-
Token节省方法1 :【解决一个重开一个会话,减少陷入死循环,减少历史上下文,减少压缩导致上下文丢失】解决子问题后立即重开,清空无用历史。
-
Token节省方法2 :【个人规则,项目规则,智能体系统提示词,Skills;精简再精简】移除 规则文件 中过期的、过于琐碎的规范。。
-
Token节省方法3 :【控制 MCP 开启数量】 只开启当前任务需要的 MCP 服务器,避免工具定义堆积。
-
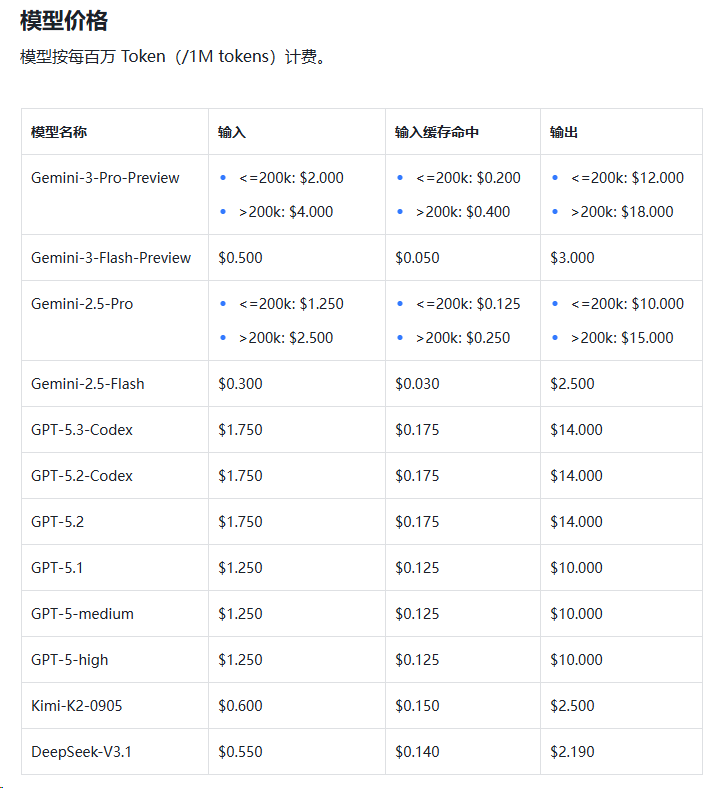
Token节省方法4 :【选择最优模型】别总盯着最贵最大上下文的模型。写个简单脚本就没必要选最重的模型**【该省省该花花】**
-
Token节省方法5: 【主动管理引用】 尽量只 # 相关的函数或文件,而不是整个文件夹,整个项目。
(参考模型价格)
我们顺便看看AI IDE是怎么结构性消耗Token
AI IDE Token 消耗全景图

-
左侧数据输入流向 :分别为(静态、动态、工具)分类。你可以清楚看到,像 规则文件和提示词 这样的静态输入是“持续叠加 ”的,而工具调用(MCP)(Skills)是具备爆发性质的。
-
中央上下文池 :所有的输入都汇聚到中间的大模型循环处理上下文 区域。
-
Agent/反馈 :当你命令 AI “修复所有测试用例”时,AI 会不断运行测试 → 报错 → 回传 → 思考 。在一次又一次循环反馈到测试思考过程,上下文而变得更重。
-
分级影响程度 :
-
蓝色 (核心/静态)【输入】 :底座成本,高消耗 。
-
橙色 (Agent/反馈)【输入输出】 :最容易失控的变动成本,陷入AI自我循环即空消耗 。
-
紫色 【输出】 :实际产生的价值(代码),但在 Token 占比中通常最小。
-
绿色【优化】 :唯一能有效降低大量计费措施。
通过这个流向图,你可以发现:AI IDE 的核心省钱逻辑不是让 AI 少写代码(输出),而是让它少读无用信息(输入和反馈)。