摘要
利用 SOLO AI 编程助手在三天内完成了基于 VNP46A2 夜光数据的 GNN 图构建方案实验与选型。通过五套不同图结构方案的对比实验,最终确定了最优技术路线,实现了约 11 倍的开发效率提升。
背景
我是一名科研人员,研究方向为遥感与深度学习交叉领域,。日常工作中需要反复进行图结构构建算法开发、模型训练调优、多方案对比实验等,涉及大量代码编写与调试,原本耗时较长,希望用 SOLO 提效。
实践过程
一、实践过程
我将 NTL-GNN 夜间灯光数据缺失值填补系统开发拆解为以下阶段:
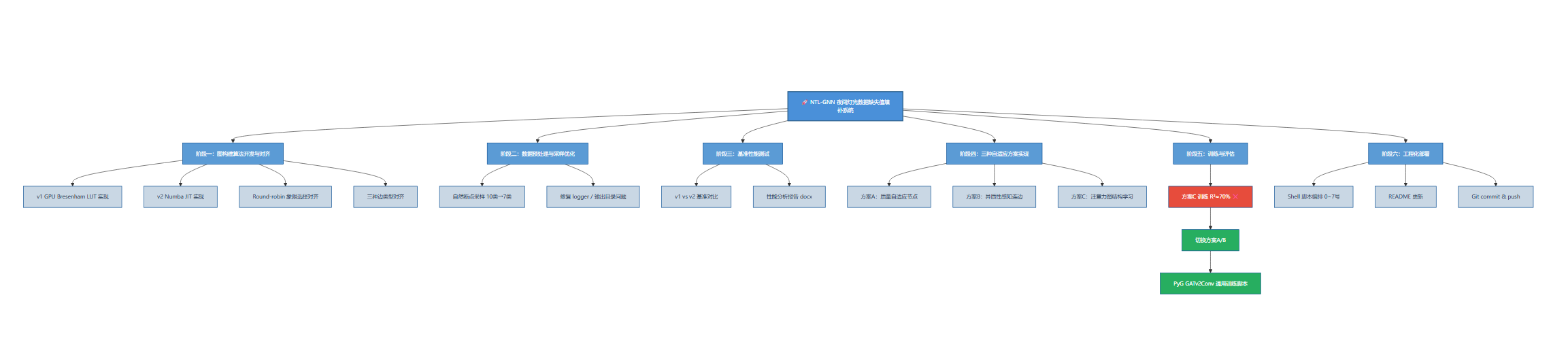
flowchart TD
A["🚀 NTL-GNN 夜间灯光数据缺失值填补系统"] --> B["阶段一:图构建算法开发与对齐"]
A --> C["阶段二:数据预处理与采样优化"]
A --> D["阶段三:基准性能测试"]
A --> E["阶段四:三种自适应方案实现"]
A --> F["阶段五:训练与评估"]
A --> G["阶段六:工程化部署"]
B --> B1["v1 GPU Bresenham LUT 实现"]
B --> B2["v2 Numba JIT 实现"]
B --> B3["Round-robin 象限选择对齐"]
B --> B4["三种边类型对齐"]
C --> C1["自然断点采样 10类→7类"]
C --> C2["修复 logger / 输出目录问题"]
D --> D1["v1 vs v2 基准对比"]
D --> D2["性能分析报告 docx"]
E --> E1["方案A:质量自适应节点"]
E --> E2["方案B:异质性感知连边"]
E --> E3["方案C:注意力图结构学习"]
F --> F1["方案C 训练 R²≈70% ❌"]
F1 --> F2["切换方案A/B"]
F2 --> F3["PyG GATv2Conv 通用训练脚本"]
G --> G1["Shell 脚本编排 0~7号"]
G --> G2["README 更新"]
G --> G3["Git commit & push"]
style A fill:#4A90D9,color:#fff,stroke:#2C5F8A,stroke-width:2px
style B fill:#5B9BD5,color:#fff
style C fill:#5B9BD5,color:#fff
style D fill:#5B9BD5,color:#fff
style E fill:#5B9BD5,color:#fff
style F fill:#5B9BD5,color:#fff
style G fill:#5B9BD5,color:#fff
style F1 fill:#E74C3C,color:#fff
style F2 fill:#27AE60,color:#fff
style F3 fill:#27AE60,color:#fff
阶段一:图构建算法开发与对齐
- v1(GPU Bresenham LUT)与 v2(Numba JIT)两种图构建器的实现
- Round-robin 象限选择、三种边类型等核心算法对齐
阶段二:数据预处理与采样优化
- 自然断点采样从 10 类合并为 7 类(>0.1 合并为一类)
- 修复 logger 未定义、输出目录不存在等工程问题。
阶段三:基准性能测试
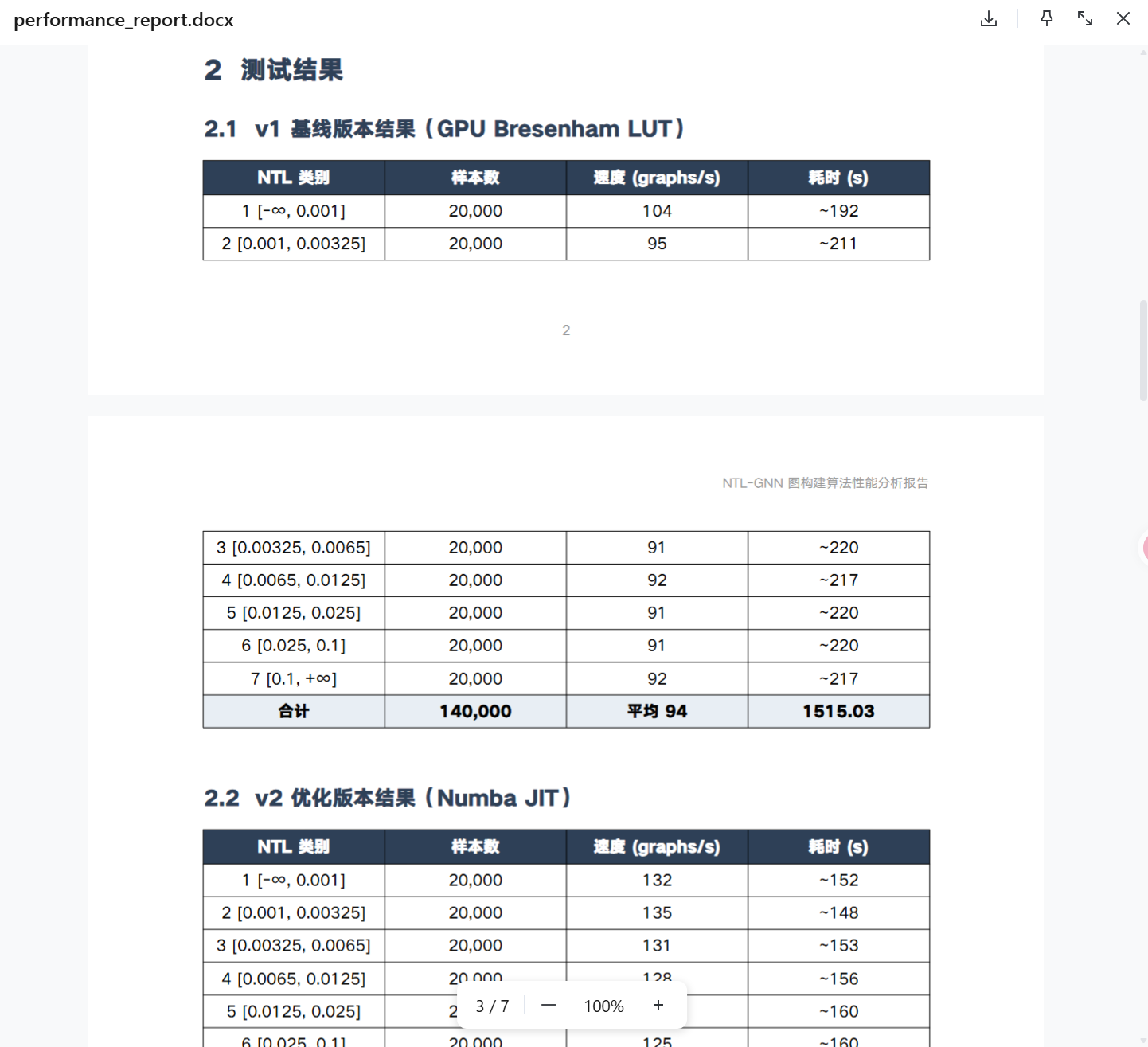
- v1 vs v2 基准对比(1515s vs 1101s,1.376x 加速)
- 生成性能分析报告(docx),SOLO可以直接使用 docx 技能生成指定字体和格式的内容,如果老板对格式有要求,这个能力真的帮了很大忙。
阶段四:三种自适应方案实现
- 方案A:质量驱动的自适应节点数
- 方案B:空间异质性感知的动态连边
- 方案C:注意力图结构学习
阶段五:训练与评估
- 方案C 完整训练(R² ≈ 70%,未达论文 90% 目标),也就是当前给出的几个优化思路无法提升缺失值填补的性能
- 转向方案 A/B,使用 PyG GATv2Conv 通用训练脚本
阶段六:工程化部署
- Shell 脚本编排、README 更新、Git 推送
二、使用的 SOLO 能力
| 能力 | 应用场景 |
|---|---|
| 代码生成 | 图构建器、GNN 模型、训练脚本的完整 Python 模块 |
| 错误诊断与修复 | 张量维度广播、CUDA 索引越界、模块导入路径等 |
| 文档生成(docx 技能) | 性能分析报告自动生成,格式规范 |
| Shell 脚本编排 | 7 个部署脚本,覆盖完整实验流程 |
| Git 版本管理 | 自动 commit + push |
| TodoList 任务追踪 | 多阶段任务的进度管理 |
三、踩坑记录
坑①:网页版 SOLO 直连服务器
在服务器上运行训练任务时,遇到报错需要反复在本地 SOLO 和服务器终端之间切换,效率较低。
影响:每次修复都需要手动复制代码到服务器、运行、再复制报错回来,一轮至少 2-3 分钟。
坑②:错误修复无法一次正确
典型场景:PyTorch 3D/4D 张量广播问题,同一个 unsqueeze 类型的错误反复出现 3 次。
第一次:att_src (1,heads,head_dim) × h (B,heads,N,head_dim) → 添加 unsqueeze(2)
第二次:att_bias (1,heads,1) 同样问题 → 再次添加 unsqueeze(2)
第三次:h * attn.unsqueeze(-1) 产生 5D 张量 → 改用 torch.matmul
虽然多轮对话最终都能解决,但无法一次定位所有同类问题,需要"打地鼠"式逐个修复。
效果与总结
在本项目中,我使用 SOLO 完成了 NTL-GNN 夜间灯光数据缺失值填补系统的核心开发工作,包括图构建算法的对齐与优化、三种自适应图结构改进方案(质量自适应节点、异质性感知连边、注意力图结构学习)的设计与实现,以及完整的训练与评估流程搭建。原本这类从算法设计、代码编写、调试到实验对比的完整链路,通常需要数周时间反复迭代,而在 SOLO 的辅助下,整个开发周期大幅缩短,许多原本需要手动排查数小时的问题(如 PyTorch 张量维度广播错误、模块导入路径问题等)能够在几分钟内定位并修复。
SOLO 在我的工作流程中承担了多个关键角色:首先是代码生成与重构,能够根据我对算法的描述快速生成完整的 Python 模块,包括图构建器、GNN 模型、训练脚本等;其次是错误诊断与修复,面对运行时报错(如 CUDA 索越界、3D/4D 张量广播不匹配、DataLoader collate 类型错误等),SOLO 能精准定位问题根源并给出修复方案;此外还包括项目工程化管理,如自动编写部署脚本、生成性能分析报告、维护 README 文档以及 Git 版本管理等。整个过程中,我只需要提供算法思路和报错信息,SOLO 便能完成从编码到调试再到提交的闭环。
从可复用的方法论来看,我认为最有效的协作模式是:将复杂任务拆解为图构建、模型训练、方案对比等独立阶段,每完成一个阶段就进行验证,避免错误累积。同时,将 Python 逻辑与 Shell 脚本分离、保持模块间接口清晰、使用统一的配置管理,这些工程实践在 SOLO 辅助下更容易贯彻。