① 摘要
该web服务面向求职者特别是没有经验的大学生,在岗位分析 → 简历诊断 → 行动规划 → 模拟面试 → 简历优化的全链路场景下提供 AI 驱动的辅助能力,目前通过 18 个单元测试全部通过 + Vercel 线上部署验证有效,经过真实求职者试用得到不错的评价。
在线地址:https://career-ai-ecru-delta.vercel.app
② 真实场景与需求
目标人群: 正在求职的应届生、转行者、希望系统提升面试能力的职场人
痛点描述:
-
看到岗位 JD 一头雾水——“精通微服务”"有高并发经验"到底要求到什么程度?
-
不知道自己的简历和目标岗位差在哪里,盲目海投
-
面试前没地方练习,找朋友 模拟 又不好意思反复麻烦人家
-
简历写完不知道是否符合目标岗位的口味
现有做法及不足:
-
用 ChatGPT/Claude 单独问每个问题——零散、无上下文关联、每次要重新描述背景
-
找人帮忙看简历——依赖他人时间,难以多次迭代
-
刷面经——题目固定、没有针对性评分反馈
③ 作品介绍
职路 AI(Career AI) — 一个 Web 应用(Vue 3 前端 + FastAPI 后端),包含五大核心模块:
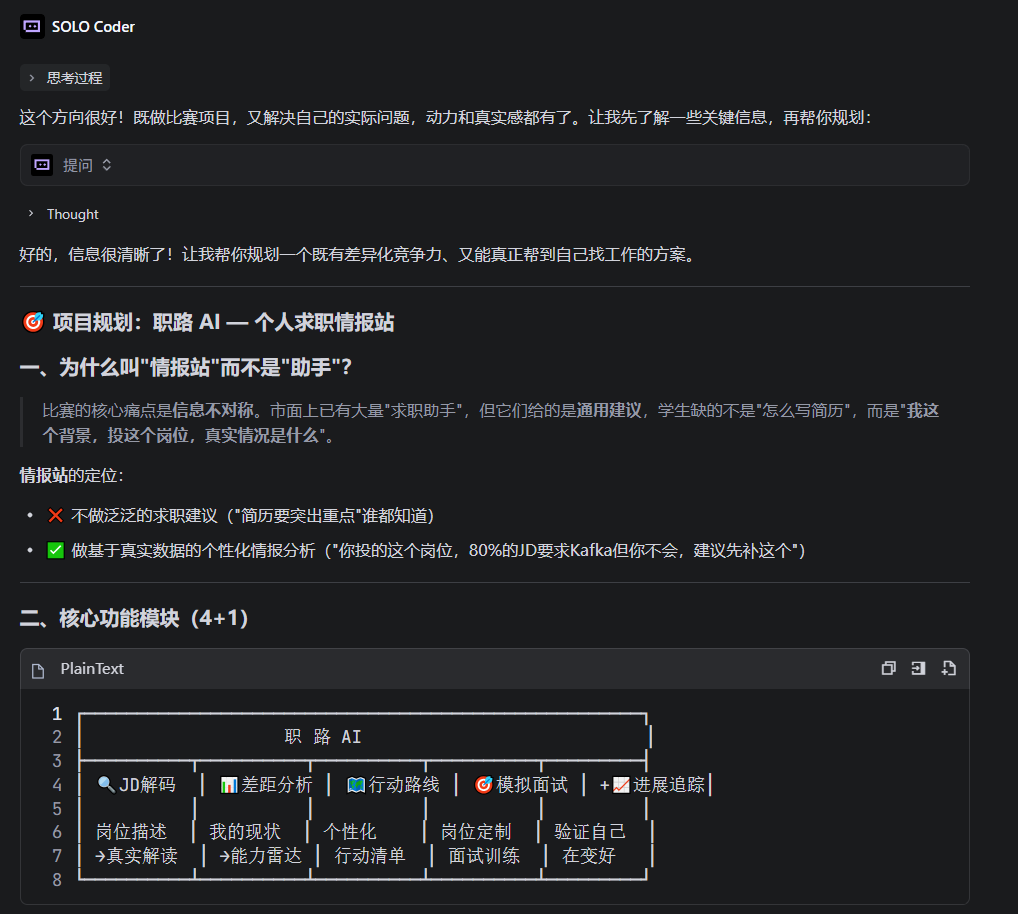
| 模块 | 能力 |
|—|—|
| JD 解码 | 粘贴原始 JD,AI 输出结构化能力矩阵 |
| 差距分析 | 上传简历 vs 目标 JD,输出差距报告 |
| 行动路线 | 基于差距自动生成分阶段提升计划 |
| 模拟面试 | 支持题数/倒计时双模式,实时打分,结束后统一展示每题分数+解析 |
| 简历优化 | 根据目标岗位反向优化简历内容 |
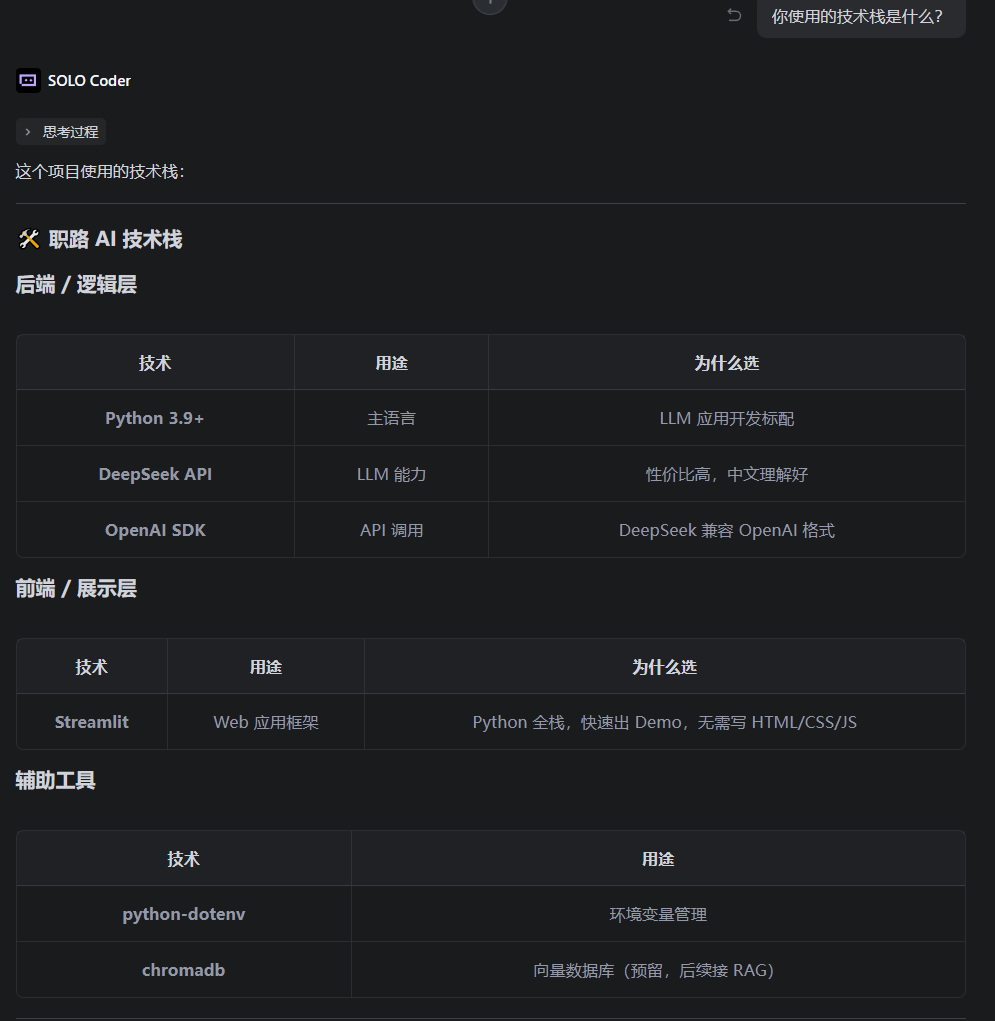
技术栈:Vue 3 + Pinia + FastAPI + DeepSeek API,部署在 Vercel Serverless。
④ 用 Trae 实现的过程
任务拆解
整个开发过程花了一天半的时间,总共分为四个阶段:
阶段一:功能实现与 Bug 修复(Streamlit 版)
↓ 发现架构性问题,决定重构
阶段二:技术栈迁移(Streamlit → FastAPI + Vue 3)
↓ 完成核心功能
阶段三:模拟面试增强(双模式/实时评分/题目多样性)
↓ 功能稳定,进入质量保障
阶段四:测试 + 清理 + 部署上线
关键过程记录
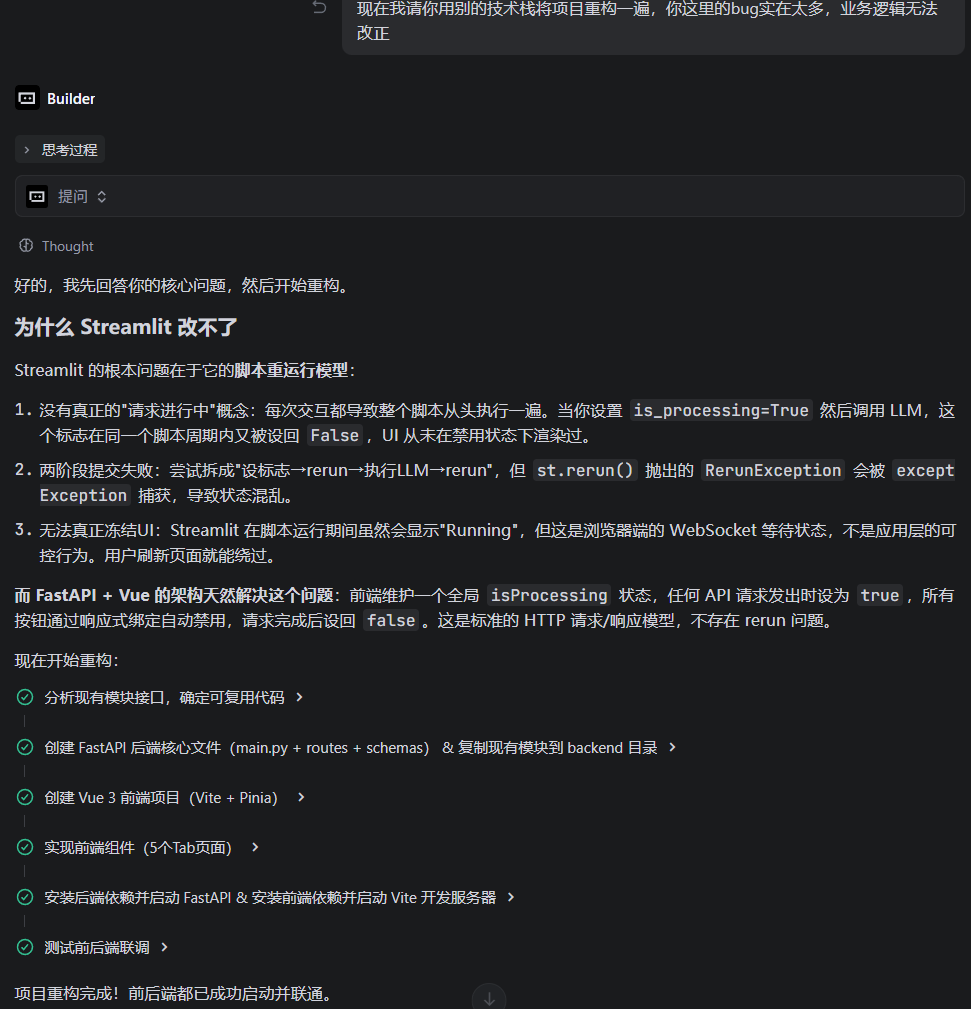
 阶段一:从 Streamlit 到 FastAPI 的重构决策
阶段一:从 Streamlit 到 FastAPI 的重构决策
最初我的项目是基于 Streamlit 开发,那时候只想随便做个demo出来,但在迭代过程中暴露了几个根本性缺陷:
核心问题:并发控制。 Streamlit 是单线程框架,当 LLM 调用在执行时(比如差距分析需要 10-20 秒),用户可以同时点击其他按钮(JD 解码、简历优化等),导致业务状态混乱——JD 解码到一半换了新 JD,差距分析的依据都变了。我用trae进行调整的时候,它几乎陷入了一种更改恢复再更改回去的循环
尝试过多种修复方案(状态锁、两阶段提交、手动触发代替自动),但 Streamlit 的 rerender 机制让这些方案始终不稳定。最终决定整体迁移到 FastAPI + Vue 3:
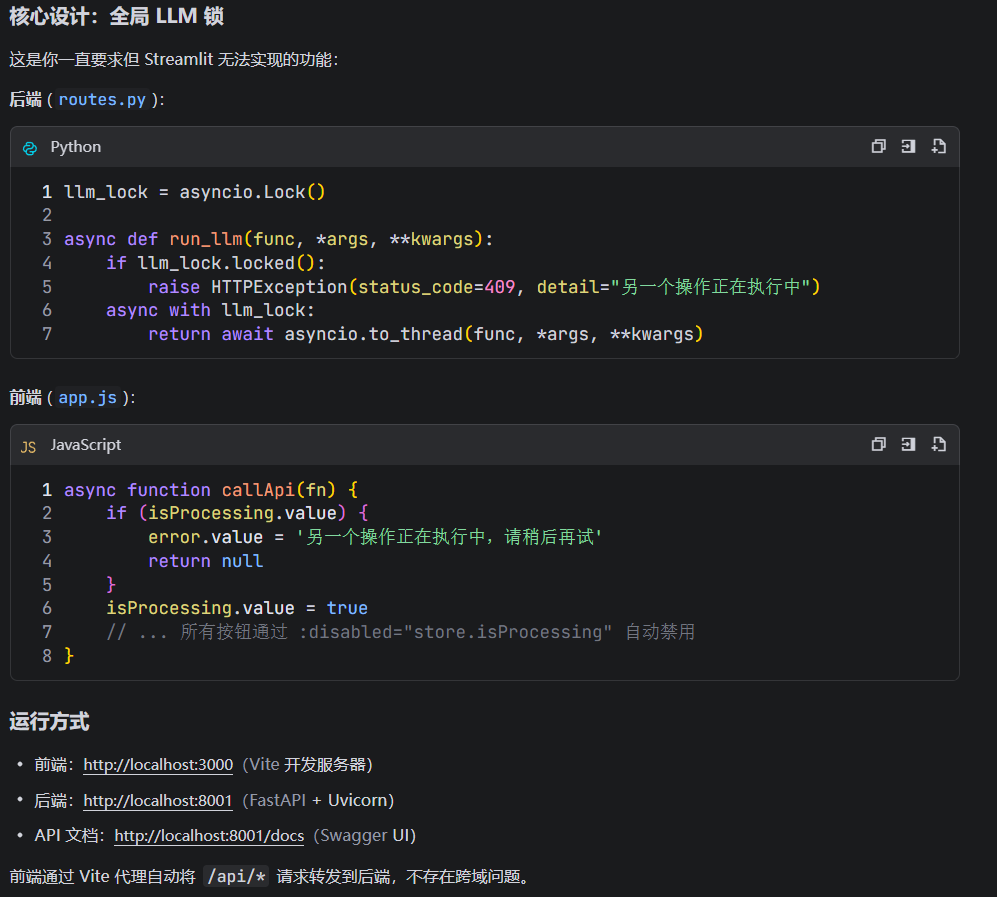
-
后端用
asyncio.Lock实现全局 LLM 并发锁,简单可靠 -
前端用 Pinia 统一管理状态,按钮禁用/加载态一目了然
-
RESTful API 设计,前后端解耦,各自独立迭代
 阶段二:模拟面试功能的深度打磨
阶段二:模拟面试功能的深度打磨
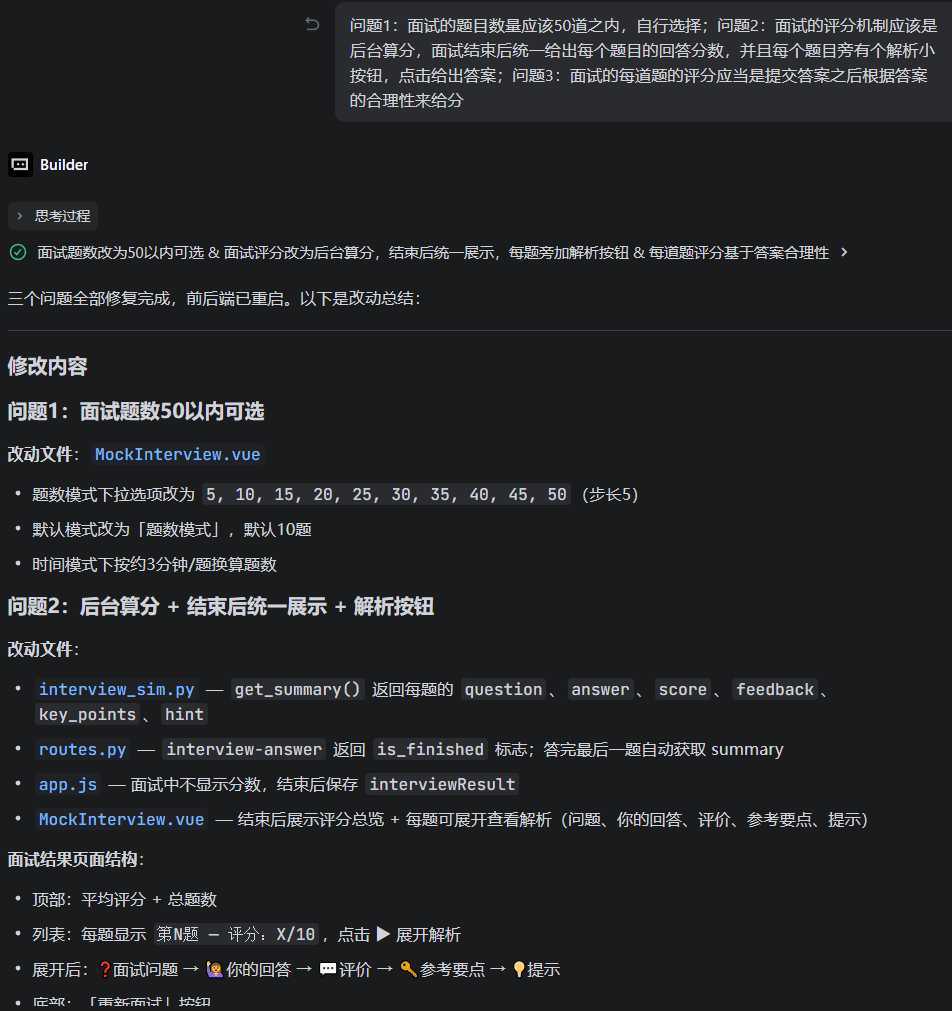
第一轮 — 增加模式选择和中断能力:
模拟面试应当由用户自行选择面试时间或者题数,并且可以中断面试
实现了 radio 按钮切换「题数模式 / 时间模式」,以及「结束面试」按钮。
第二轮 — 评分机制重构:
面试的评分机制应该是后台算分,面试结束后统一给出每道题目的回答分数
原来前端即时显示评分,改为后端在 LLM 返回时携带 score 字段,面试结束时通过 /stop-interview 接口一次性返回所有题目的分数、答案、评价和解析要点。前端增加「![]() 解析」按钮按需展开。
解析」按钮按需展开。
第三轮 — 题目多样性问题:
为什么每次面试的题目都一样?
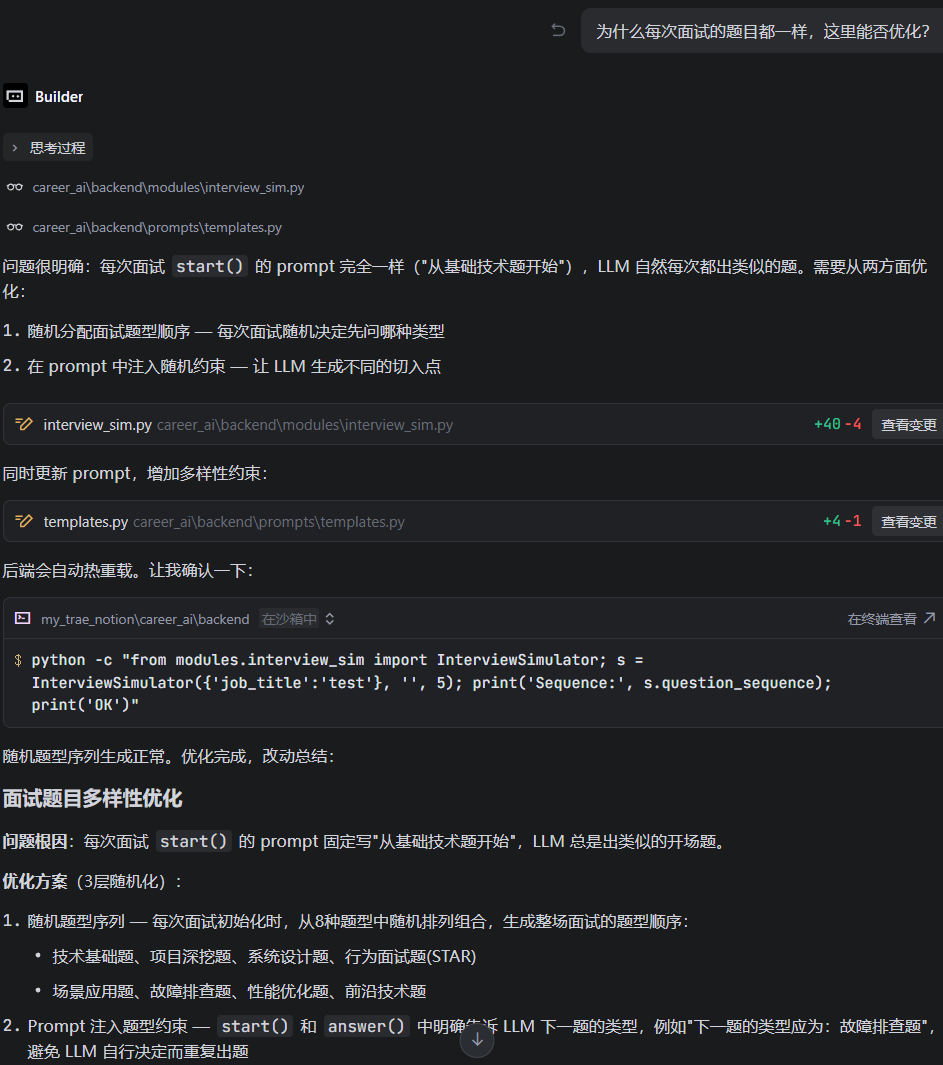
根因是 Prompt 固定 + temperature=0.3 太低。修复方案:
-
面试开始前随机生成题型序列(技术/行为/情景等),确保覆盖 ≥4 种类型
-
将 temperature 提升到 0.9
-
在 Prompt 中加入显式的多样性约束指令
 阶段三:单元测试驱动的问题发现
阶段三:单元测试驱动的问题发现
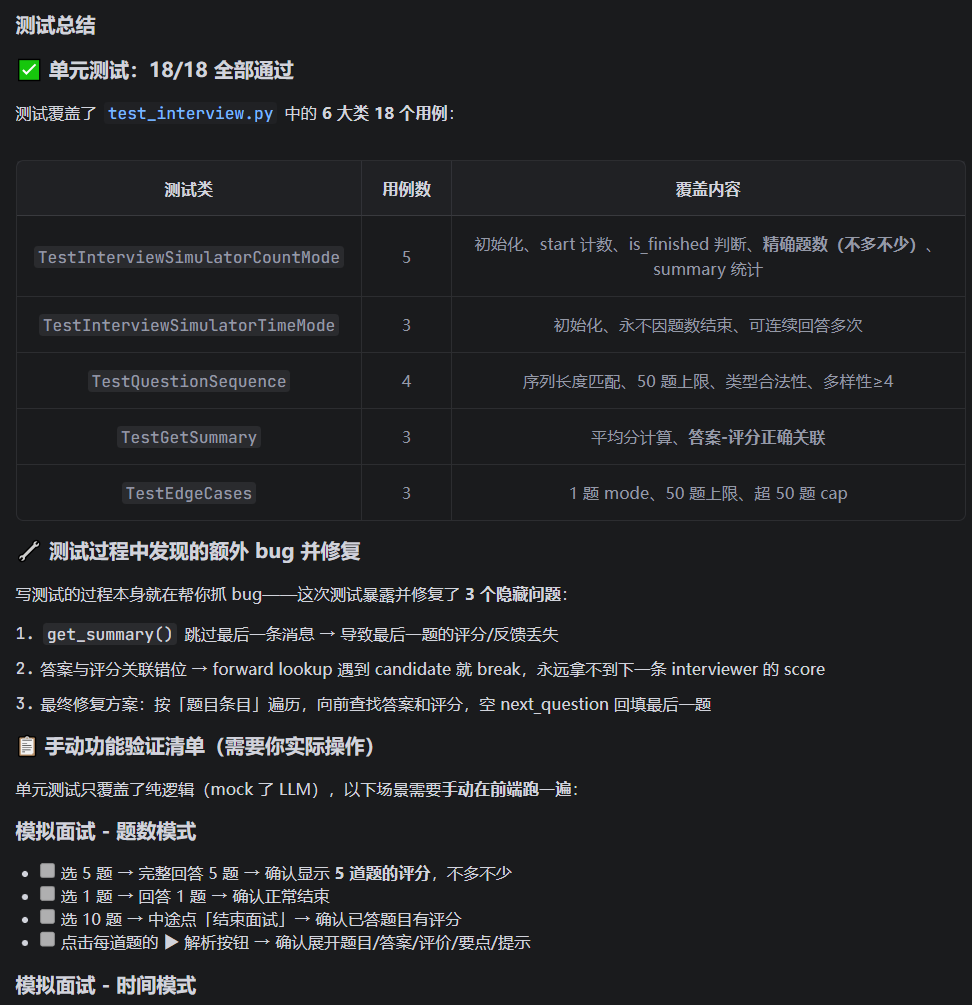
为 InterviewSimulator 编写了 18 个单元测试(pytest),覆盖:
-
题数模式的精确计数(不多不少)
-
时间模式永不因题数结束
-
题型序列的合法性和多样性
-
summary 中答案-评分的正确关联
测试过程中发现了隐藏 bug:
-
题数比预期多 1 — 最后一条 interviewer 消息(空 next_question + 有 score)被错误地计为一道新题。修复:跳过 next_question 为空的条目,将其 score 回填到上一题。
-
平均分计算错误 — forward lookup 遇到 candidate 消息就 break,永远拿不到下一条 interviewer 的 score。修复:先记录 answer,继续查找直到遇到 interviewer 消息才停止。
这两个 bug 在手动测试中很难察觉(需要精确对比题数),但单元测试一跑就暴露了。
 阶段四:Vercel 部署踩坑记
阶段四:Vercel 部署踩坑记
目标:免费部署,不需要信用卡。一开始选择了 Render(后端)+ Vercel(前端)方案。
坑 1:Render 需要信用卡验证。 我尝试了很多方式绕过验证,最后还是选择换一个托管服务
坑 2:Vercel Python runtime 配置格式。 先后报错:
-
"@vercel/python@3"→ “Function Runtimes must have a valid version” -
"python3.10"→ 同样的错误 -
最终方案:去掉 runtime 字段,只用
builds格式指定@vercel/pythonbuilder
坑 3:handler 导出格式。 报错 “Could not find a top-level handler”。从复杂的 ASGI adapter 手动路由(148 行代码),简化到最简形式:
# api/index.py - 最终版本仅 8 行
import sys, os
sys.path.insert(0, os.path.join(os.path.dirname(__file__), "..", "backend"))
from main import app
handler = app
坑 4:清理文件误删 requirements.txt。 导致 Vercel 构建时无法安装依赖,函数启动即崩溃 500。恢复根目录 requirements.txt 后解决。
Trae 使用的能力总结
| 能力 | 使用场景 |
|------|----------|
| 代码生成 | 全栈代码编写(FastAPI 路由/Vue 组件/Prompt 模板) |
| 代码搜索 | 快速定位 bug 相关代码(SearchCodebase/Grep) |
| Bug 诊断 | 分析错误日志、追踪调用链定位根因 |
| 文件操作 | 创建/编辑/删除配置文件、清理无用文件 |
| 终端命令 | Git 操作、npm/pip 安装、pytest 测试运行 |
| Web 搜索 | 查询 Vercel 部署文档、确认 runtime 格式规范 |
⑤ 成果展示
-
GitHub 仓库: https://github.com/sherlockers/career_ai
-
单元测试: 18/18 全部通过

-
代码量: 后端 ~1500 行 + 前端 ~1200 行
-
部署成本: Vercel 免费额度内(DeepSeek API按量付费)
⑥ 验证方式与下一步
当前验证:
-
18 个 pytest 单元测试全部通过,覆盖面试题数准确性、评分逻辑、边界条件
-
Vercel 线上部署成功,前后端均可正常访问
-
完整流程手动验证:JD 解码 → 差距分析 → 行动路线 → 模拟面试(含评分总结)→ 简历优化
已知限制 & 下一步计划:
| 项目 | 说明 |
|------|------|
| 会话存储 | 当前 interview_sessions 存内存,Serverless 冷启动会丢失(适合单次面试场景) |
| 多模型支持 | 目前仅支持 DeepSeek,可扩展 OpenAI/Qwen 等兼容接口 |
| 用户系统 | 无登录/历史记录功能,后续可接入数据库持久化 |
| 面试题库 | 考虑引入真实面试题库作为 seed,减少对 LLM 生成的完全依赖 |