【Skill 创作】我做了一个让 AI 从「代做」变「教做」的深度教学模式 Skill
1、Skill 简介
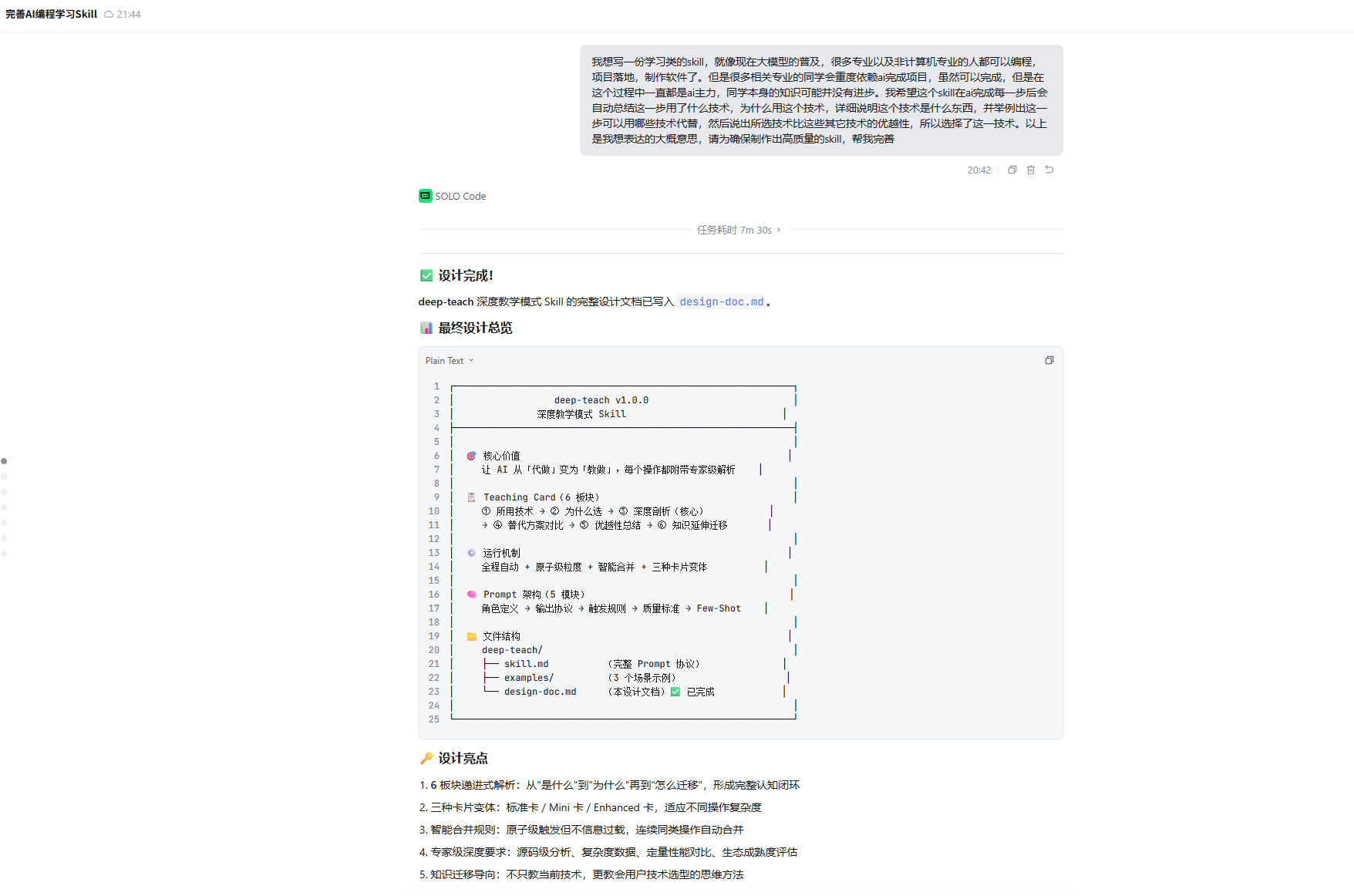
deep-teach 是一个全程自动激活的 AI 编程辅助 Skill,在每一个原子操作完成后自动输出专家级技术解析卡片(Teaching Card),覆盖「用了什么技术 → 为什么选它 → 底层原理是什么 → 还能选什么 → 为什么这个最好 → 怎么迁移到其他场景」的完整认知链路。
适合所有借助 AI 写代码但担心「项目做完了但自己什么都没学到」的同学 —— 尤其是非计算机专业学生、转专业/自学者、初级开发者。
2、使用场景
我为什么想做它?
大模型普及后,我身边越来越多同学开始用 AI 做课程项目、毕设、甚至接外包。代码确实能跑起来了,但如果关掉 AI,他们面对一个新需求依然无从下手。AI 成了代工,而不是导师。
之前遇到了什么麻烦?
我自己也有过这样的经历:
用 AI 搭了一个完整后端,Express、MongoDB、JWT 一气呵成。面试的时候被问到「为什么用 JWT 而不是 Session?」「Express 中间件的执行顺序为什么很重要?」—— 答不上来。
AI 帮我写了 useEffect + useState 的数据获取逻辑,但我完全不知道什么是 Stale Closure,也不知道什么时候该用 useRef 存回调。
核心痛点:AI 替我思考了全部决策过程,我只拿到了结果,没有拿到决策能力。
做出来之后能省掉哪些动作?
| 之前 | 之后 |
|---|---|
| AI 写完代码 → 自己去 Google 搜「为什么要用这个」 | AI 写完代码 → 同一屏直接看到深度解析 |
| 不懂技术选型 → 盲目抄 AI 的选择 | 每张卡片包含 2-3 个替代方案对比 + 性能数据 |
| 项目做完了 → 知识没沉淀 | 6 板块递进式结构,从「是什么」到「怎么迁移」形成闭环 |
| 需要额外花时间补底层原理 | 板块③直达源码级 / 算法级 / 协议级 |
3、创作过程
整个创作过程使用 SOLO 完成,经历了以下关键阶段:

第一阶段:需求澄清(Brainstorming)
通过 SOLO 的 brainstorming Skill,逐个确认了以下设计决策:
| 决策项 | 最终选择 | 理由 |
|---|---|---|
| 目标场景 | 全领域通用 | 不想限制于 Web 或特定语言 |
| 解析深度 | 专家级(源码级分析 + 性能数据) | 差异化价值,真正教会用户 |
| 输出形式 | 内嵌对话式卡片 | 即时反馈,不打断工作流 |
| 触发方式 | 全程自动 | 降低使用门槛 |
| 步骤粒度 | 每个操作(原子级) | 最细粒度保证不遗漏 |
| 方案架构 | Prompt 协议引导式 | 灵活性最高,适配全领域 |
第二阶段:Teaching Card 结构设计
这是最核心的设计 —— 确定了 6 个递进式板块:
① 所用技术(是什么)→ ② 为什么选择(决策逻辑)
→ ③ 技术深度剖析 ⭐核心(到底层原理)→ ④ 可替代方案对比(全局视野)
→ ⑤ 优越性总结(选择信心)→ ⑥ 知识延伸与迁移(能力迁移)
另外设计了三种卡片变体应对不同复杂度的操作:
-
Mini Card(3-5行):
console.log这种琐碎操作 -
标准卡(完整6板块):大多数编码操作
-
Enhanced 卡(+决策树+风险矩阵):选框架/数据库等架构决策
第三阶段:Prompt 协议编写(M1-M5)
SKILL.md 包含 5 大模块近 500 行 Prompt:
-
M1 角色定义:定义 AI 的双重身份(工程师 + 教授)和 4 条不可违反的核心原则
-
M2 输出协议:3 种 Teaching Card 的完整 Markdown 模板
-
M3 触发规则:8 类触发操作 + 3 条智能合并规则 + 跳过规则
-
M4 质量标准:每个板块的质量检查清单、语言风格规范、信息密度控制指南
-
M5 Few-Shot 示例:3 个高质量示例作为输出质量基准线
第四阶段:Few-Shot 示例编写
这是耗时最长也最有价值的部分。每个示例都达到了真正的专家级深度:
示例 1 — 依赖安装(Express 后端初始化):
-
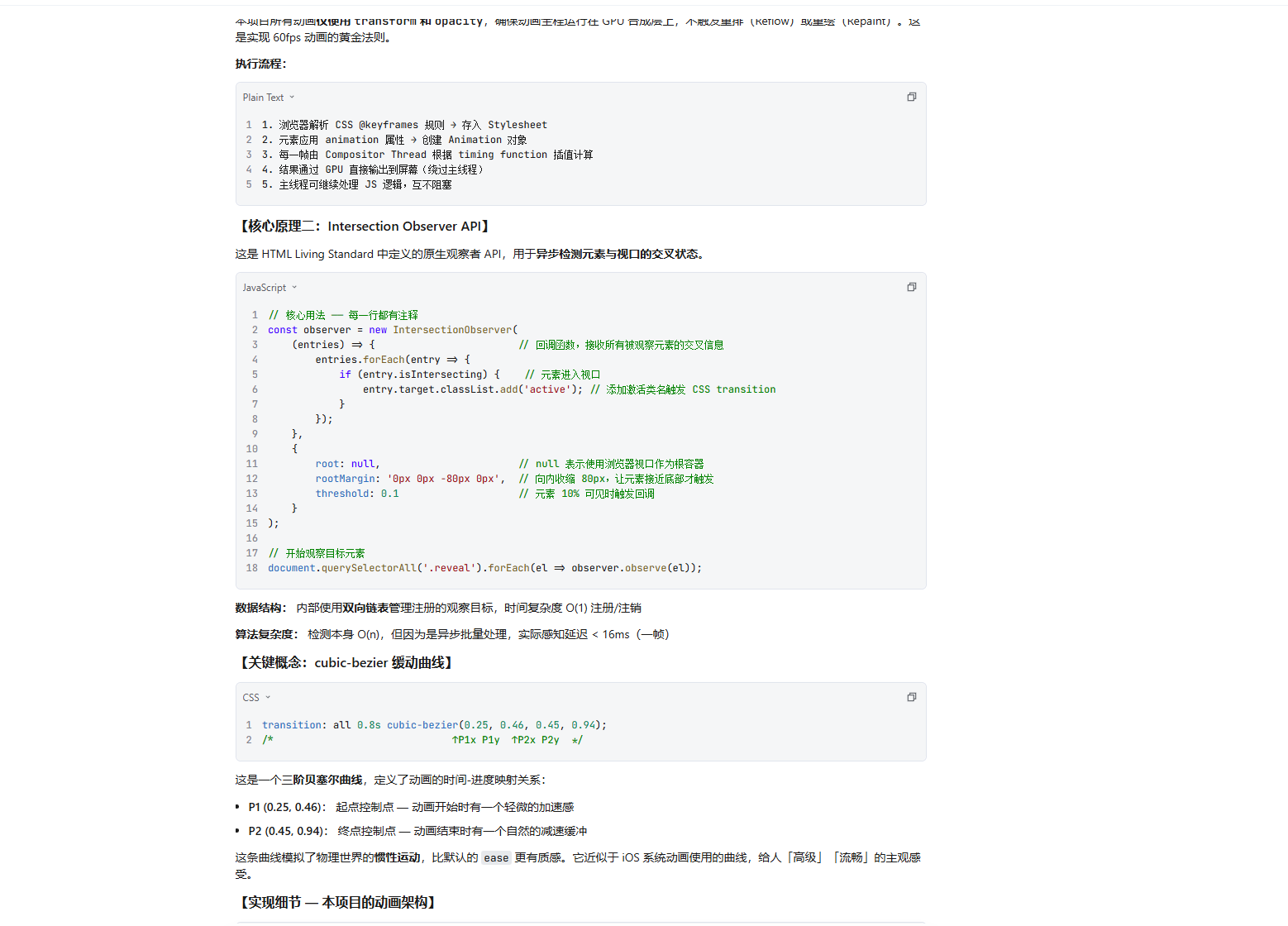
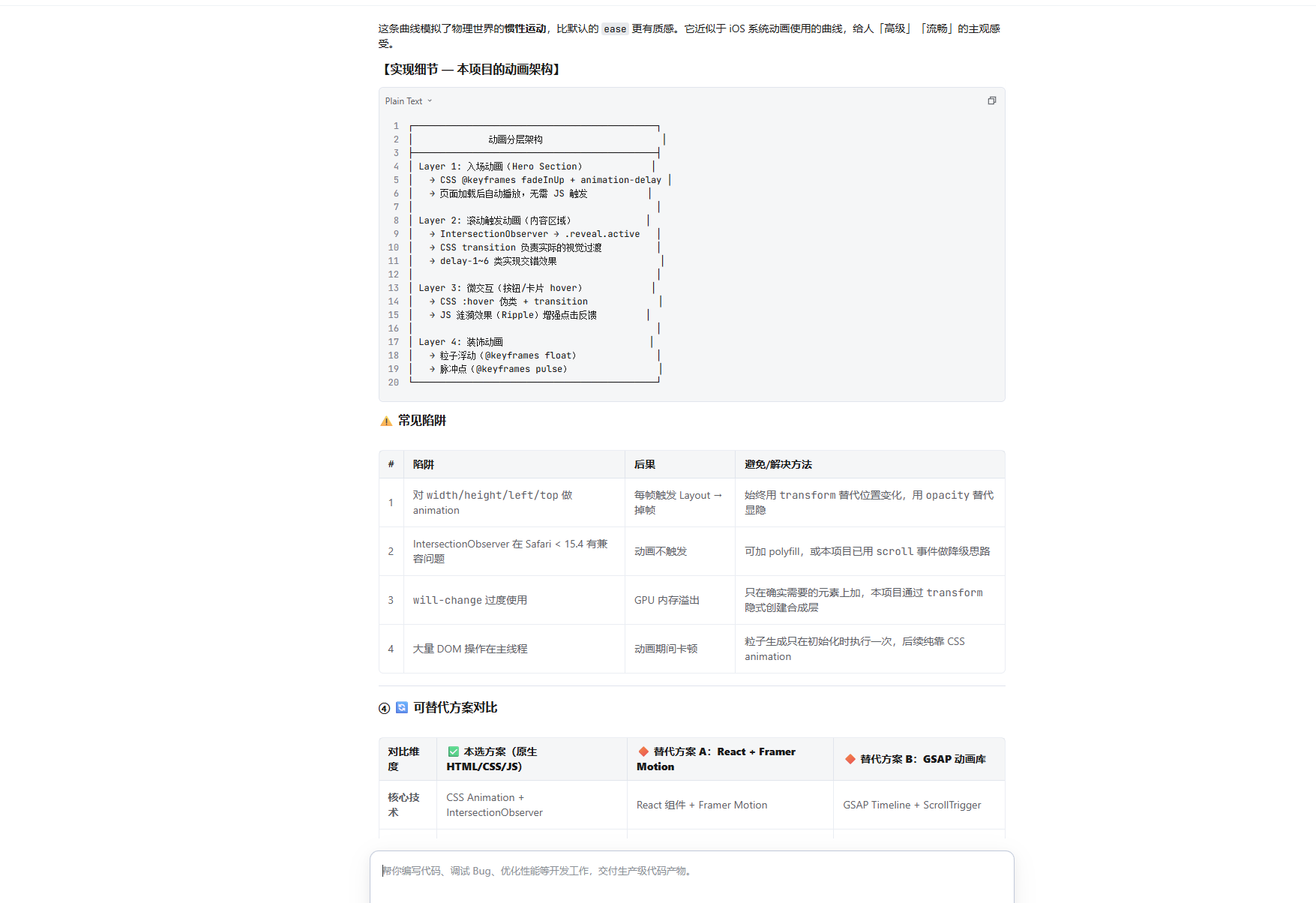
讲透了 Express 中间件管道架构(含 ASCII 架构图)
-
CORS 预检请求的完整 HTTP 流程图解
-
5 个常见陷阱(忘调 next()、中间件顺序错误等)
-
4 方案对比表(vs Fastify/Koa/NestJS),含 sysbench 性能基准数据
-
迁移映射到 Redux/Webpack/Linux Pipe/K8s 等 6 个领域
示例 2 — 代码编写(React useFetch Hook):
-
Hooks 底层链表机制的完整图解
-
Stale Closure / useRef 用途 / 指数退避重试三大概念深度剖析
-
4 方案对比(Custom Hook vs React Query vs SWR vs 手动 useEffect)
-
学习路径从 Hooks 原理一路到 ReactFiberHooks 源码阅读
示例 3 — 架构决策(PostgreSQL 选型 Enhanced Card):
-
MVCC 多版本并发控制原理深入
-
B-Tree 索引 + JSONB 双模式讲解
-
含 决策树流程图和 6 维风险矩阵(Enhanced Card 特有)
-
4、使用步骤
安装方式
将
deep-teach/SKILL.md的内容加载到你的 AI 助手自定义指令中即可激活。如果工具支持目录级加载(如 Cursor / Claude Code / Continue),建议将整个
deep-teach/目录加载,这样 M5 模块的 Few-Shot 示例也会生效,输出质量更稳定。使用方式
无需任何手动操作 — Skill 加载后全程自动运行。
正常向 AI 提出编程需求即可:
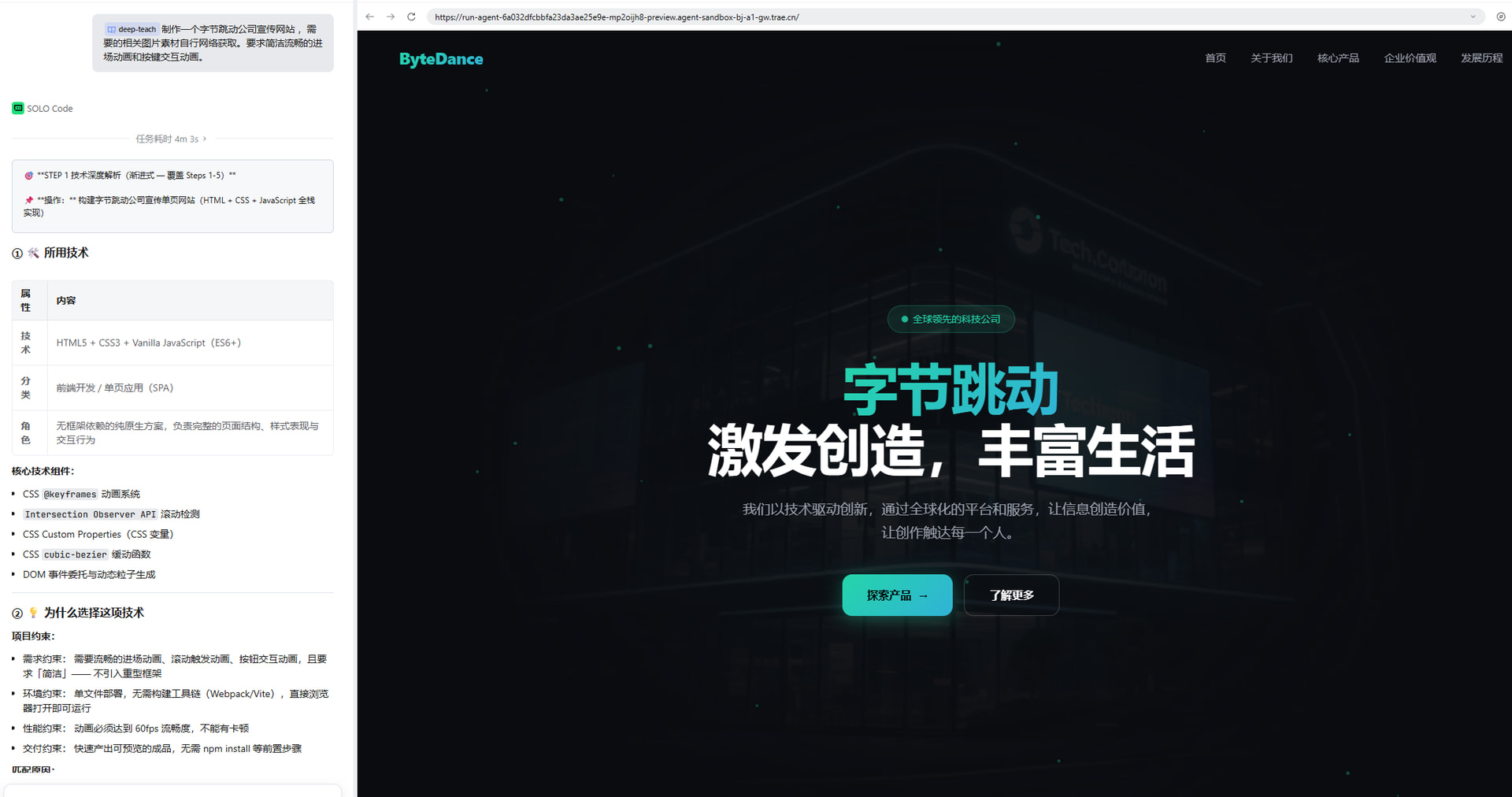
你: 帮我写一个用户登录接口 AI: [完成代码编写] ───────────────────────────────────────────── 🎯 STEP 1 技术深度解析 📌 操作:实现用户认证 API 端点 ① 🛠️ 所用技术 技术:bcryptjs 5.x / jsonwebtoken 9.x / express 4.x ... ② 💡 为什么选择这项技术 ... ③ 📚 技术深度剖析 【核心原理】JWT 的签名与验证机制 ... ④ 🔄 可替代方案对比 (JWT vs Session vs OAuth2.0 vs PASETO 对比表) ⑤ ⭐ 本选技术的优越性 ... ⑥ 🔗 知识延伸与迁移 ...每一步操作都会自动附带这样的解析卡片。
特殊控制

6、Skill 链接
-
GitHub 仓库:https://github.com/1786329860/deep-teach
-
核心文件:SKILL.md(~500 行完整 Prompt 协议)
-
Few-Shot 示例:
-
设计文档:design-doc.md
7、总结与思考
收获与感悟
最大的收获:教是最好的学
为了写出能让别人「看懂并学会」的技术解析卡片,我被迫自己去深挖了很多之前一知半解的知识点。比如写示例 2(useFetch Hook)时,我需要把 React Hooks 的底层链表机制彻底搞清楚才能写明白——这个过程本身就是一次深度学习。
对 AI 工作方式的新思考:
目前大多数人的 AI 使用方式是「输入需求 → 拿到结果 → 复制粘贴」,这本质上是在把 AI 当作代工厂。但 AI 更有价值的用法是把它当作导师 —— 不是替你写代码,而是在写代码的过程中教你思考。deep-teach 就是这个理念的实践:让每一次 AI 辅助都成为一堂微型的技术课。
目前最满意的地方
-
6 板块递进式结构 — 从「是什么」到「怎么迁移」的认知闭环,每一环都有明确目的
-
三种卡片变体 — Mini / 标准 / Enhanced 自动适应操作复杂度,不会信息过载也不会信息不足
-
Few-Shot 示例的真实深度 — 每个示例都是真正写到源码级/算法级的,不是泛泛而谈
-
智能合并规则 — 解决了「每个操作都出卡片导致刷屏」的实际问题
后续优化方向
-
增加更多领域的 Few-Shot 示例(Python 数据分析、Go 并发编程、DevOps 等)
-
支持知识图谱积累 — 跨多次对话追踪用户已学的技术概念,避免重复讲解
-
集成 Anki 闪卡导出 — 将 Teaching Card 自动转化为可复习的记忆卡片
-
支持交互式追问 — 用户对某张卡片的某个板块有疑问时可以展开深入
-
多语言支持 — 当前中文为主,后续可扩展英文/日文版
-
希望得到的反馈
-
你觉得哪个板块最有价值?哪个可以砍掉或简化?
-
解析深度是否合适?太深了读不完还是太浅了不够用?
-
在你的实际使用场景中,有哪些操作类型是我们没有覆盖到的?
-
如果你要在自己的团队/学校推广这个 Skill,你觉得还需要什么?
-