解决:URL 签名中移除 x-oss-date,只保留 Expires 和 CanonicalizedResource。
坑4:私有 Bucket 图片触发下载而非显示
现象:签名 URL 能访问了,但浏览器直接下载图片而不是显示。
原因:OSS 私有 Bucket 默认的 Content-Disposition 是 attachment。
解决:在签名 URL 中添加 response-content-disposition=inline 参数,并确保该参数参与签名计算(作为 OSS 子资源)。
坑5:base64 内存溢出
现象:导入多份 PDF/图片后,浏览器越来越卡,最终崩溃。
原因:早期版本将每个文件读取为 base64 DataURL(一个 PDF 可能 5-10MB),全部存入简历对象的 fileDataUrl 字段。导入 20 份简历后内存占用超过 200MB。
解决:导入时只提取纯文本(几 KB),不存 base64。图片/PDF 预览通过云端签名 URL 实现。保存到 localStorage 时也排除 base64 字段。
坑6:页面刷新后数据全部丢失
现象:辛苦导入并打完分的简历,刷新页面后全部消失,回到默认示例数据。
原因:resumes 变量通过 createResumes() 硬编码初始化,没有任何持久化逻辑。
解决:新增 loadResumes()/saveResumes() 函数,使用 localStorage 存储。在列表渲染、备注保存、简历移动等操作时自动保存。页面加载时优先从 localStorage 读取,无数据才用默认示例。
坑7:未打分简历刷新后不会继续打分
现象:导入 30 份简历,LLM 只打完了 10 份就刷新了页面,剩下的 20 份永远不会被打分。
原因:打分逻辑只在导入时触发,刷新后不会重新检查。
解决:在页面初始化时添加自动扫描——找出 core === 0 || stable === 0 || soft === 0 的简历,自动触发续打分。每打完一份立即 saveResumes(),中途再刷新也不会丢失已完成的分数。
4.成果展示:
系统支持从本地文件批量导入 PDF、DOCX、TXT、JPG、PNG 等格式的简历,自动提取候选人信息并按岗位需求进行三维量化打分——核心能力(权重60%)、稳定性(权重30%)、软性素质(权重10%),总分满分100。基于岗位硬性要求(学历、年龄、应届)和总分阈值,系统自动将简历分类到有效、待定、通过、不通过四个栏目,图像简历独立归档。系统还能结合岗位需求生成针对性面试问题和智能评估报告,帮助 HR 深入了解候选人。所有数据自动持久化到浏览器本地,刷新不丢失。系统支持多岗位管理、多维度筛选排名和数据统计,通过大模型驱动实现从简历导入到智能评估的全流程自动化,显著提升招聘筛选效率。
采用AI生成的简历演示,不涉及个人隐私。
(1)岗位管理
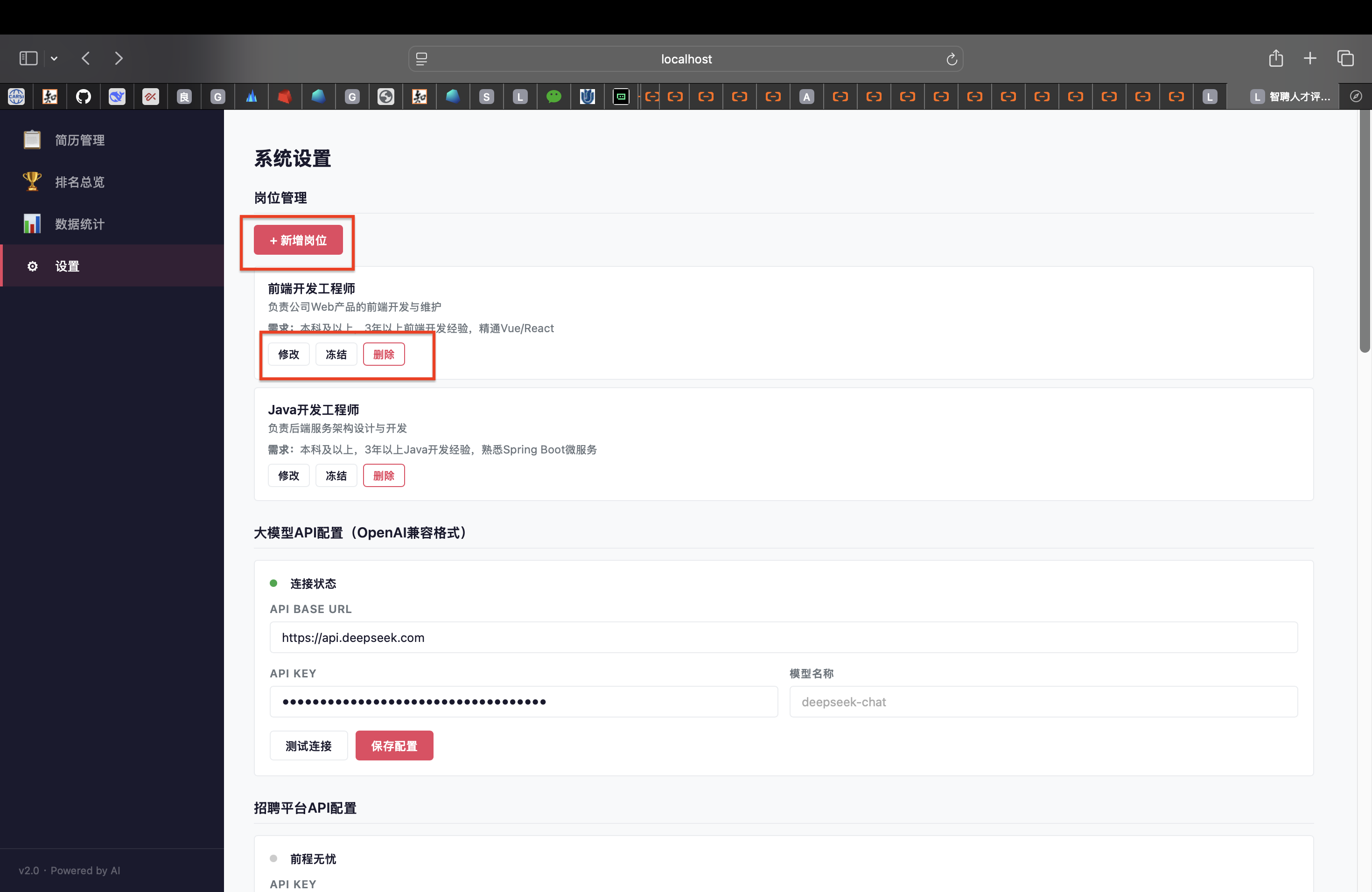
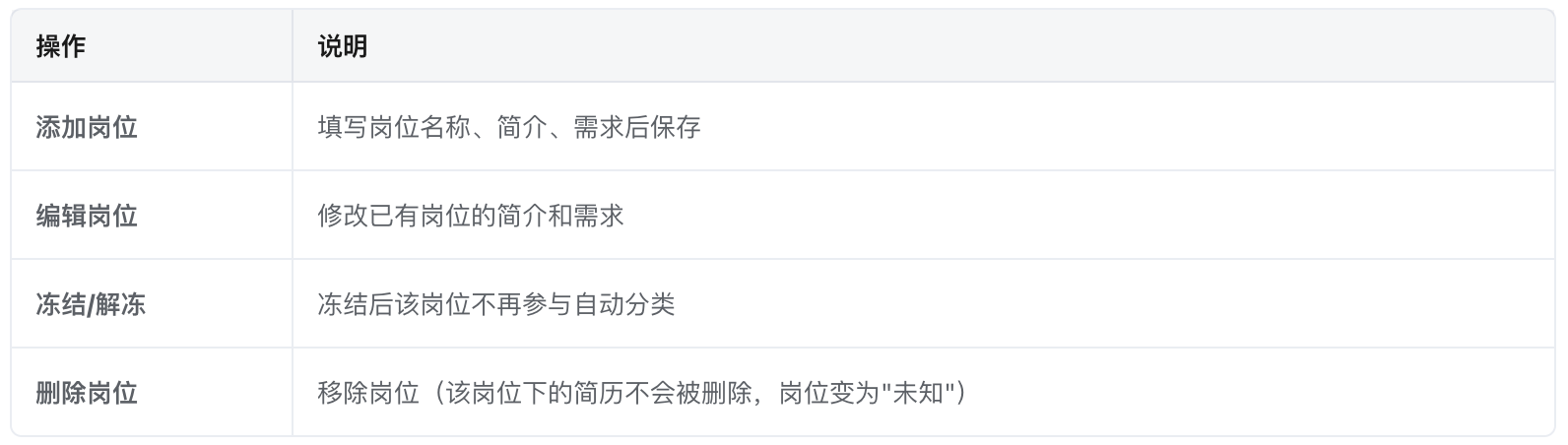
注意:打分标准、简历分类、智能报告和面试问题的生成质量都依赖岗位需求的描述。
a.新增岗位后
新导入的简历会被 LLM 自动匹配到最适合的岗位(包括新岗位)
已有"未知"岗位的简历不会自动重新匹配
b. 编辑岗位需求后
系统会弹窗提示是否重新评估该岗位下的简历
点击确认后:
所有有效/待定简历会被重新打分(LLM 按新需求三维打分)
按新的硬性要求 + 总分重新分类(有效/待定)
通过/不通过的简历不受影响
图片简历跳过打分,保持原有状态
c. 冻结岗位后
新导入的简历不会被 LLM 分配到该岗位
该岗位下的已有简历不受影响,仍可正常查看
d. 删除岗位后
该岗位下的所有简历,岗位字段变为"未知"
这些简历的评分和分类保持不变
需要手动重新分配或等下次编辑时触发重新评估
(2)首次配置(由于本人无招聘端账号,故前程无忧、猎聘、boss直聘、邮箱api连接未测试)
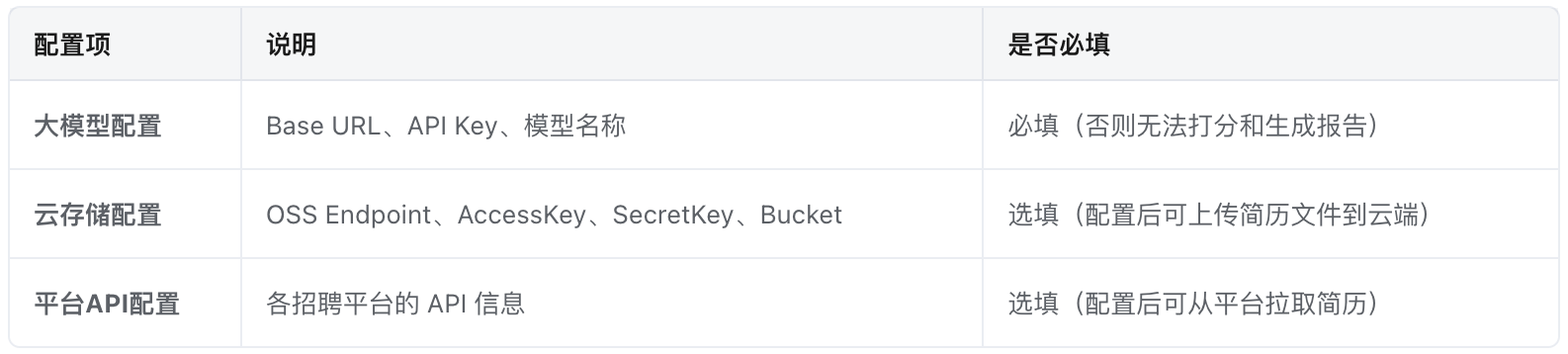
大模型配置:打分、信息提取、岗位分类、智能报告、面试问题生成——所有 AI 功能都依赖此配置。
云储存配置(OSS):仅影响图片简历的云端显示和文件上传功能。不配置时图片简历无法预览,但不影响打分和分类。
平台API配置(此项功能未测试):配置后可直接从平台拉取简历,无需手动导入文件,不配置时可手动导入本地文件。
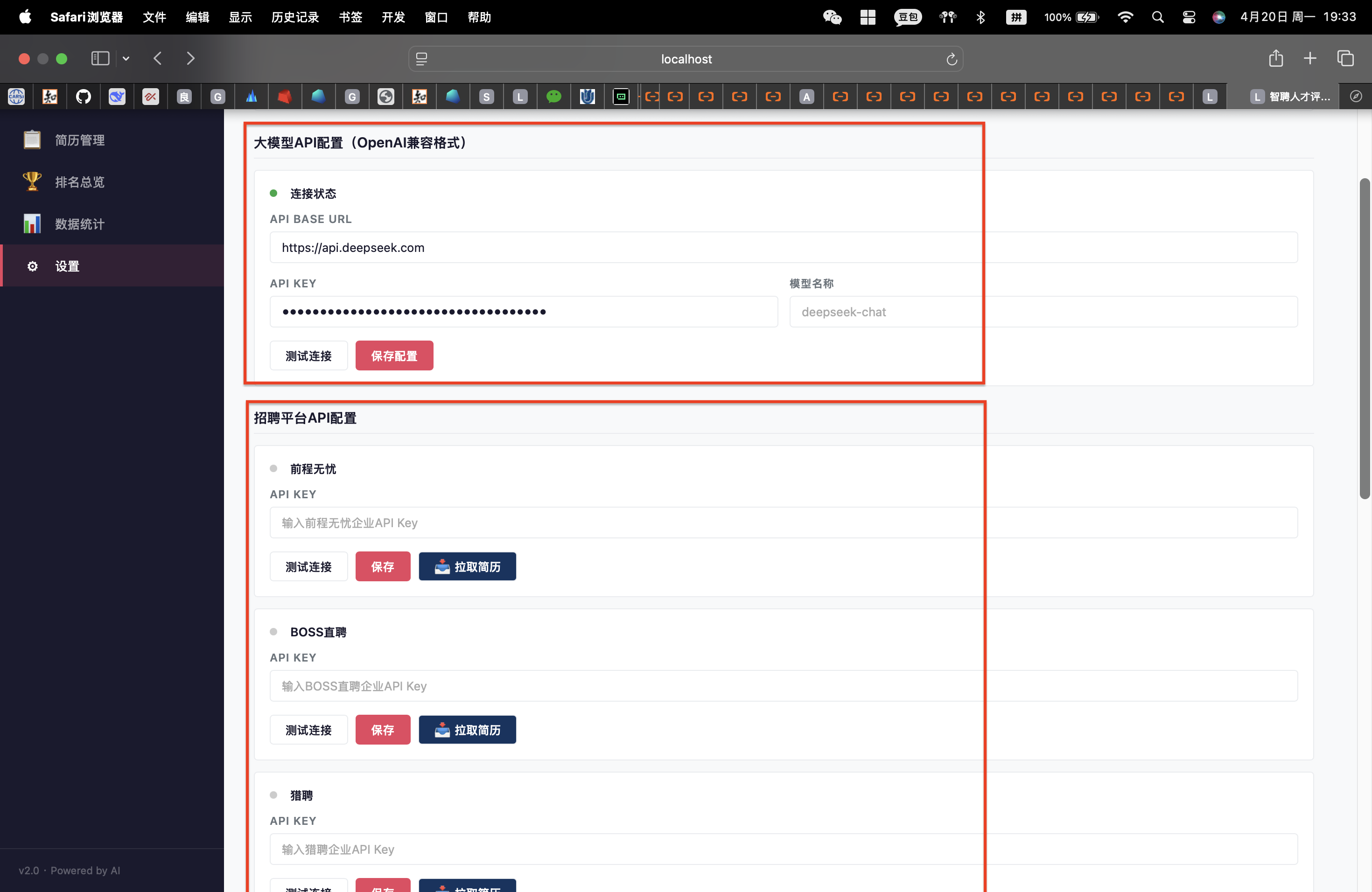
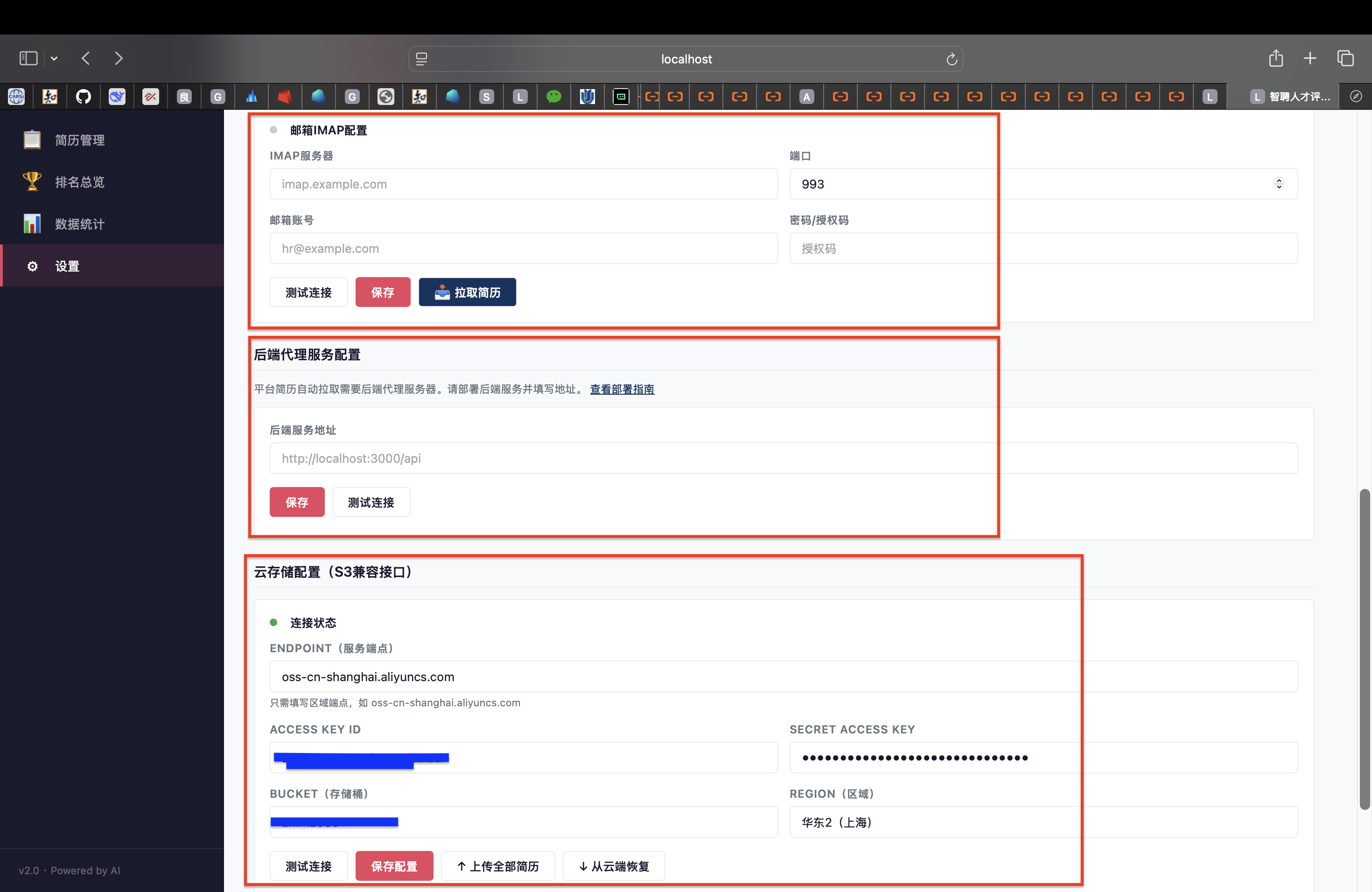
(3)导入简历(仅以本地导入为例)
导入方式:

支持的文件格式:
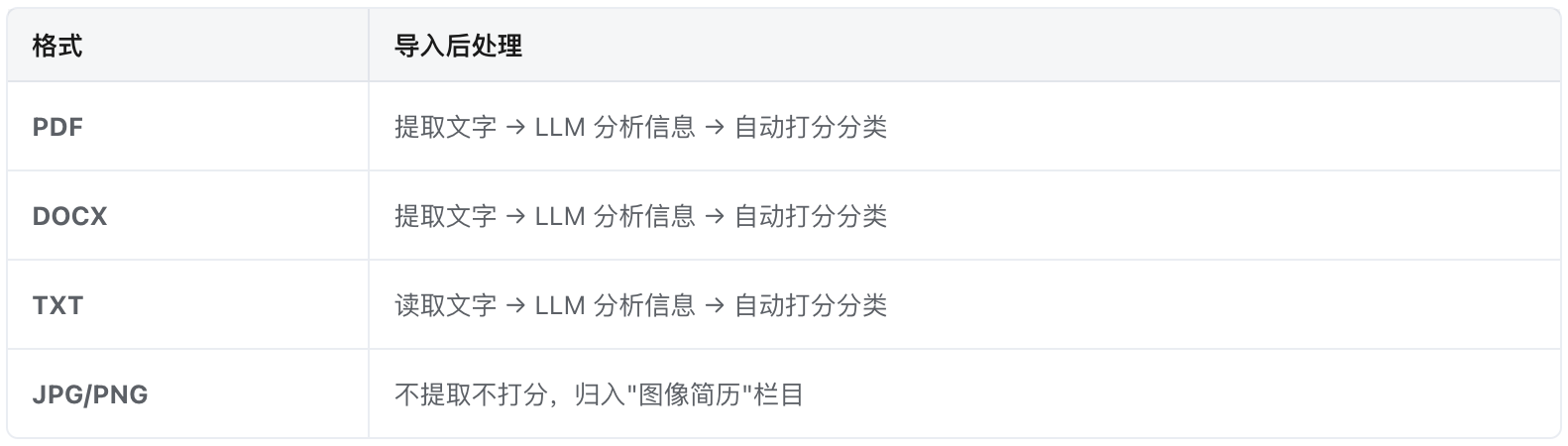
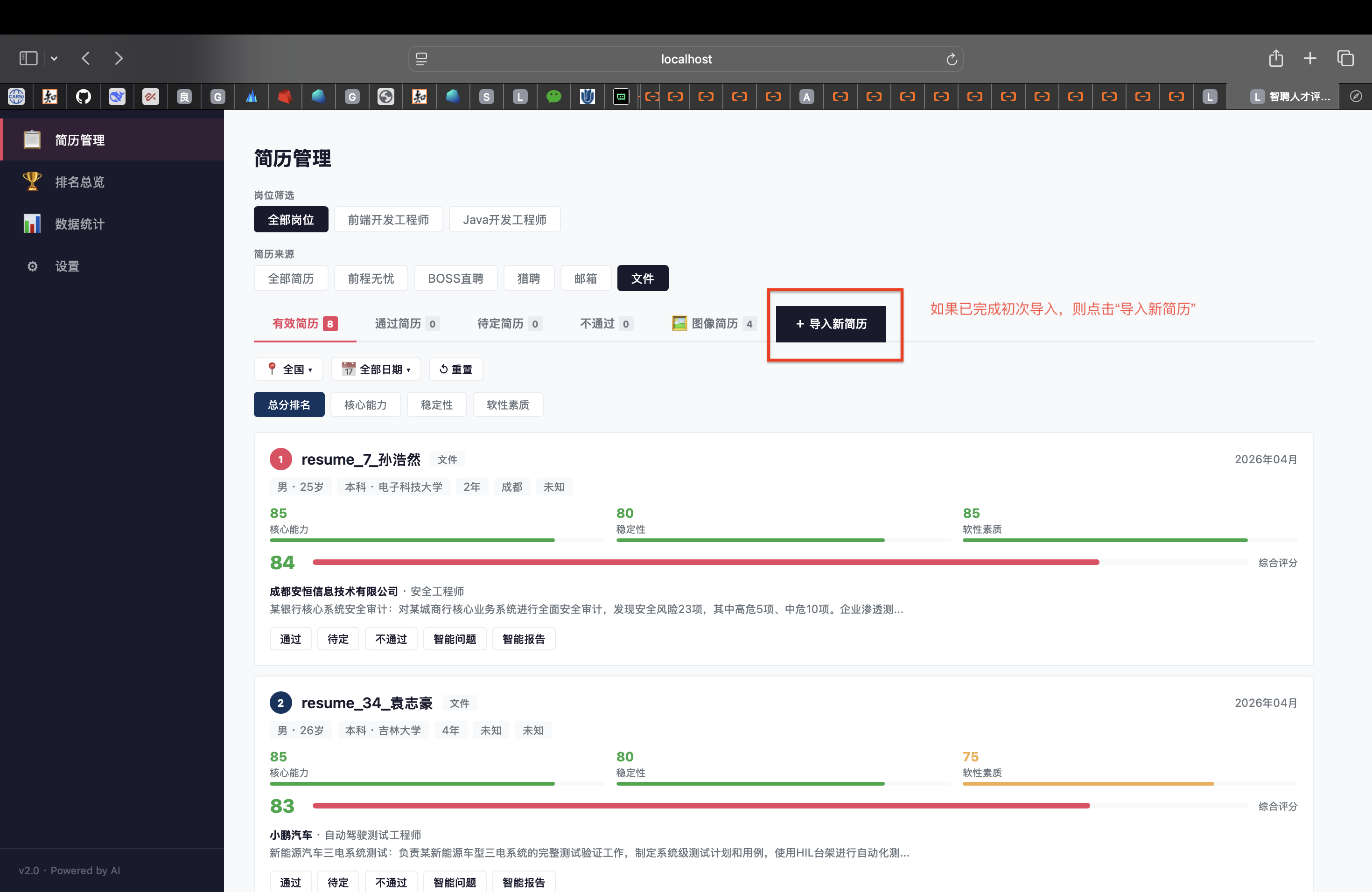
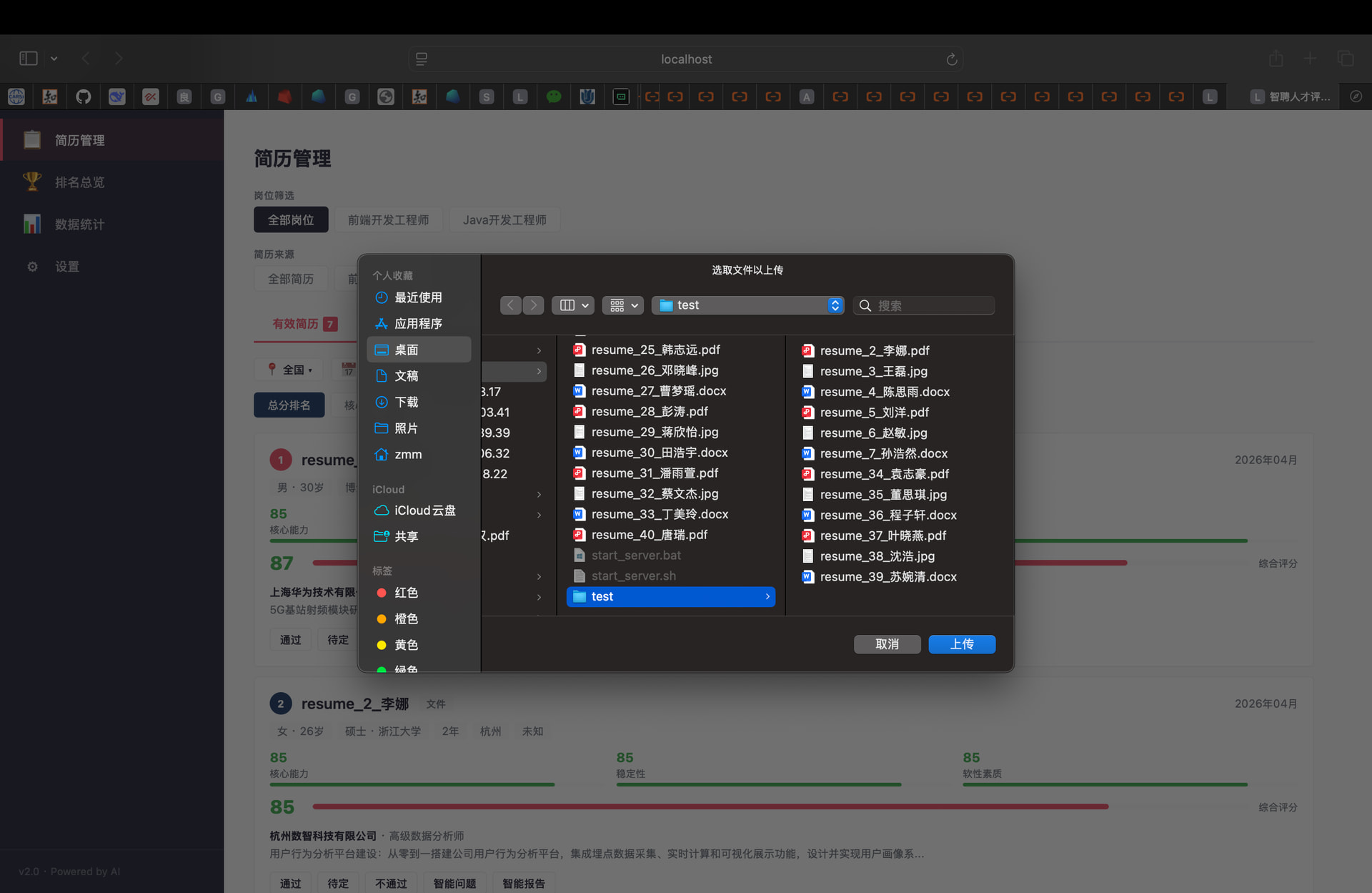
后续处理:
文件导入
↓
① 文字提取(PDF/DOCX/TXT)
↓
② LLM 信息提取 → 姓名、学历、经验、城市等自动填入
↓
③ LLM 岗位分类 → 根据简历内容匹配最适合的岗位
↓
④ LLM 三维打分 → 核心能力(60%) + 稳定性(30%) + 软性素质(10%)
↓
⑤ 规则分类 → 满足硬性要求 + 总分≥60 → 有效,否则 → 待定
↓
⑥ 图片简历 → 直接归入"图像简历"栏目
↓
⑦ 云端上传(如已配置OSS)→ 文件上传到云端,支持图片预览
↓
⑧ 数据持久化 → 自动保存到浏览器本地,刷新不丢失
(4)简历管理
a.四栏看板+图像管理:
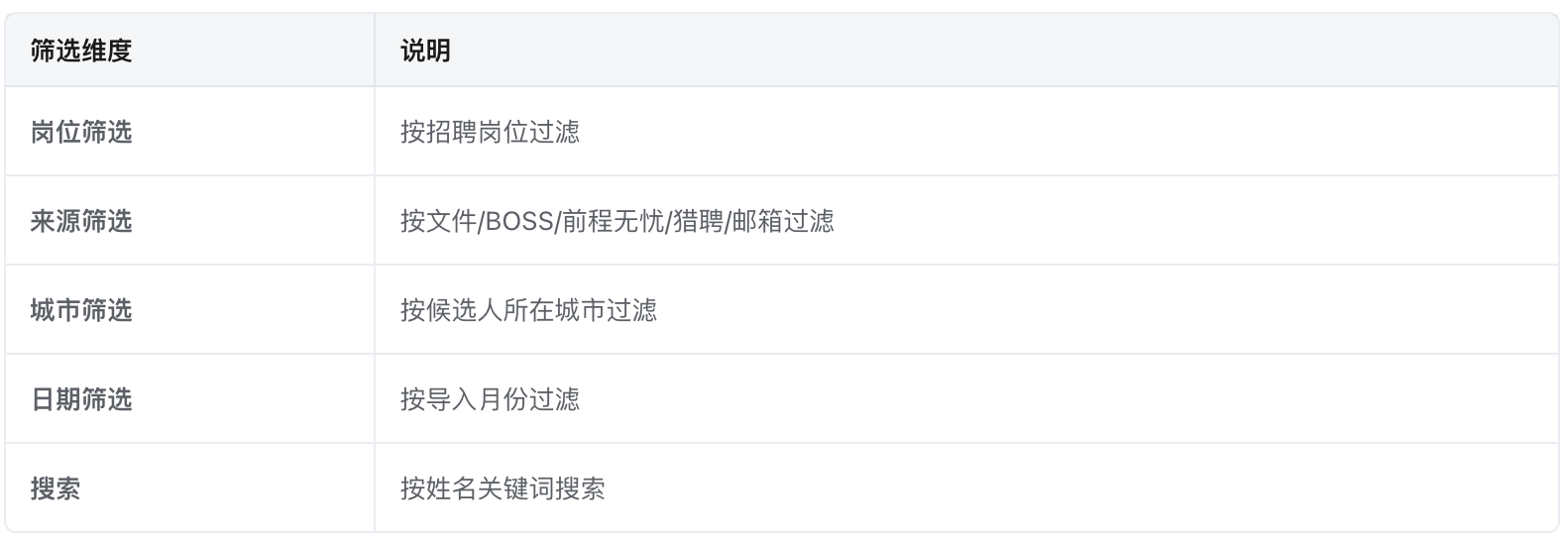
b.筛选功能:
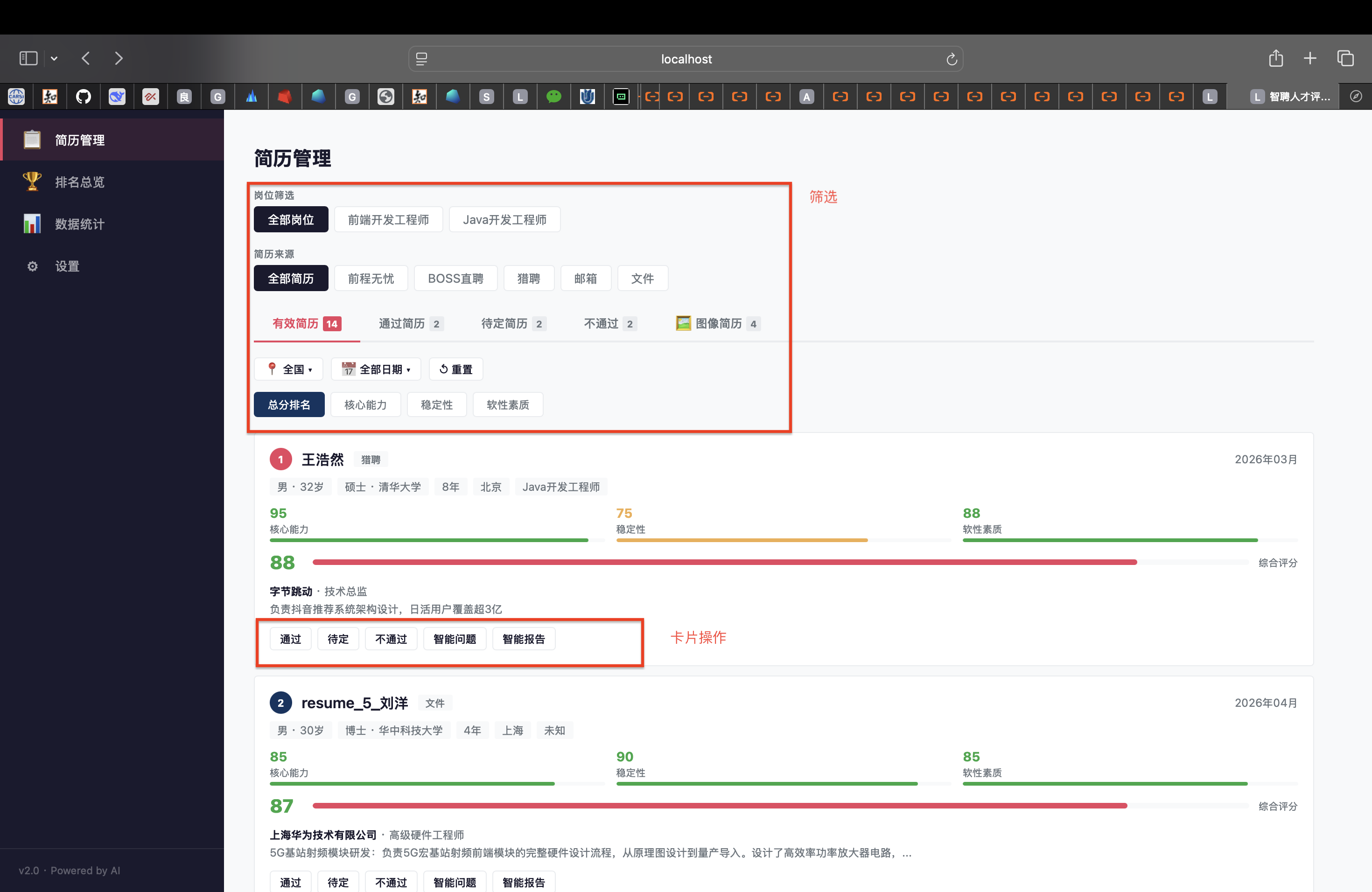
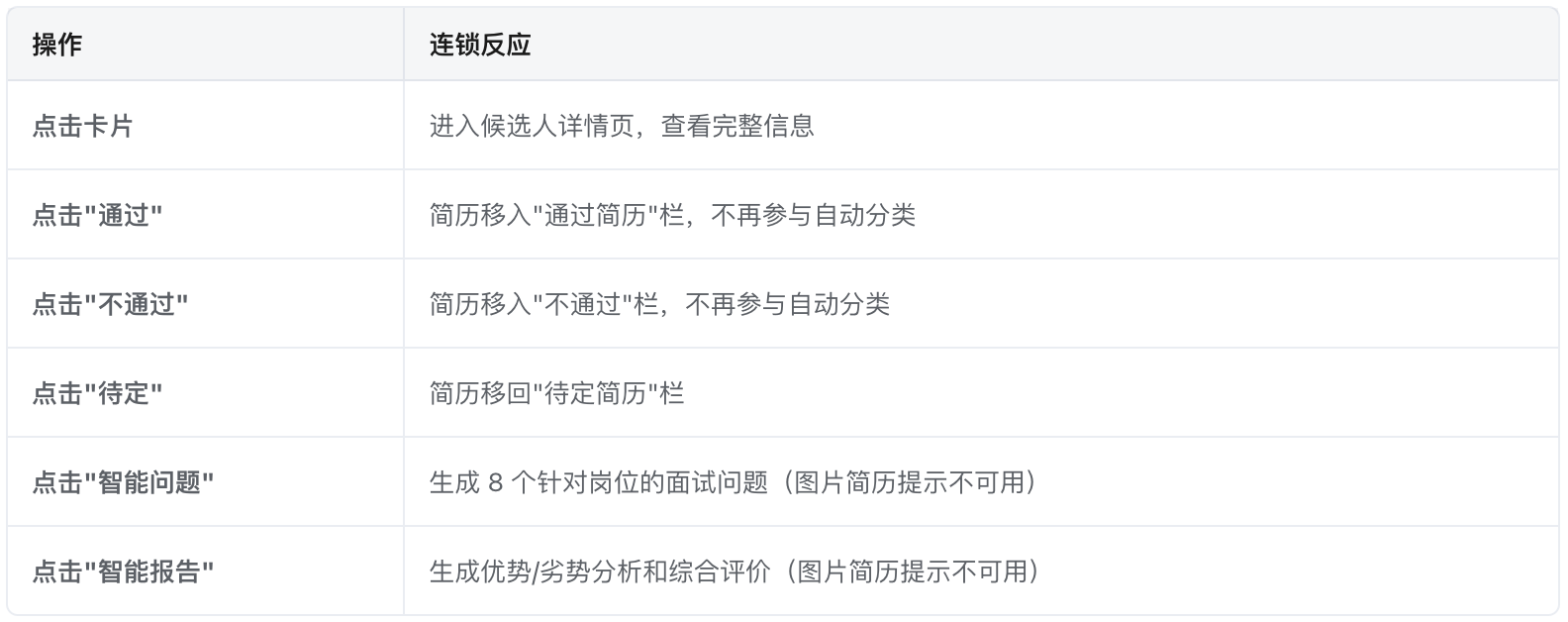
c.简历卡片操作:

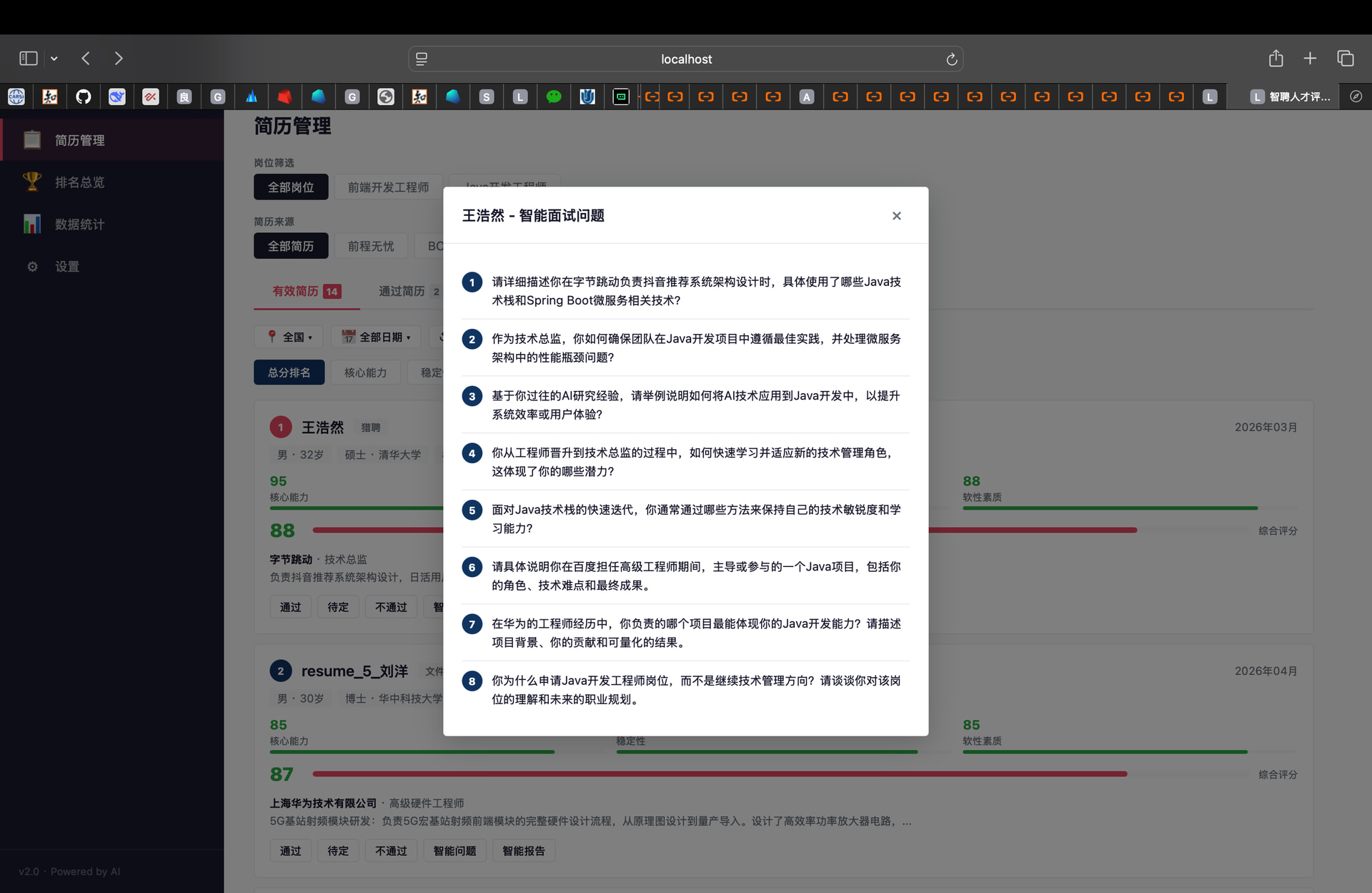
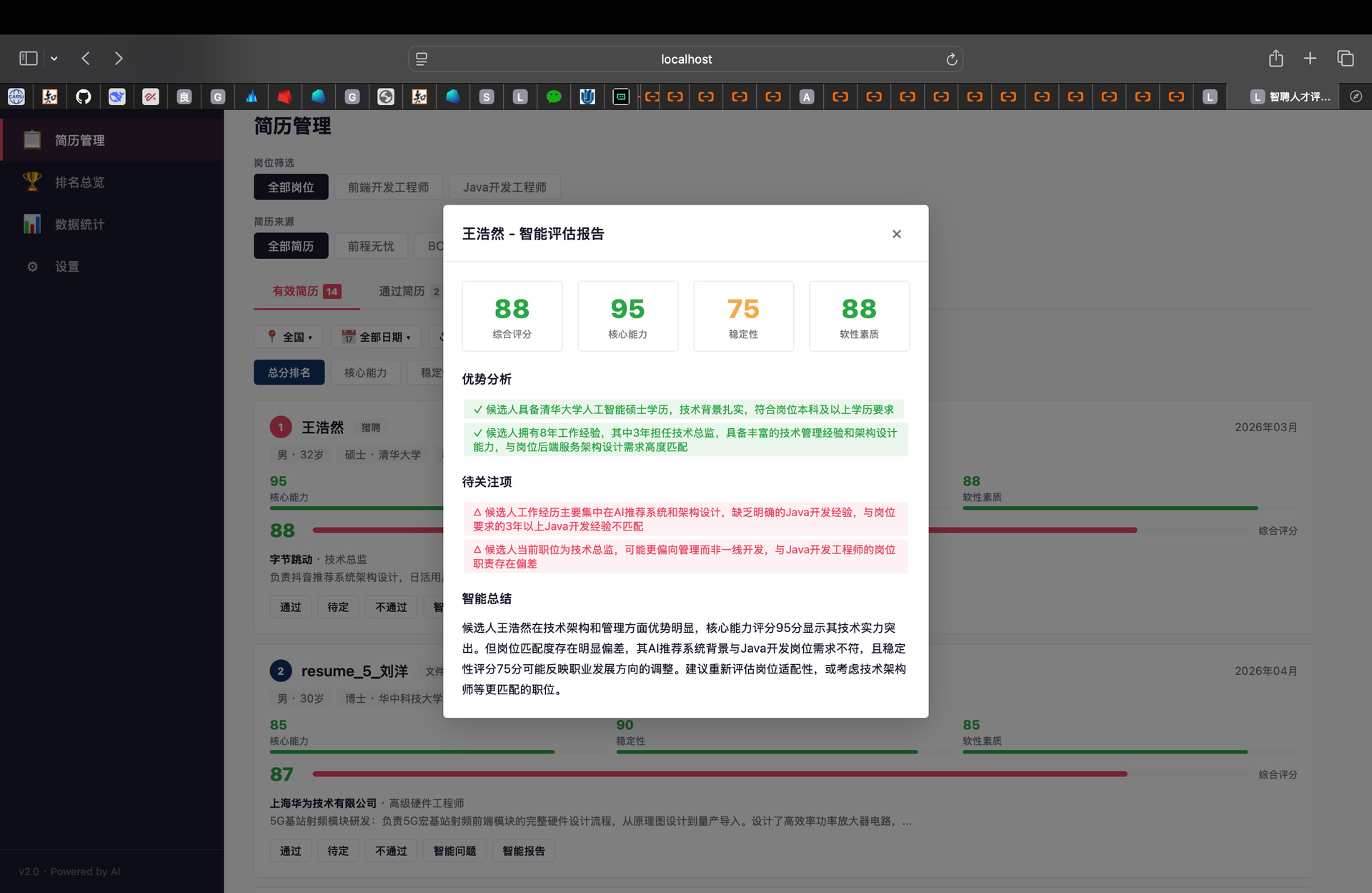
(5)排名总览:
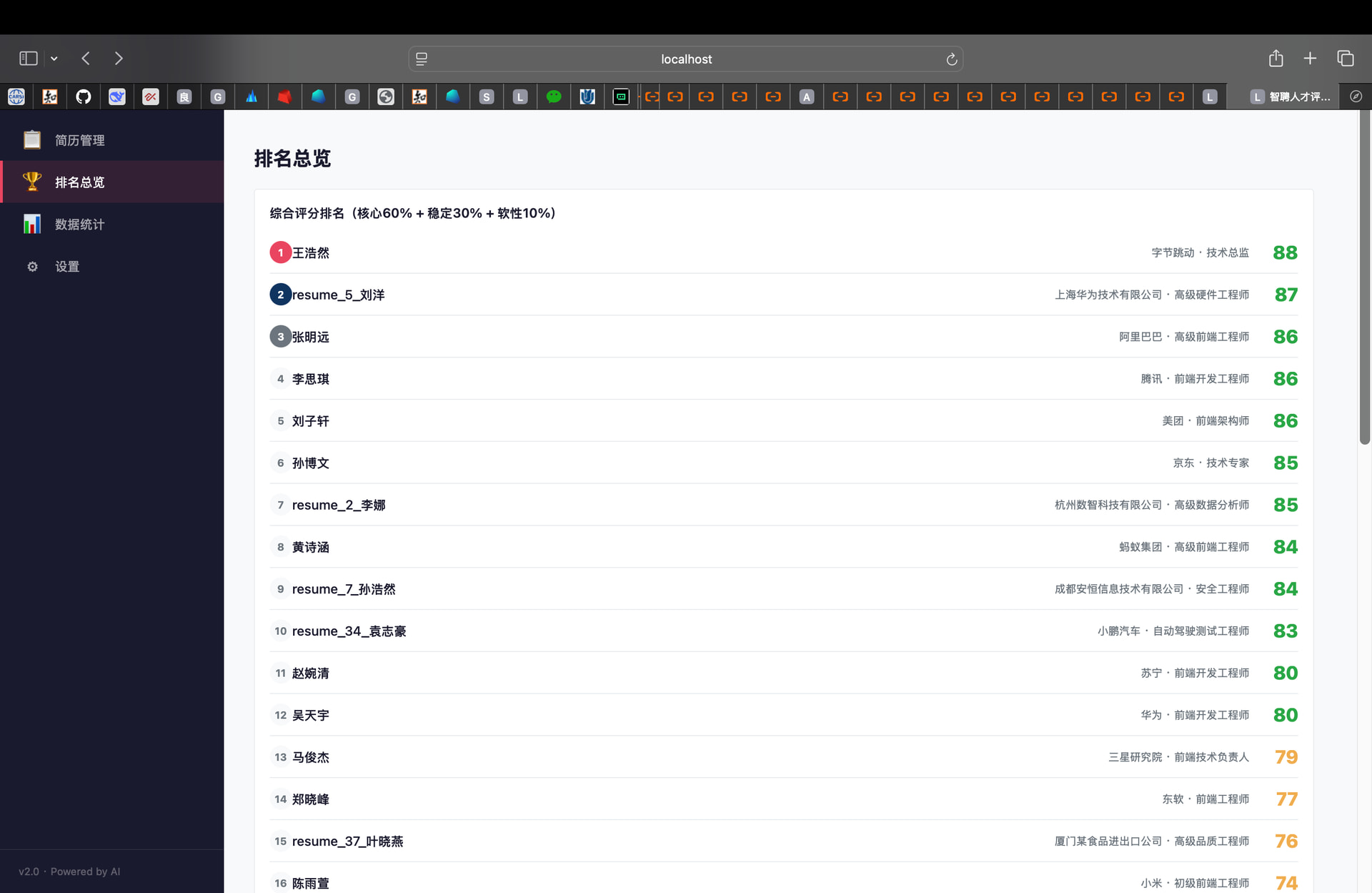
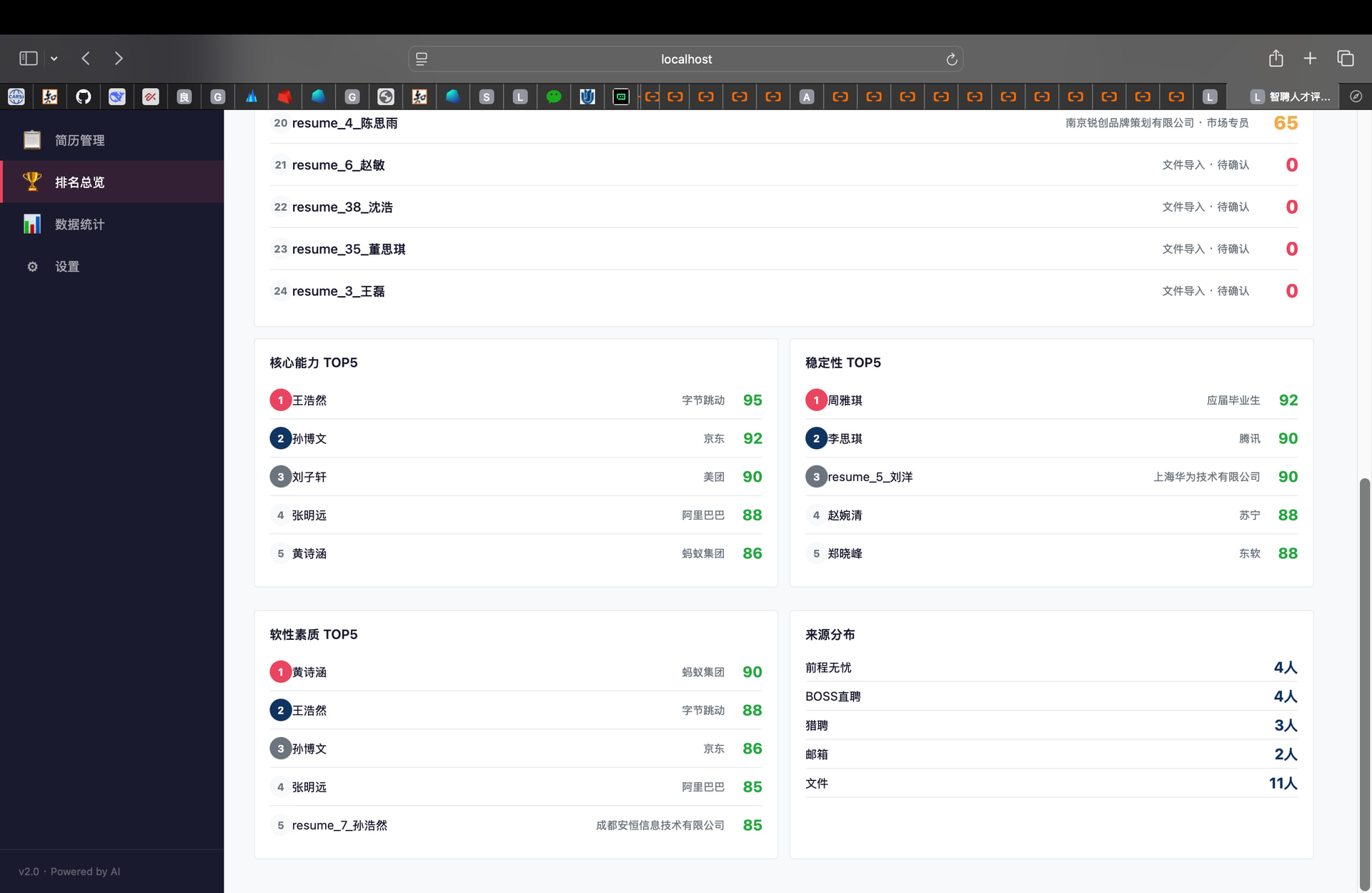
根据已有简历生成排名,包含总分与“核心能力”“稳定性”“软性素质”的排名,以及来源分布数据。
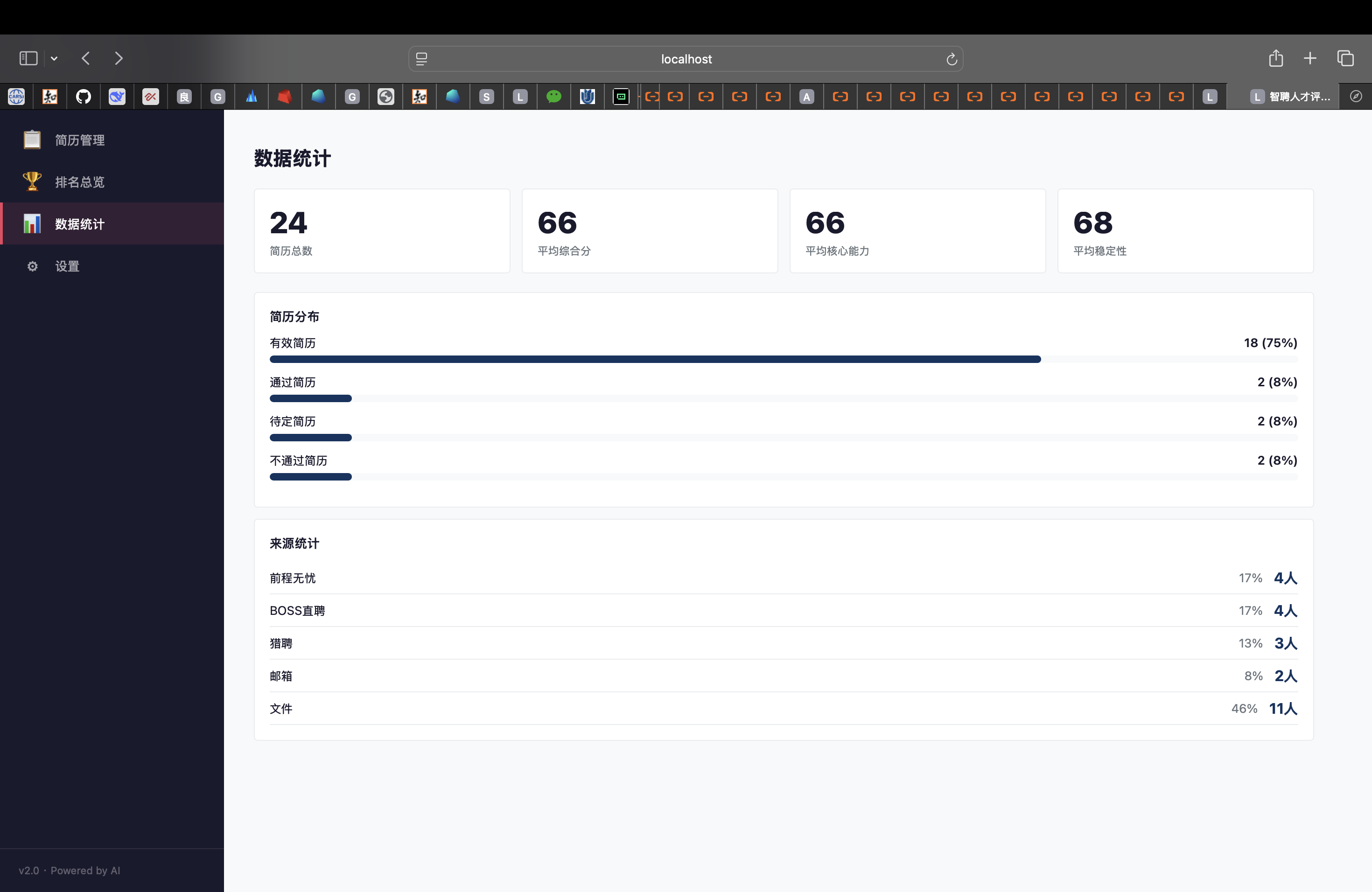
(6)数据统计:
5.总结:
这个项目让我认识到,AI 不是替代思考,而是放大思考的执行力。在这一过程中,我明白了:
(1)需求描述必须具体量化,用明确的分档标准和边界条件替代模糊的形容词,让 AI 精确理解意图;
(2)坚持"规则优于 LLM"的原则,确定性任务交给代码,LLM 只负责需要理解自然语言的工作;
(3)采用小步迭代策略,每次只改一个功能点并立即验证,避免多变量同时修改导致问题难以定位;
(4)把踩坑视为最好的学习素材,每个报错背后都对应一个技术知识点,解决问题的过程本身就是最有效的学习;
(5)遵循"先跑通再优化"的路径,优先实现核心流程端到端贯通,再逐步打磨细节体验。