背景介绍
由于需要将一些历史记录进行入库,用于形成信息化数据和数字化分析用途,但以往的历史记录大多以word文档或pdf文档形式存在,所以需要进行以下步骤:
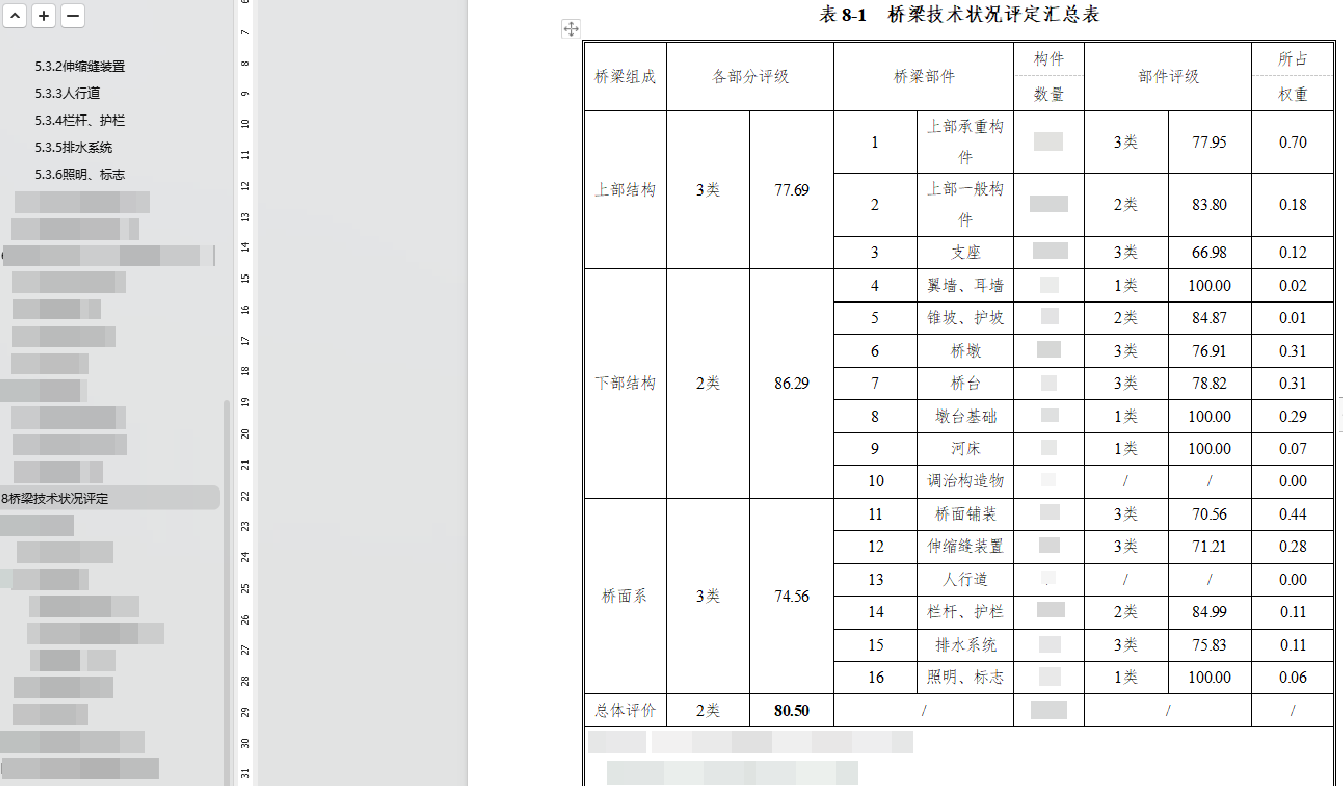
- 将文档中的病害记录表提取到Excel中
- 将多个文档的提取到的表合并到一个Excel中
- 每条数据需要标注来源文档,方便问题溯源

SOLO实操
上传文档并发送指令
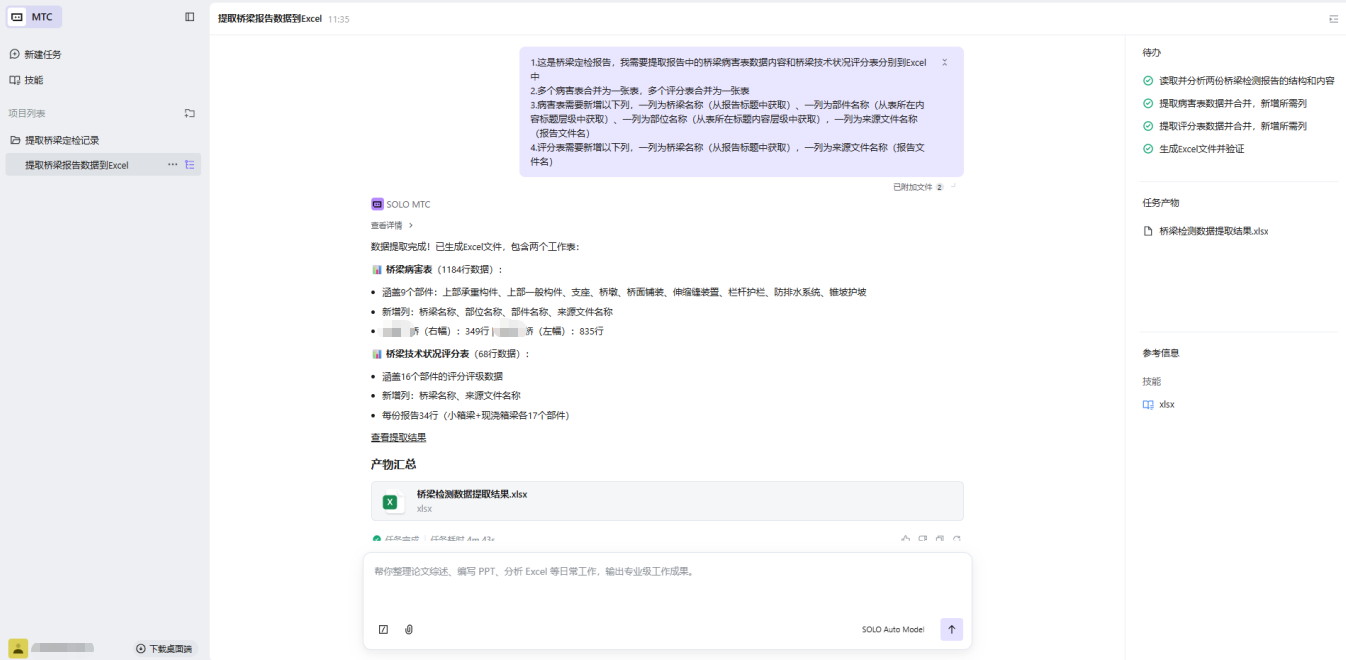
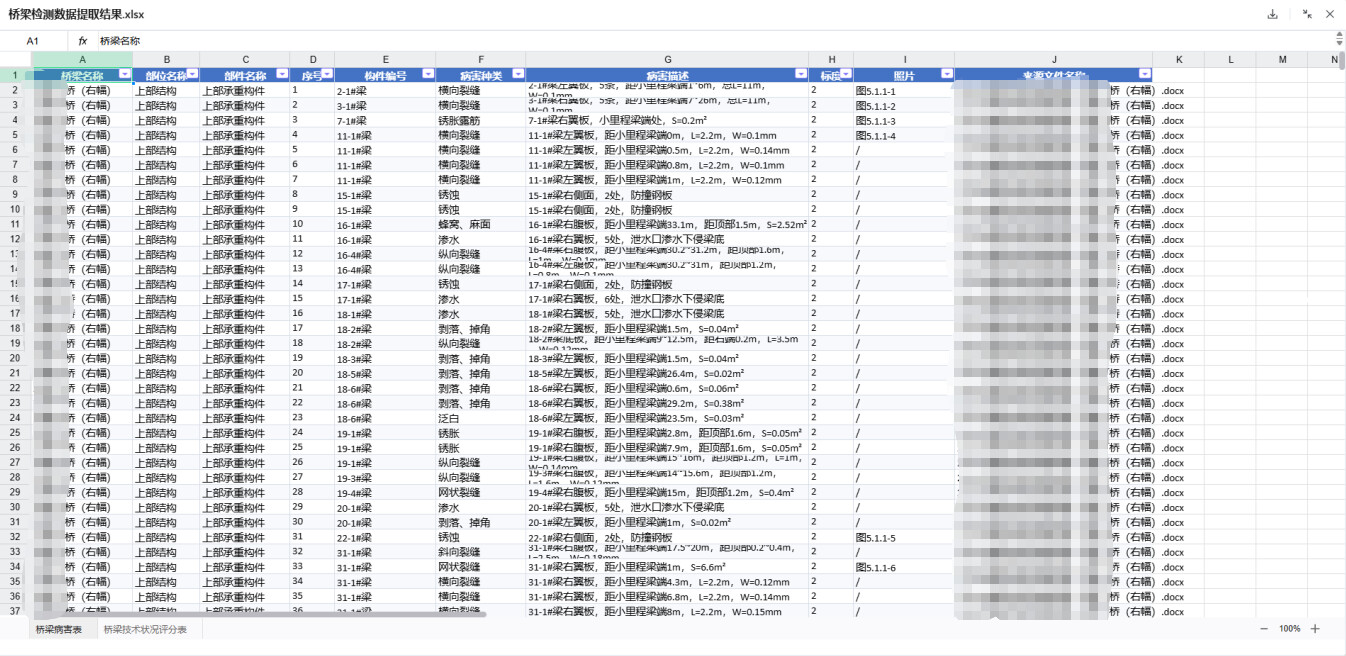
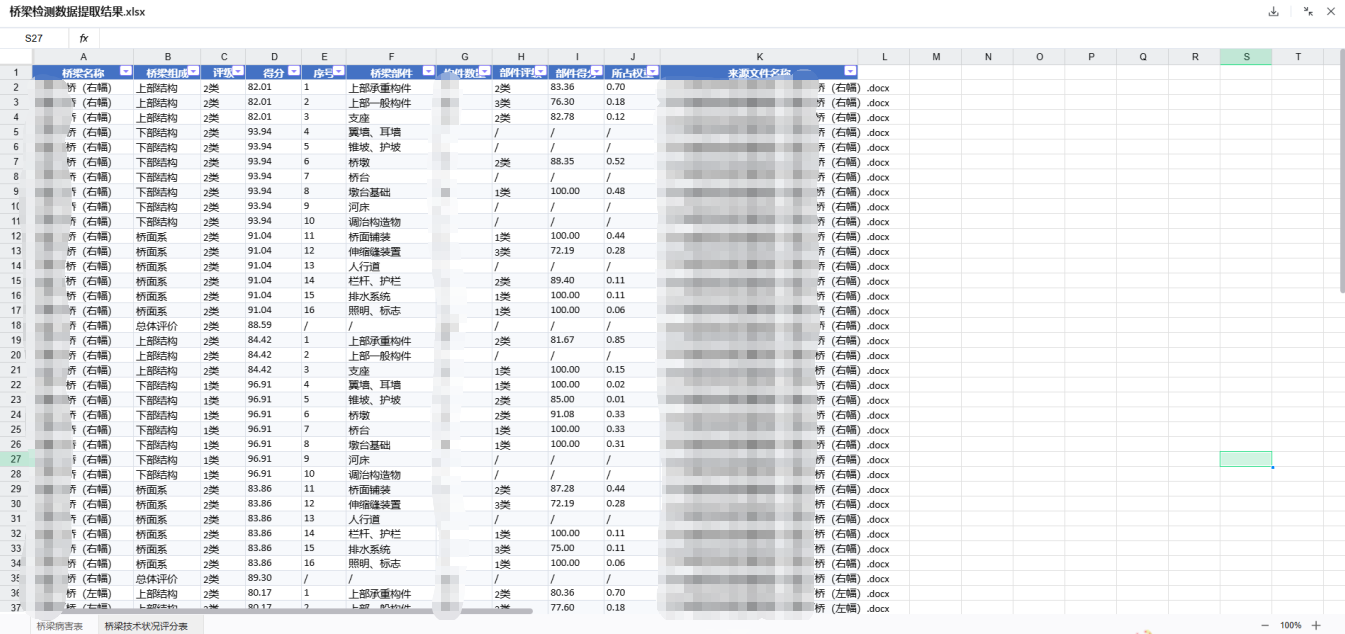
查看结果
原先使用TRAE IDE时的做法
1.编写从文档中提取数据表的程序并批量多个文档中的所有表格
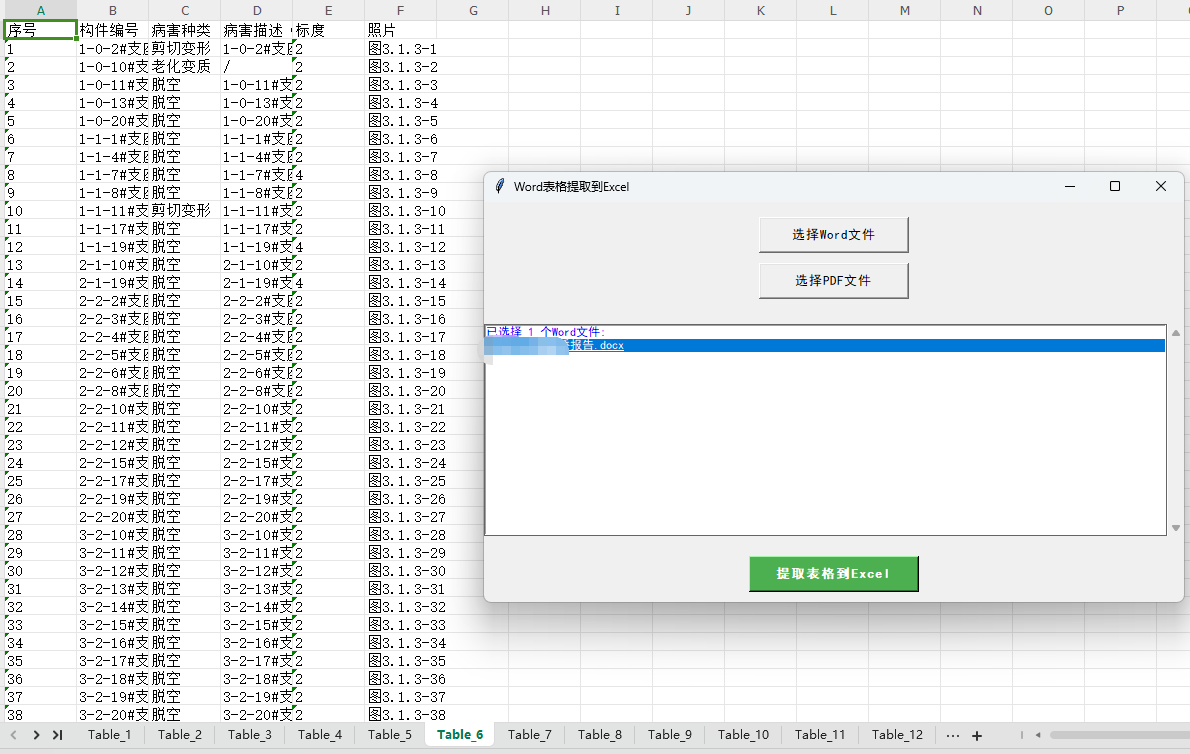
2.再编写一个程序,将已经提取的所有表格的表头字段扫描出来,然后在进行筛选提取,同时相同表头也做了合并处理
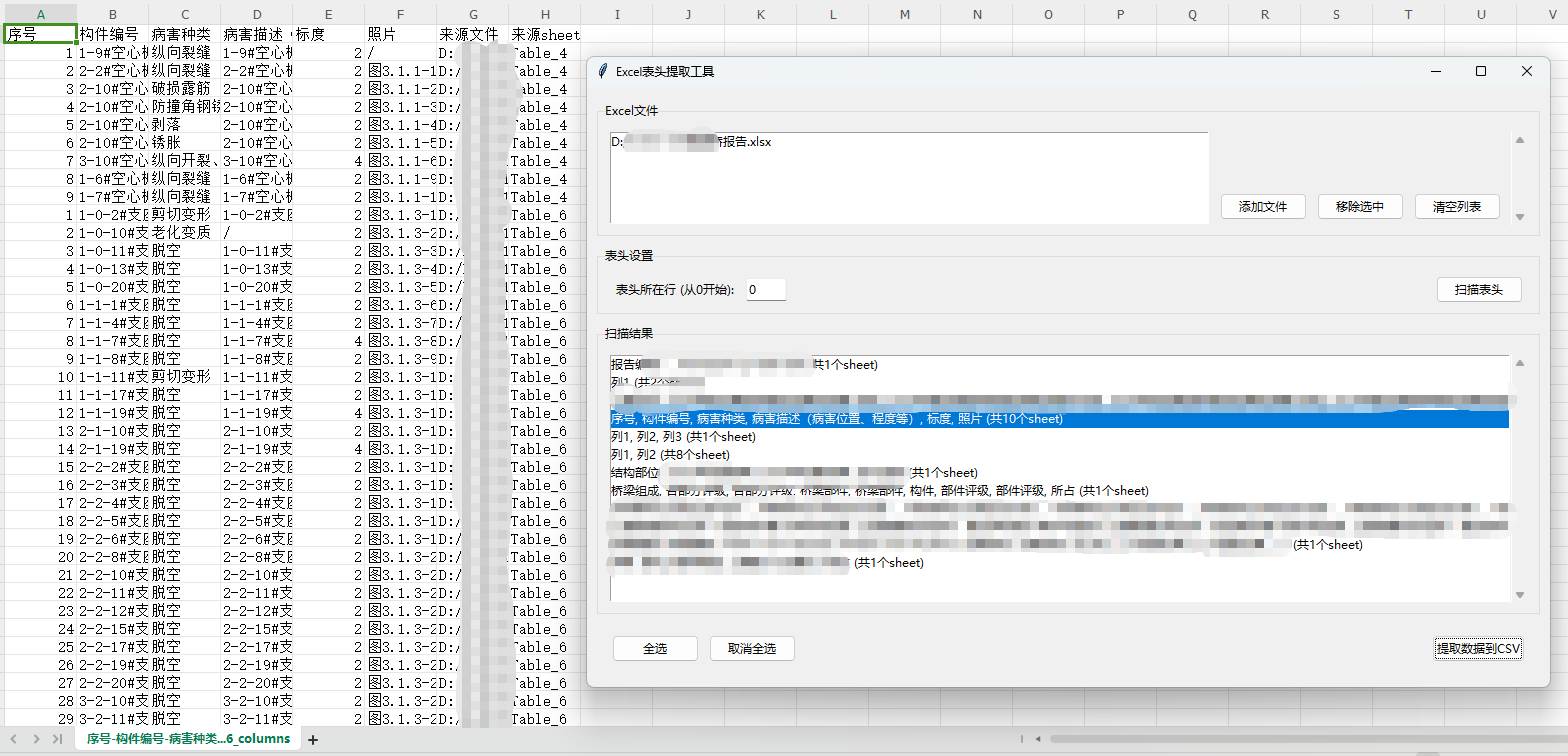
最终得到结果,再手动进行相应的处理
后记
- 使用SOLO的MTC模式后可以直接描述预期结果不用思考并人为拆解步骤,可一次性完成的比较理想
- 在实际的操作过程中还有更复杂的情况,如不是每个文档结构和表头都完全一样,人眼虽然很容易分别但不清楚如何知道AI完成这项纠错的动作;再比如对于PDF的表格提取会出现跨页空行的情况,不如word提取表格的完整有效;还有多桥一个文档时标注表格获取来源桥梁的问题等等。这种人工进行识别很容易但量太大交给AI右不知从何做起。
- 还没试如果处理上百个文档的批量处理是否能够顺利进行,或许封装成一个程序可能更合适?
- 在MTC模式下把已经从需求到实现结果的这个实践过程如何快速的形成一个有输入输出的工具还不清楚有没有一键封装的方法,还需再研究研究